2021SC@SDUSC
研究内容简略介绍
上周我们分析了org.apache.hadoop.mapreduce.Job中的的剩余代码,本周将开始对
org.apache.hadoop.mapreduce.Cluster
进行分析。

hadoop.mapreduce.Cluster源码文件
Cluster构造方法
先来看下Cluster类的成员信息。
package org.apache.hadoop.mapreduce;
import ...
/**
* Provides a way to access information about the map/reduce cluster.
*/
@InterfaceAudience.Public
@InterfaceStability.Evolving
public class Cluster {
@InterfaceStability.Evolving
public static enum JobTrackerStatus {INITIALIZING, RUNNING};
private ClientProtocolProvider clientProtocolProvider; //客户端通信协议提供者
private ClientProtocol client; //客户端通信协议实例
private UserGroupInformation ugi; //用户组信息
private Configuration conf; //配置信息
private FileSystem fs = null; //文件系统实例
private Path sysDir = null; //系统路径
private Path stagingAreaDir = null; //作业资源存放路径
private Path jobHistoryDir = null; //作业历史路径
private static final Log LOG = LogFactory.getLog(Cluster.class); //日志
//客户端通信协议提供者加载器
private static ServiceLoader<ClientProtocolProvider> frameworkLoader =
ServiceLoader.load(ClientProtocolProvider.class);
static {
ConfigUtil.loadResources();
}
public Cluster(Configuration conf) throws IOException {
this(null, conf);
}
public Cluster(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
this.conf = conf; //设置配置信息
this.ugi = UserGroupInformation.getCurrentUser(); //获取当前用户
initialize(jobTrackAddr, conf); //完成初始化
}
...
}
官方在源码的开头给出了对cluster类的粗略注释
Provides a way to access information about the map/reduce cluster.
也就是说这个类为我们提供了对map/reduce集群获取信息的方法。
Cluster最重要的两个成员变量是客户端通信协议提供者ClientProtocolProvider实例clientProtocolProvider和客户端通信协议
ClientProtocol实例client,而后者是依托前者的create()方法生成的。
Cluster类提供了两个构造函数。
public Cluster(Configuration conf)
需要传入参数为Configuration 类的对象,我们将在稍后介绍Configuration 的相关信息。这里面的conf,返回的就是各种${HADOOP_HOME}/etc/hadoop里面的配置文件,最后是以XML的集合形式存放。
第二个构造方法
public Cluster(InetSocketAddress jobTrackAddr, Configuration conf)
额外需要一个InetSocketAddress类对象作为参数传入,查询官方api可知,公共类InetSocketAddress扩展了类SocketAddress。这个类实现了一个IP Socket Address(IP地址+端口号),也可以是一对(主机名+端口号),在这种情况下会尝试解析主机名。如果解析失败,则该地址被称为未解析,但仍可在某些情况下使用,例如通过代理连接。它提供了一个由套接字用于绑定、连接或作为返回值的不可变对象。
两个方法的区别在于第二种构造方法除了为集群设置配置信息外,还能够获取当前用户,并借助jobTrackAddr完成初始化—初始化了集群的信息,包括配置文件。
方法initProviderList
private void initProviderList() {
if (providerList == null) {
synchronized (frameworkLoader) {
if (providerList == null) {
List<ClientProtocolProvider> localProviderList =
new ArrayList<ClientProtocolProvider>();
try {
for (ClientProtocolProvider provider : frameworkLoader) {
localProviderList.add(provider);
}
} catch(ServiceConfigurationError e) {
LOG.info("Failed to instantiate ClientProtocolProvider, please "
+ "check the /META-INF/services/org.apache."
+ "hadoop.mapreduce.protocol.ClientProtocolProvider "
+ "files on the classpath", e);
}
providerList = localProviderList;
}
}
}
}
initProviderList负责初始化cluster的基本信息。
代码第四行判断用户是否提交配置信息,如果没有提交,则下面开始初始化LocalProviderList,这也就是如果本地测试运行时,clientProtocol为什么会返回
org.apache.hadoop.LocalJobRunner@XXX
的原因。首先初始化一个数组,遍历ClientProtocolProvider ,依次存入数组localProviderList中,若产生异常,则抛出具体错误信息。
当然,若providerList有东西,说明是提交到集群上,并且拿到了相关配置信息,我们就可以直接退出这个方法了。
方法initialize
private void initialize(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
initProviderList();
final IOException initEx = new IOException(
"Cannot initialize Cluster. Please check your configuration for "
+ MRConfig.FRAMEWORK_NAME
+ " and the correspond server addresses.");
if (jobTrackAddr != null) {
LOG.info(
"Initializing cluster for Job Tracker=" + jobTrackAddr.toString());
}
for (ClientProtocolProvider provider : providerList) {
LOG.debug("Trying ClientProtocolProvider : "
+ provider.getClass().getName());
ClientProtocol clientProtocol = null;
try {
if (jobTrackAddr == null) {
clientProtocol = provider.create(conf);
} else {
clientProtocol = provider.create(jobTrackAddr, conf);
}
if (clientProtocol != null) {
clientProtocolProvider = provider;
client = clientProtocol;
LOG.debug("Picked " + provider.getClass().getName()
+ " as the ClientProtocolProvider");
break;
} else {
LOG.debug("Cannot pick " + provider.getClass().getName()
+ " as the ClientProtocolProvider - returned null protocol");
}
} catch (Exception e) {
final String errMsg = "Failed to use " + provider.getClass().getName()
+ " due to error: ";
initEx.addSuppressed(new IOException(errMsg, e));
LOG.info(errMsg, e);
}
}
if (null == clientProtocolProvider || null == client) {
throw initEx;
}
}
initialize是cluster在初始化时真正调用的方法,代码第四行调用了我们上面提到的initProviderList方法来初始化集群基本信息。

for循环中依次取出每个ClientProtocolProvider,通过其create()方法构造ClientProtocol实例。
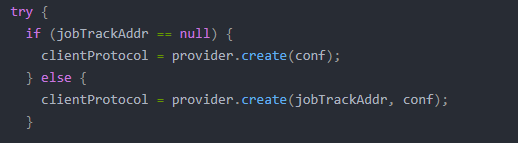
接下来判断jobTrackAddr是否为空。我们通过jobTrackAddr是否存在来决定配置文件有没有配置YARN信息。
如果配置文件没有配置YARN信息,则构建LocalRunner,MR任务本地运行。如果配置文件有配置YARN信息,则构建YarnRunner,MR任务在YARN集群上运行。
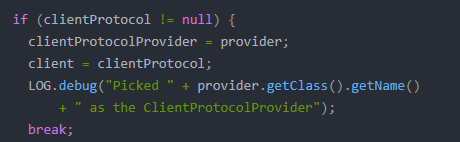
最后设置clientProtocolProvider 和client信息,并且退出循环。不难看出其余代码部分主要是处理抛出的异常,这里就不做进一步分析。至此,cluster初始化完成。
上面create()方法时提到了两种ClientProtocolProvider实现类。
MapReduce中,ClientProtocolProvider抽象类的实现共有YarnClientProtocolProvider、LocalClientProtocolProvider两种,前者为Yarn模式,而后者为Local模式。

为了进一步了解两者的区别,我们分别点进对应方法查看源码。
ClientProtocolProvider实现类LocalClientProtocolProvider
我们先看下看下Local模式,LocalClientProtocolProvider的create()方法,代码如下:
package org.apache.hadoop.mapred;
import java.io.IOException;
import java.net.InetSocketAddress;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.MRConfig;
import org.apache.hadoop.mapreduce.protocol.ClientProtocol;
import org.apache.hadoop.mapreduce.protocol.ClientProtocolProvider;
@InterfaceAudience.Private
public class LocalClientProtocolProvider extends ClientProtocolProvider {
@Override
public ClientProtocol create(Configuration conf) throws IOException {
//两个常量:"mapreduce.framework.name","local"
String framework =
conf.get(MRConfig.FRAMEWORK_NAME, MRConfig.LOCAL_FRAMEWORK_NAME);
//若framework是local,则返回LocalJobRunner,并且设置Map任务数1;否则返回null
if (!MRConfig.LOCAL_FRAMEWORK_NAME.equals(framework)) {
return null;
}
conf.setInt(JobContext.NUM_MAPS, 1);
return new LocalJobRunner(conf);
}
@Override
public ClientProtocol create(InetSocketAddress addr, Configuration conf) {
return null; // LocalJobRunner doesn't use a socket
}
@Override
public void close(ClientProtocol clientProtocol) {
// no clean up required
}
}
由上可知,MapReduce需要看参数mapreduce.framework.name确定连接模式,但默认是Local模式的。
ClientProtocolProvider实现类YarnClientProtocolProvider
再来看Yarn模式,看下YarnClientProtocolProvider的create()方法:
package org.apache.hadoop.mapred;
import java.io.IOException;
import java.net.InetSocketAddress;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.MRConfig;
import org.apache.hadoop.mapreduce.protocol.ClientProtocol;
import org.apache.hadoop.mapreduce.protocol.ClientProtocolProvider;
public class YarnClientProtocolProvider extends ClientProtocolProvider {
@Override
public ClientProtocol create(Configuration conf) throws IOException {
//若参数mapreduce.framework.name配置为Yarn,则构造一个YARNRunner实例并返回,否则返回null
if (MRConfig.YARN_FRAMEWORK_NAME.equals(conf.get(MRConfig.FRAMEWORK_NAME))) {
return new YARNRunner(conf);
}
return null;
}
@Override
public ClientProtocol create(InetSocketAddress addr, Configuration conf)
throws IOException {
return create(conf);
}
@Override
public void close(ClientProtocol clientProtocol) throws IOException {
if (clientProtocol instanceof YARNRunner) {
((YARNRunner)clientProtocol).close();
}
}
}
到了这里,我们就能够知道一个很重要的信息,Cluster中客户端通信协议ClientProtocol实例,要么是Yarn模式下的YARNRunner,要么就是Local模式下的LocalJobRunner。
小结
本次我们对org.apache.hadoop.mapreduce.Cluster的相关源码进行了分析。可以看出,cluster类并没有太多的特殊方法,只是提供给其他类的一些get方法。因此我们把重心放在了cluster的构造方法和初始化上。根据是否配置yarn信息,cluster类的初始化方法会决定MapReduce任务是在本地还是集群上运行。通过对cluster类的分析,对底层又有了进一步了解。