在我的博客
从url输入到页面渲染:导航流程:导航流程
中主要介绍了浏览器端的网络请求过程,完成了网络请求和响应,如果响应头中Content-Type的值为text/html,那么接下来便是浏览器对于服务器返回响应数据的解析和渲染,这个过程主要可以分为如下几个子阶段:构建DOM树、样式计算、布局阶段、分层、绘制、分块、光栅化和合成。下面我们就各个阶段深入了解:
构建DOM树
由于浏览器无法直接理解HTML字符串,因此将这一系列的字节流转换成一种有意义并且方便操作的数据结构,这种数据结构就是DOM树,DOM树本质上是一个以document为根节点的多叉树。
那么通过什么样的方式来进行解析呢?
HTML文法的本质
:
首先,我们应该清楚把握一点:HTML的文法并不是
上下文无关文法
,什么是
上下文无关文法
呢?
在编译原理学科中对于其的定义为:
若一个形式文法G = (N, Σ, P, S) 的产生式规则都取如下的形式:V->w,则叫上下文无关语法。其中 V∈N ,w∈(N∪Σ)* 。
其中把 G = (N, Σ, P, S) 中各个参量的意义解释一下:
- N 是非终结符(顾名思义,就是说最后一个符号不是它, 下面同理)集合。
- Σ 是终结符集合。
- P 是开始符,它必须属于 N,也就是非终结符。
- S 就是不同的产生式的集合。如 S -> aSb 等等。
通俗一点讲,
上下文无关文法
就是说这个文法中所有产生式的左边都是一个非终结符,举个例子:
A -> B
这个文法中,每个产生式左边都会有一个非终结符,这就是
上下文无关文法
。在这种情况下,xBy一定是可以规约出xAy的。
aA -> B
Aa -> B
这种情况就不是
上下文无关文法
,当遇到B的时候,我们不知道到底能不能规约出A,取决于左边或者右边是否有a存在,也就是说和上下文有关。
那么HTML为什么不是
上下文无关文法
,实际上规范的 HTML 语法,是符合上下文无关文法的,能够体现它非上下文无关的是不标准的语法。
比如解析器扫描到form标签的时候,
上下文无关文法
的处理方式是直接创建对应 form 的 DOM 对象,而真实的 HTML5 场景中却不是这样,解析器会查看 form 的上下文,如果这个 form 标签的父标签也是 form, 那么直接跳过当前的 form 标签,否则才创建 DOM 对象。
常规的编程语言都是上下文无关的,而HTML却相反,也正是它非上下文无关的特性,决定了HTML Parser并不能使用常规编程语言的解析器来完成,需要另辟蹊径。
HTML解析算法
:
HTML5 规范
详细地介绍了解析算法。这个算法分为两个阶段:
- 标记化。
- DOM树构建。
对应的两个过程就是词法分析和语法分析。
1、标记化
标记化是词法分析过程,这个算法输入为HTML文本,输出为HTML标记,也称为标记生成器。HTML 标记包括起始标记、结束标记、属性名称和属性值。
标记生成器运用
有限自动状态机
来完成,状态机一共有4个状态:
- 数据状态(Data)、
- 标记打开状态(Tag open)、
- 标记名称状态(Tag name)、
- 关闭标记打开状态(Close tag open state)。
有限自动状态机在当前状态下,接收一个或多个字符,就会更新到下一个状态,通过4个状态之间的切换标记生成器识别标记,传递给树构造器,然后接受下一个字符以识别下一个标记;如此反复直到输入的结束。
我们通过如下示例演示该过程:
<html>
<body>
Hello world
</body>
</html>
-
遇到
<
, 状态为
标记打开
。 -
接收
[a-z]
的字符,会进入
标记名称状态
。 -
这个状态一直保持,直到遇到
>
,表示标记名称记录完成,这时候变为
数据状态
- 接下来遇到body标签做同样的处理,这个时候html和body的标记都记录好了。
-
现在来到
<body>
中的
>
,进入
数据状态
,之后保持这样状态接收后面的字符hello world。 -
接着接收
</body>
中的
<
,回到
标记打开状态
,接收下一个
/
后,这时候会创建一个
end tag
的token。 -
随后进入
标记名称状态
, 遇到
>
回到
数据状态
。 -
接着以同样的样式处理
</html>
。
2、DOM树构建
树构建的过程也就是语法分析,通过标记生成器生成的标签会发送到DOM树构建器,构建树会根据传过来的标签创建对应的DOM对象,由于DOM 树是一个以document为根节点的多叉树。因此解析器首先会创建一个document对象。标记生成器会把每个标记的信息发送给建树器。建树器接收到相应的标记时,会创建对应的 DOM 对象。
构建算法主要由两部分构成:
- DOM树
- 存放标签名的栈
还以上面的示例演示:
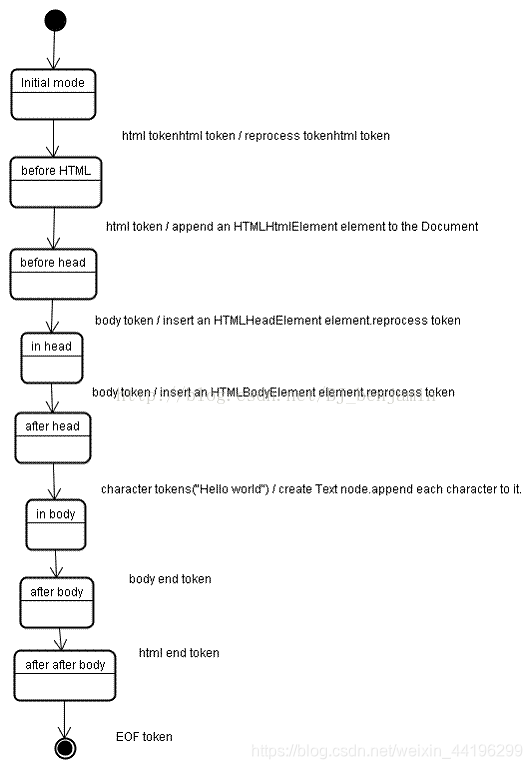
- 首先,状态为初始化状态。
-
接收到标记生成器传来的
<html>
标签,这时候状态变为before html状态。同时创建一个HTMLHtmlElement的 DOM 元素, 将其加到document根对象上,并进行压栈操作。 - 接着状态自动变为before head, 此时从标记生成器那边传来body,表示并没有head, 这时候建树器会自动创建一个HTMLHeadElement并将其加入到DOM树中。
- 现在进入到in head状态, 然后直接跳到after head。
-
现在标记生成器传来了
<body>
标签,创建HTMLBodyElement, 插入到DOM树中,同时压入开放标记栈。 - 接着状态变为in body,然后来接收后面一系列的字符: Hello world。
- 接收到第一个字符的时候,会创建一个Text节点并把字符插入其中,然后把Text节点插入到 DOM 树中body元素的下面。随着不断接收后面的字符,这些字符会附在Text节点上。
- 现在,标记生成器传过来一个body的结束标记,进入到after body状态。
- 标记生成器最后传过来一个html的结束标记, 进入到after after body的状态,表示解析过程到此结束。
整体流程如下图所示:
但事实上Chrome浏览器中DOM树构建算法却又与此不同,Chrome浏览器中DOM树构建器主要有以下三部分组成:
- DOM树
- 存放标签名的栈
- 任务队列
我们通过如下示例演示该过程:
<html>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>picture:</p>
<img src="example.png"/>
</div>
<div>
<p>A paragraph of explanatory text...</p>
</div>
</div>
</body>
</html>
- 创建解析器的同时也会创建Document对象。
-
第一个遇到的开标签是
<html>
标签,解析器会先创建一个html节点,然后把它加到任务队列里面,传递两个参数,第一个参数是父节点,第二个参数是当前节点。 - 解析器会将html节点压入栈中,这个栈负责存放所有未遇到闭标签的所有开标签。
- 执行队列里的任务,此时解析器会根据任务类型的不同调用不同的执行函数,由于本次是insert的,它会去执行一个插入的函数,在具体调用前插入函数前它会先去检查父元素是否支持子元素,如果不支持,则直接返回,就像video标签不支持子元素。
-
在插入函数中首先会对父节点进行判断,如果没有lastChild,会将这个子节点作为firstChild,如果父节点已经有lastChild了,因此会把这个子元素的previousSibling指向老的lastChild,老的lastChild的nexSibling指向它,在我们的示例中由于
<html>
标签并没有兄弟元素,因此html节点将作为Document的firstChild插入。 -
接下来便是
<body>
标签,解析器同样会创建一个对应的body节点,然后将其加入到任务队列,同时将body节点入栈,由于我们刚刚把html元素压了进去,则栈顶元素为html元素,所以head的父节点就为html。所以每当遇到一个开标签时,就把它压起来,下一次再遇到一个开标签时,它的父元素就是上一个开标签,因此解析器借助一个栈建立起了父子关系。 -
重复上述步骤直到当解析器遇到一个闭标签时,会把栈里面的元素一直pop出来,直到pop到第一个和它标签名字一样的,在我们的示例中首先接收到一个
</h1>
结束标签,此时查询栈顶元素,恰好与h1属于同种类型的标签,因此解析器将栈顶元素弹出,向DOM树中加入节点h1。 -
继续向下执行,我们需要注意如果遇到的是没有封闭标签的元素如我们示例中的
<img/>
,则直接加入DOM树中即可,无需入栈。 - 继续执行直到遇到body闭标签后,此时需要注意解析器并不会把body给pop出来,因为如果body闭标签后面又再写了标签的话,就会自动当成body的子元素。这也是HTML语法的容错机制中的一种,后面的html节点与body相同,但是body节点与html节点依然会加入到DOM树中,至此DOM树便成功生成。
这个时候你可能会有一个问题,为什么要用一个任务队列存放将要插入的结点呢,而不是直接插入呢?一个原因是放到task里面方便统一处理,并且有些任务可能不能立即执行,要先存起来。不过在我们这个案例里面都是存完后下一步就执行了。
容错机制
:
HTML相较于XML最突出的就是其强大的宽容策略,也就是其突出的容错能力,事实上你从来不会在一个html页面上看到“无效语法”这样的错误,这是因为浏览器修复了无效内容并继续工作。
以下面这段HTML代码为例:
<html>
<mytag></mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
这段html违反了很多规则:mytag不是合法的标签,p及div错误的嵌套等等,但是浏览器仍然可以没有任何怨言的继续显示,它在解析的过程中修复了html出现的错误。
浏览器都具有错误处理的能力,但是,另人惊讶的是,这并不是html最新规范的内容,就像书签及前进后退按钮一样,它只是浏览器长期发展的结果。一些比较知名的非法html结构,在许多站点中出现过,浏览器都试着以一种和其他浏览器一致的方式去修复。
但是在
Html5规范
定义了这方面的需求,webkit在html解析类开始部分的注释中做了很好的总结。下面是一些webkit容错的经典例子:
1、
</br>
标签会被替换为
<br>
一些网站使用
</br>
替代
<br>
,为了兼容IE和Firefox,webkit将其看作
<br>
,对应的源码处理为:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
2、表格离散
这指一个表格嵌套在另一个表格中,但不在它的某个单元格内,例如:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
此时webkit将会将嵌套的表格变为两个兄弟表格:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
对应的源码实现为:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag,m_document);
}
3、表单元素嵌套
如果代码中出现form元素的子元素还是form元素会直接忽略里面的form元素,对应的源码实现为:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag,m_document);
}
4、太深的标签继承
Webkit最多只允许20个相同类型的标签嵌套,多出来的将被忽略,对应的源码实现为:
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName){
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
5、错误的html、body闭合标签
此处无须赘述,在我们之前DOM树构建算法时提到我们从来不闭合body与html,因为有时一些网页总是在还未真正结束时就闭合它,又或者在在body或html的闭合标签后再次添加元素标签,事实上我们依赖调用end方法去执行关闭的处理:
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;