文章目录
历年image1000优秀网络汇总
参考论文《Deep Learning for Generic Object Detection: A Survey》历年image1000优秀网络汇总如下表:


在发展过程中也出现了很多优秀的轻量化模型:SqueezeNet、MobileNet、ShuffleNet、Xception
AlexNet
alexnet 网络总共的层数为8层,5层卷积,3层全连接层。不多说,直接上图:

VGGNet(2014亚军)


特点:
1)VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling分开,采用ReLU函数。
2)VGG使用多个较小卷积核(3×3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力。
3)相比AlexNet的3×3的池化核,VGG全部采用2×2的池化核。
4)层数更深、特征图更宽。
GoogleNet(2014冠军)
GoogleNet的Inception历经了V1、V2、V3、V4等多个版本的发展。
InceptionV1

引入1×1卷积的主要目的是为了减少维度和计算量。网络结构如下:

Inception V2
大尺寸的卷积核可以带来更大的感受野,但也意味着会产生更多的参数,比如5×5卷积核的参数有25个,3×3卷积核的参数有9个,前者是后者的25/9=2.78倍。因此,GoogLeNet团队提出可以用2个连续的3×3卷积层组成的小网络来代替单个的5×5卷积层,即在保持感受野范围的同时又减少了参数量,如下图:

那么这种替代方案会造成表达能力的下降吗?通过大量实验表明,并不会造成表达缺失。
可以看出,大卷积核完全可以由一系列的3×3卷积核来替代,那能不能再分解得更小一点呢?GoogLeNet团队考虑了nx1的卷积核,如下图所示,用3个3×1取代3×3卷积:
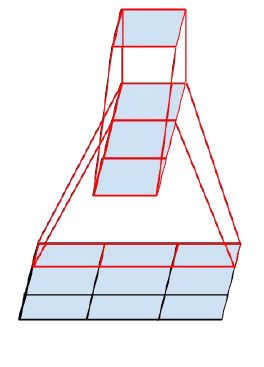
因此,任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。

降低特征图大小:

先池化再作Inception卷积,或者先作Inception卷积再作池化。但是方法一(左图)先作pooling(池化)会导致特征表示遇到瓶颈(特征缺失),方法二(右图)是正常的缩小,但计算量很大。为了同时保持特征表示且降低计算量,将网络结构改为下图,使用两个并行化的模块来降低计算量(卷积、池化并行执行,再进行合并)

Inception V3
Inception v3整体上采用了Inception v2的网络结构,并在优化算法、正则化等方面做了改进,总结如下:
- 优化算法使用RMSProp替代SGD。
- 使用Label Smoothing Regularization(LSR)方法。
- 将第一个7×7卷积层分解为两个3×3卷积层。
- 辅助分类器(auxiliary classifier)的全连接层也进行了batch-normalization操作。
Inception V3一个最重要的改进是分解(Factorization),将7×7分解成两个一维的卷积(1×7,7×1),3×3也是一样(1×3,3×1),这样的好处,既可以加速计算,又可以将1个卷积拆成2个卷积,使得网络深度进一步增加,增加了网络的非线性(每增加一层都要进行ReLU)。另外,网络输入从224×224变为了299×299。
Inception V4
Inception v4中基本的Inception module还是沿袭了Inception v2/v3的结构,只是结构看起来更加简洁统一,并且使用更多的Inception module,实验效果也更好。
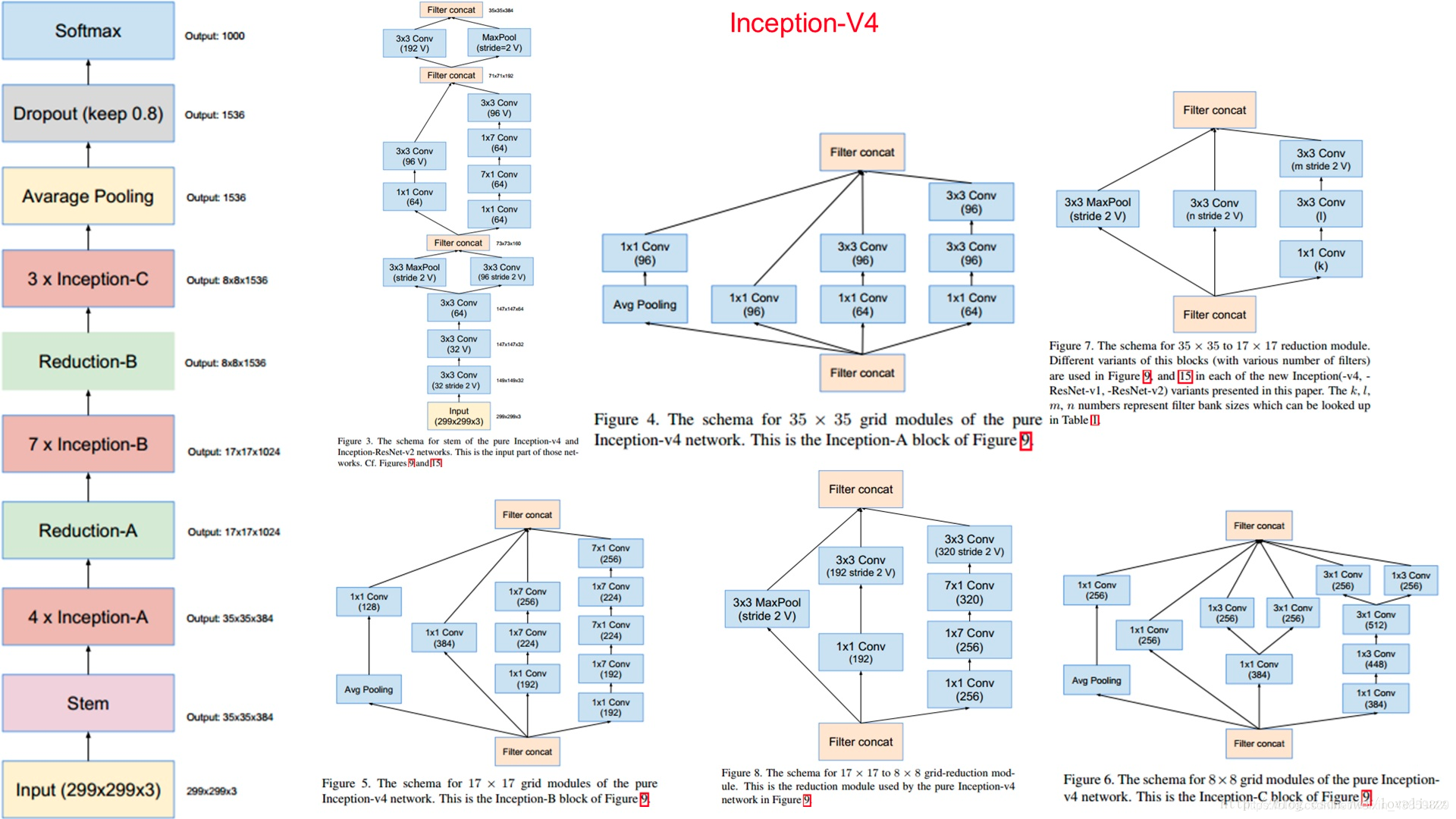
参考:https://www.jianshu.com/p/006248a3fd7f; https://my.oschina.net/u/876354/blog/1637819
ResNet
Resnet也比较简单不多说。
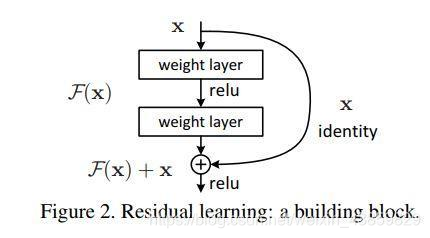
resnet 的变体

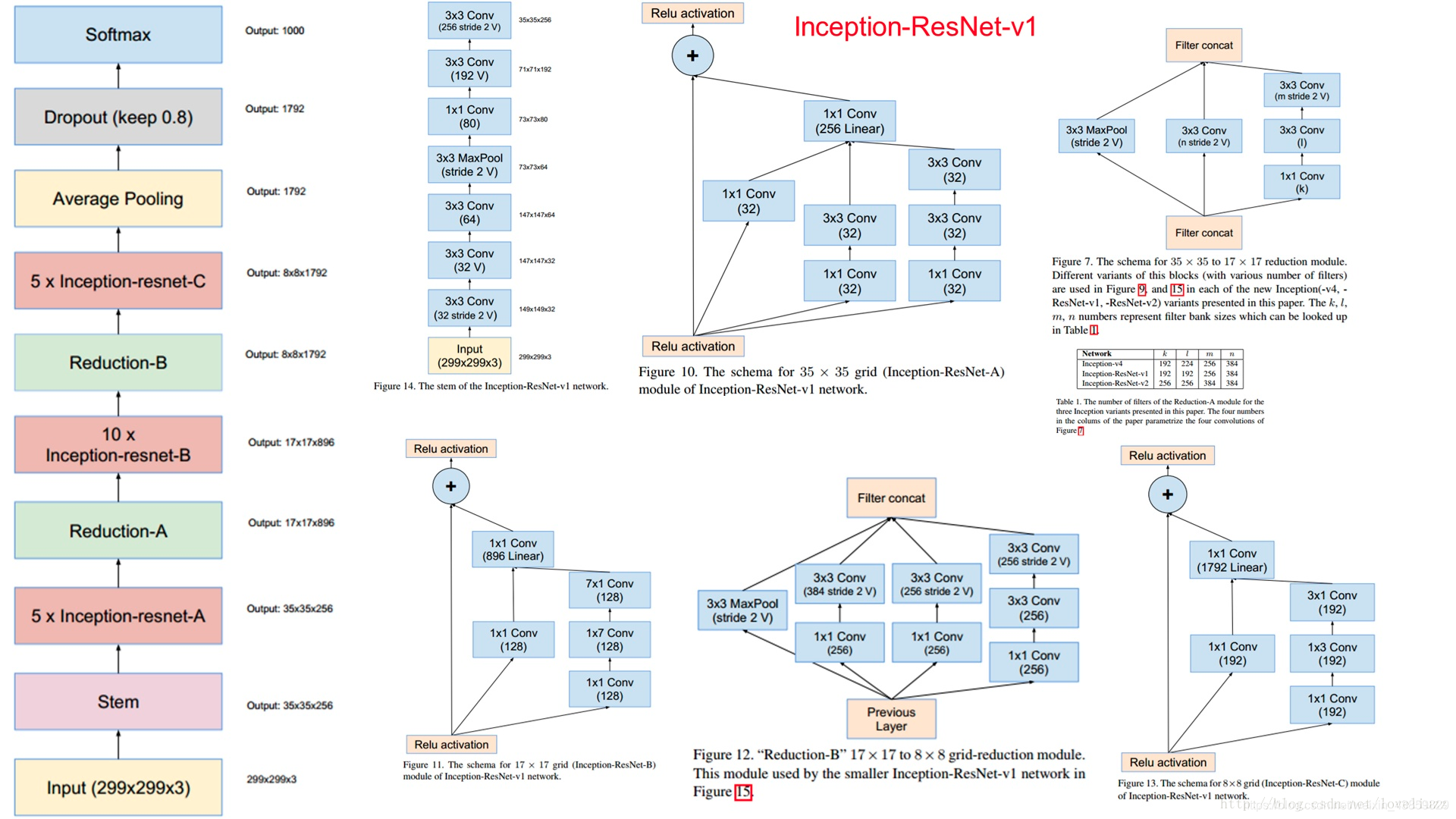
InceptionResNet

ResNeXt
与 ResNet 相比,相同的参数个数,结果更好:一个 101 层的 ResNeXt 网络,和 200 层的 ResNet 准确度差不多,但是计算量只有后者的一半
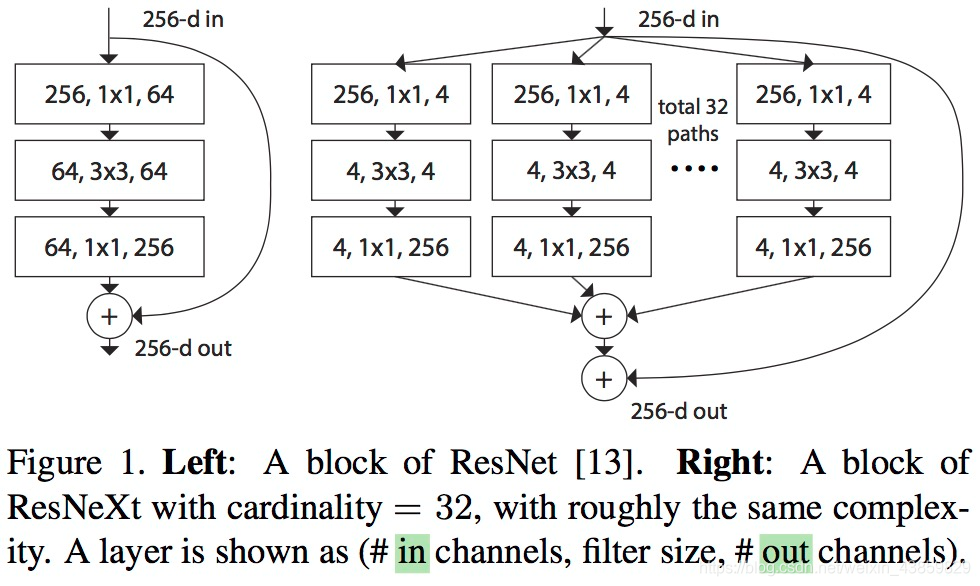
In particular, a 101-layer ResNeXt is able to achieve better accuracy than ResNet-200 but has only 50% complexity.
这里作者展示了三种相同的 ResNeXt blocks。fig3.a 就是前面所说的aggregated residual transformations。 fig3.b 则采用两层卷积后 concatenate,再卷积,有点类似 Inception-ResNet,只不过这里的 paths 都是相同的拓扑结构。fig 3.c采用的是grouped convolutions,这个 group 参数就是 caffe 的 convolusion 层的 group 参数,用来限制本层卷积核和输入 channels 的卷积,最早应该是 AlexNet 上使用,可以减少计算量。这里 fig 3.c 采用32个 group,每个 group 的输入输出 channels 都是4,最后把channels合并。这张图的 fig3.c 和 fig1 的左边图很像,差别在于fig3.c的中间 filter 数量(此处为128,而fig 1中为64)更多。作者在文中明确说明这三种结构是严格等价的,并且用这三个结构做出来的结果一模一样,在本文中展示的是 fig3.c 的结果,因为 fig3.c 的结构比较简洁而且速度更快。

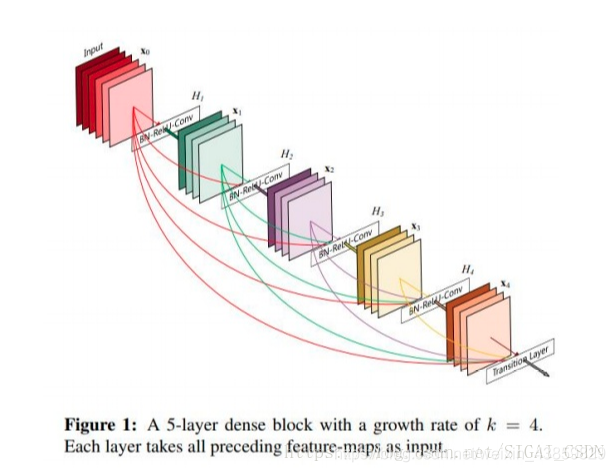
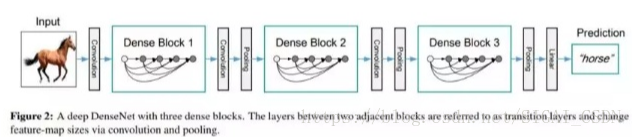
DenseNet
直接上图,一看就懂。
MobileNet(V123)

MobileNet V1
采用了Depthwise Separable convolution 深度可分离卷积减小计算量。
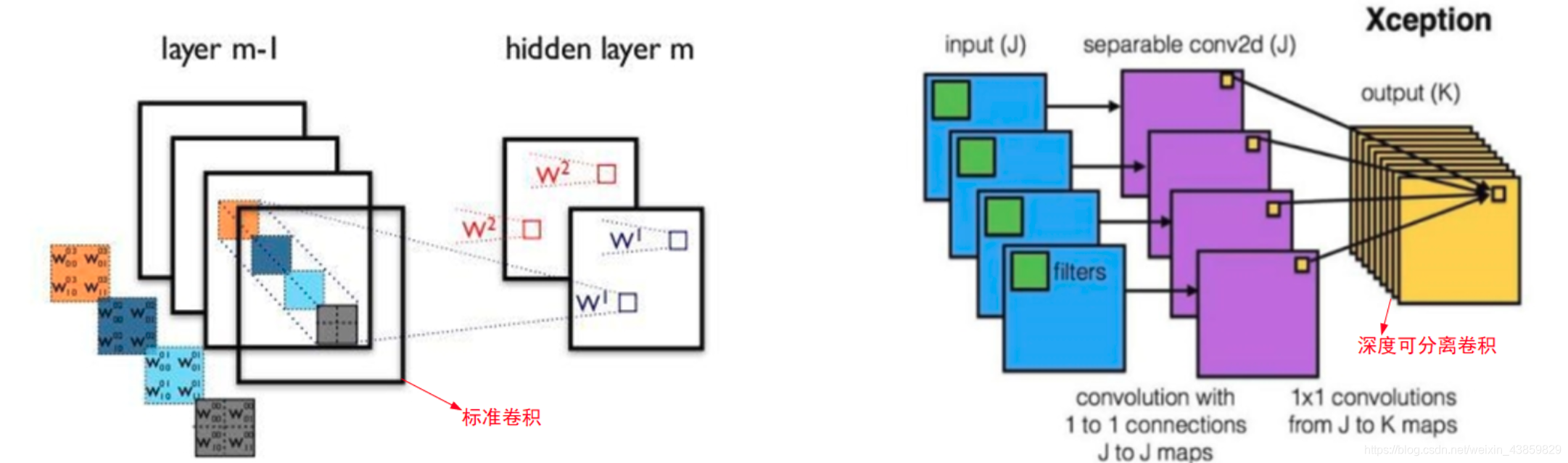

再画详细一点就是:
常规cov过程:
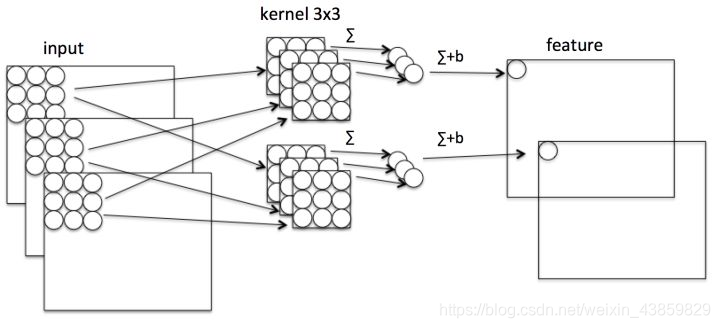
**deepwise:**将分组卷积进行到底,每层都分一个核。
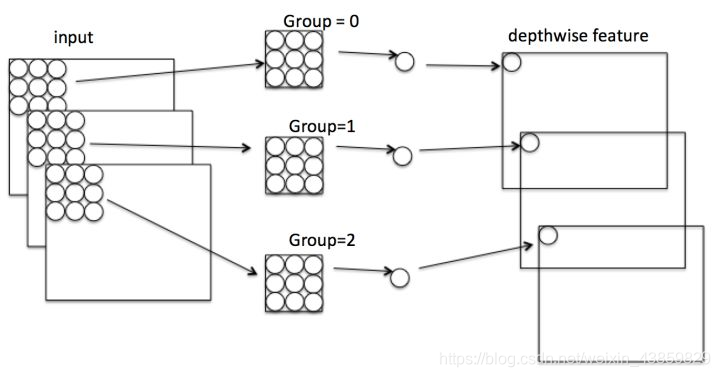
pointwise:

pytorch 实现过程:
分组卷积:
class CSDN_Tem(nn.Module):
def __init__(self, in_ch, out_ch, groups):
super(CSDN_Tem, self).__init__()
self.conv = nn.Conv2d(
in_channels=in_ch,
out_channels=out_ch,
kernel_size=3,
stride=1,
padding=1,
groups=groups
)
def forward(self, input):
out = self.conv(input)
return out
============================================================
深度可分离卷积: 分组就为输入的通道数。
class CSDN_Tem(nn.Module):
def __init__(self, in_ch, out_ch):
super(CSDN_Tem, self).__init__()
self.depth_conv = nn.Conv2d(
in_channels=in_ch,
out_channels=in_ch,
kernel_size=3,
stride=1,
padding=1,
groups=in_ch
)
self.point_conv = nn.Conv2d(
in_channels=in_ch,
out_channels=out_ch,
kernel_size=1,
stride=1,
padding=0,
groups=1
)
def forward(self, input):
out = self.depth_conv(input)
out = self.point_conv(out)
return out
MobileNet V2
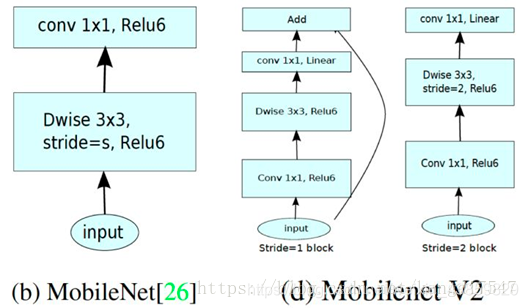
2)MobileNetV1遗留的问题
1、结构问题:
MobileNet V1 的结构其实非常简单,论文里是一个非常复古的直筒结构,类似于VGG一样。这种结构的性价比其实不高,后续一系列的 ResNet, DenseNet 等结构已经证明通过复用图像特征,使用 Concat/Eltwise+ 等操作进行融合,能极大提升网络的性价比。
2、Depthwise Convolution的潜在问题:
Depthwise Conv确实是大大降低了计算量,而且N×N Depthwise +1×1PointWise的结构在性能上也能接近N×N Conv。在实际使用的时候,我们发现Depthwise部分的kernel比较容易训废掉:训练完之后发现Depthwise训出来的kernel有不少是空的。当时我们认为,Depthwise每个kernel dim相对于普通Conv要小得多,过小的kernel_dim, 加上ReLU的激活影响下,使得神经元输出很容易变为0,所以就学废了。ReLU对于0的输出的梯度为0,所以一旦陷入0输出,就没法恢复了。我们还发现,这个问题在定点化低精度训练的时候会进一步放大。
3)MobileNet V2的创新点
1、Inverted Residual Block
MobileNet V1没有很好的利用Residual Connection,而Residual Connection通常情况下总是好的,所以MobileNet V2加上。先看看原始的ResNet Block长什么样,下图左边:
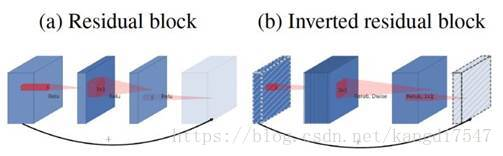
先用1×1降通道过ReLU,再3×3空间卷积过ReLU,再用1×1卷积过ReLU恢复通道,并和输入相加。之所以要1×1卷积降通道,是为了减少计算量,不然中间的3×3空间卷积计算量太大。所以Residual block是沙漏形,两边宽中间窄。
但是,现在我们中间的3×3卷积变为了Depthwise的了,计算量很少了,所以通道可以多一点,效果更好,所以通过1×1卷积先提升通道数,再Depthwise的3×3空间卷积,再用1×1卷积降低维度。两端的通道数都很小,所以1×1卷积升通道或降通道计算量都并不大,而中间通道数虽然多,但是Depthwise 的卷积计算量也不大。作者称之为Inverted Residual Block,两边窄中间宽,像柳叶,较小的计算量得到较好的性能。
2、ReLU6
首先说明一下 ReLU6,卷积之后通常会接一个 ReLU 非线性激活,在 MobileNet V1 里面使用 ReLU6,ReLU6 就是普通的ReLU但是限制最大输出值为 6,这是为了在移动端设备 float16/int8 的低精度的时候,也能有很好的数值分辨率,如果对 ReLU 的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16/int8无法很好地精确描述如此大范围的数值,带来精度损失。
本文提出,最后输出的 ReLU6 去掉,直接线性输出,理由是:ReLU 变换后保留非0区域对应于一个线性变换,仅当输入低维时ReLU 能保留所有完整信息。
在看 MobileNet V1的时候,我就疑问为什么没有把后面的 ReLU去掉,因为Xception已经实验证明了 Depthwise 卷积后再加ReLU 效果会变差,作者猜想可能是 Depthwise 输出太浅了, 应用 ReLU会带来信息丢失,而 MobileNet V1还引用了 Xception 的论文,但是在 Depthwise 卷积后面还是加了ReLU。在 MobileNet V2 这个 ReLU终于去掉了,并用了大量的篇幅来说明为什么要去掉。
参考:https://blog.csdn.net/kangdi7547/article/details/81431572
mobilenet-v3
mobilenet-v3是Google继mobilenet-v2之后的又一力作,作为mobilenet系列的新成员,自然效果会提升,mobilenet-v3提供了两个版本,分别为mobilenet-v3 large 以及mobilenet-v3 small,分别适用于对资源不同要求的情况,论文中提到,mobilenet-v3 small在imagenet分类任务上,较mobilenet-v2,精度提高了大约3.2%,时间却减少了15%,mobilenet-v3 large在imagenet分类任务上,较mobilenet-v2,精度提高了大约4.6%,时间减少了5%,mobilenet-v3 large 与v2相比,在COCO上达到相同的精度,速度快了25%,同时在分割算法上也有一定的提高。本文还有一个亮点在于,网络的设计利用了NAS(network architecture search)算法以及NetAdapt algorithm算法。并且,本文还介绍了一些提升网络效果的trick,这些trick也提升了不少的精度以及速度。
1.引入SE结构
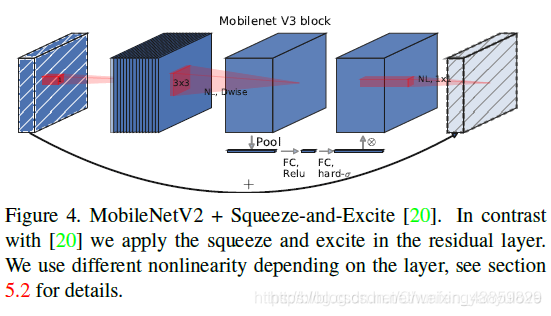
2、非线性变换的改变
使用h-swish替换swish,swish是谷歌自家的研究成果,颇有点自卖自夸的意思,这次在其基础上,为速度进行了优化。swish与h-swish公式如下所示,由于sigmoid的计算耗时较长,特别是在移动端,这些耗时就会比较明显,所以作者使用ReLU6(x+3)/6来近似替代sigmoid,观察下图可以发现,其实相差不大的。利用ReLU有几点好处,1.可以在任何软硬件平台进行计算,2.量化的时候,它消除了潜在的精度损失,使用h-swish替换swith,在量化模式下回提高大约15%的效率,另外,h-swish在深层网络中更加明显。
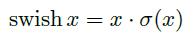
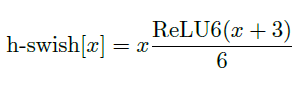
SE ResNet
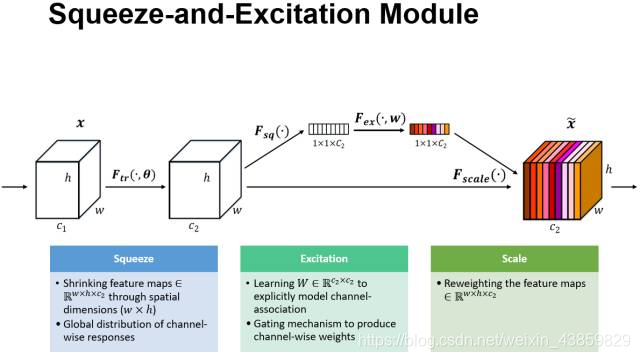
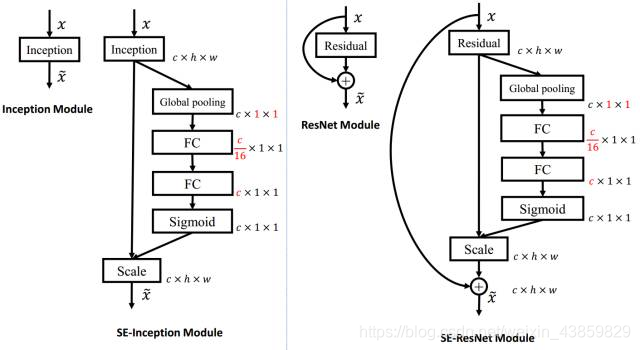
SE模块嵌入到Inception和resnet结构的示例。
SuffleNet
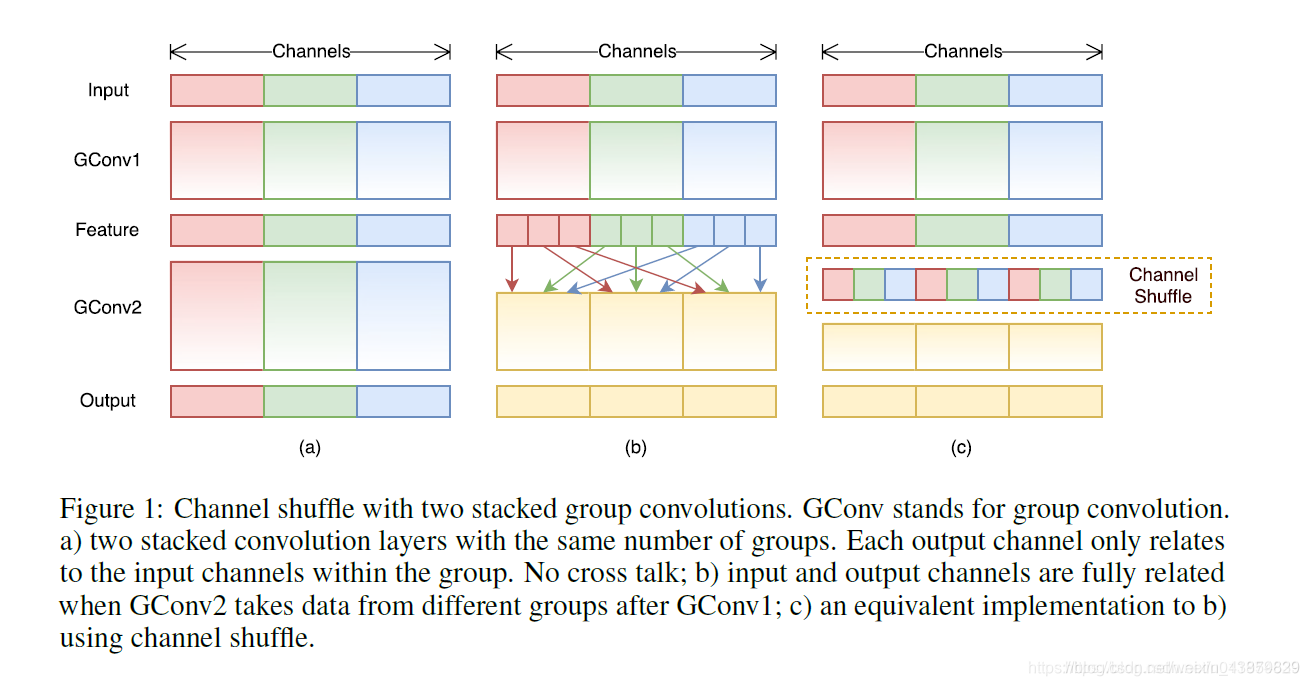
群卷积的通道混洗(Channel Shuffle for Group Convolutions)
在小型网络中,昂贵的逐点卷积造成有限的通道之间充满约束,这会显著的损失精度。为了解决这个问题,一个直接的方法是应用通道稀疏连接,例如组卷积(group convolutions)。通过确保每个卷积操作仅在对应的输入通道组上,组卷积可以显著的降低计算损失。然而,如果多个组卷积堆叠在一起,会有一个副作用: 某个通道输出仅从一小部分输入通道中导出,如下图(a)所示,这样的属性降低了通道组之间的信息流通,降低了信息表示能力
如果我们允许组卷积能够得到不同组的输入数据,即上图(b)所示效果,那么输入和输出通道会是全关联的。具体来说,对于上一层输出的通道,我们可做一个混洗(Shuffle)操作,如上图©所示,再分成几个组,feed到下一层。
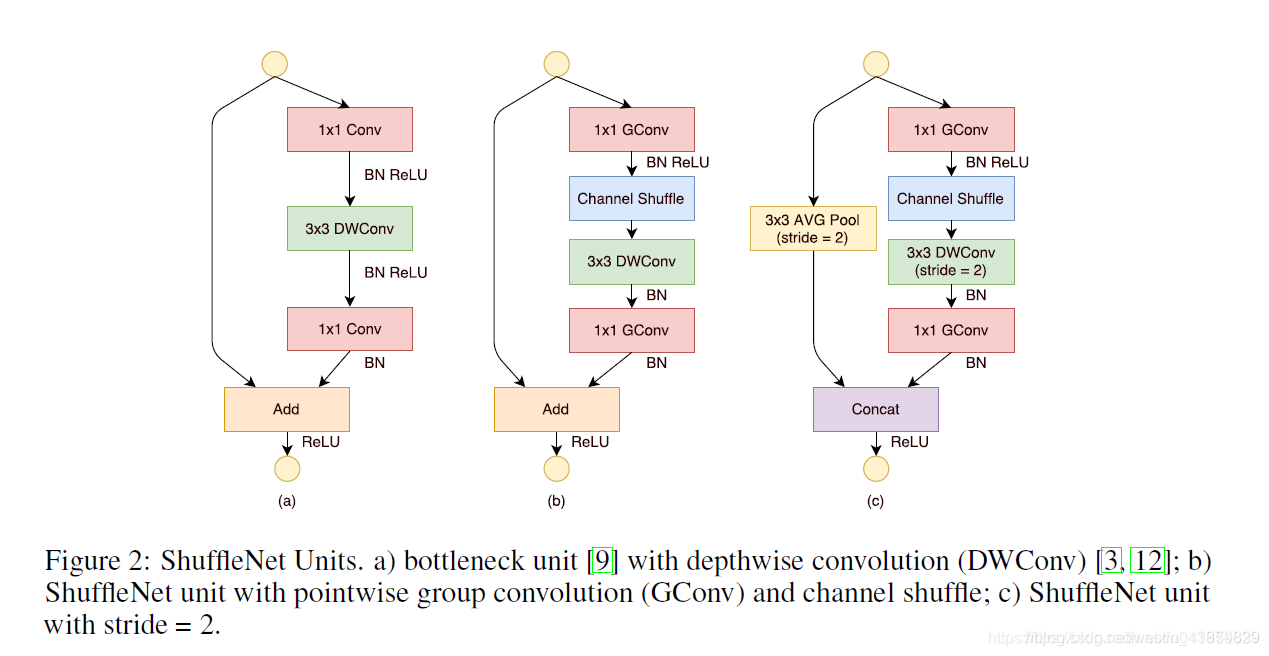
图(a)是一个残差模块。对于主分支部分,我们可将其中标准卷积3×33×3拆分成深度分离卷积(可参考我的MobileNet笔记)。我们将第一个1×1卷积替换为逐点组卷积,再作通道混洗(即(b))。
图(b)即ShuffleNet unit,主分支最后的1×1Conv1×1Conv改为1×1GConv,为了适配和恒等映射做通道融合。配合BN层和ReLU激活函数构成基本单元.
图©即是做降采样的ShuffleNet unit,这主要做了两点修改:
在辅分支加入步长为2的3×3平均池化
原本做元素相加的操作转为了通道级联,这扩大了通道维度,增加的计算成本却很少
参考:https://blog.csdn.net/u011974639/article/details/79200559