⭐ 简介:大家好,我是zy阿二,我是一名对知识充满渴望的自由职业者。
❤️ 如果对你有帮助,请关注我,让我们共同进步。有不足之处请留言指正!
用简单的for循环示例,让你快速了解 zip、eval、map、enumerate 这4个高级函数所带来的便利!
1. zip() 打包并重组
直接上代码:示例1:
id = [1,2,3,4,5,]
name = ['张三','李四','王五','赵六','周七']
score = [99.5,100,55,77,89]
seat= ['一三班','五六班','二四班','五六班','六九班']
# 用zip方法,将上面4个list重新组合。
for i in zip(id,name,score,seat):
print(i)
调试输出结果:
(1, '张三', 99.5, '一三班')
(2, '李四', 100, '五六班')
(3, '王五', 55, '二四班')
(4, '赵六', 77, '五六班')
(5, '周七', 89, '六九班')
示例2:
# 删除了id,替换为 range(1,99)
# 此时由于其他3个list的长度为5,zip只会打包5个tuple。
name = ['张三','李四','王五','赵六','周七']
score = [99.5,100,55,77,89]
seat= ['一三班','五六班','二四班','五六班','六九班']
# 当zip中包裹的数组长度不相同时,取最短数组。
for i in zip(range(1,99),name,score,seat):
print(i)
调试输出结果:
(1, '张三', 99.5, '一三班')
(2, '李四', 100, '五六班')
(3, '王五', 55, '二四班')
(4, '赵六', 77, '五六班')
(5, '周七', 89, '六九班')
示例3:
# zip打包字典的方法。
id = {1: '张三', 2: '李四', 3: '王五', 4: '赵六', 5: '周七'}
socre = {'语文': 90, '数学': 80, '英语': 70, '物理': 95, '化学': 99}
for i in zip(id, id.values(), socre, socre.values()):
print(i)
调试输出结果:
(1, '张三', '语文', 90)
(2, '李四', '数学', 80)
(3, '王五', '英语', 70)
(4, '赵六', '物理', 95)
(5, '周七', '化学', 99)
2. eval(),将str 转换成 Python表达式
示例1: 直接用eval将字符串变算式
# 正常打印字符串
print("99+99")
# eval方法下打印的字符串
print(eval("99+99"))
调试输出结果:
99+99
198
❤️ 如果对你有帮助~请关注我,让我们共同进步。
示例2: 结合其他函数,例如input,提示输入并计算
a = eval(input('请输入数字:'))
print(a + 10)
调试输出结果:
请输入数字:10
20
示例3:re替换字符串 + eval将请求头转换成Python的dict
import re
# 这里我在浏览器上随便复制了一个请求头,str,正常情况需要手动修改在key和value上加引号
data= """
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36
"""
# 利用正则表达式替换了一下data中的字符串
headers = '{' + re.sub(r'([A-Z].*?): (.*?)\n', r"'\1': '\2',\n", data, re.S) + '}'
print("1. ", type(headers)) # 1. 输出headers 的类型是 str
print("2. ", eval(headers)) # 2. 用eval方法转换成Python的表达式
#3. 变成了一个字典。直接可以用在 requests.get(url, headers=eval(headers))
print("3. ", type(eval(headers)))
调试输出结果:
<class 'str'>
{'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
<class 'dict'>
3. map(),将函数对指定的序列做映射。
格式:map(函数名,序列或多个序列),返回一个新的集合。依次将list中的每一个value传入函数中,根据函数renturn的值组成一个新的list。
示例1:先来用for循环模拟map的工作方式方便理解
def func(a): # 设置一个简单的函数, 传入一个a,返回 a + 1
return a + 1
# 先用传统的方式将一个list中的value逐一传入func函数返回结果存入一个新的list中。
b = []
for i in [1, 2, 3, 4, 5, 6]:
b.append(func(i))
print(b)
# 当然map底层运行逻辑并非简单的for循环,map的效率会更高,数据占用的资源更小。
现在将上面的代码改造成map方法:
def func(a): # 同样设置一个简单的函数, 传入一个a,返回 a + 1
return a + 1
# map方法映射函数,然后将list中vaule逐一传入func
b = map(func, [1, 2, 3, 4, 5, 6])
print(list(b)) # 返回的是结构体,需要转换类型后才可以看到真实的数据
输出:
[2, 3, 4, 5, 6, 7]
这么简单的函数,肯定不能少了用lamda来实现。
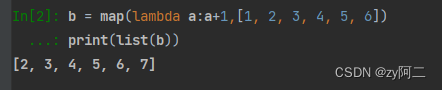
b = map(lambda a:a+1,[1, 2, 3, 4, 5, 6])
print(list(b))
# 输出的结果是一样的
输出:
[2, 3, 4, 5, 6, 7]
示例2: 爬虫
-
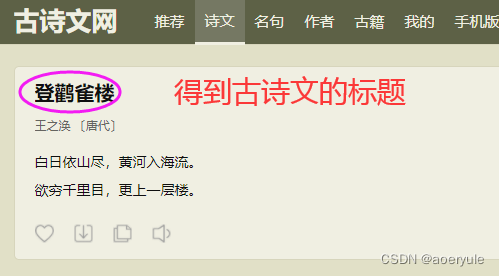
目标从父页面:
古诗文网(下手轻一点!)
- 得到所有子页面的链接地址
-
遍历所有子页面得到子页面中的标题,或其他数据。
import requests
import re
def func(url):
"""
爬虫函数,用re取页面中的古诗文标题并返回。re、requests库都看不懂的请先去学习Python的基础知识。
:param url: str 请求的地址
:return: str,爬取的数据,诗文的标题
"""
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.70'
}
resp = requests.get(url, headers=header)
# 用re取标题,加[0]是因为findall返回的是一个list取第一个索引
return re.findall(r'margin-bottom:10px;">(.*?)</h1>', resp.text)[0]
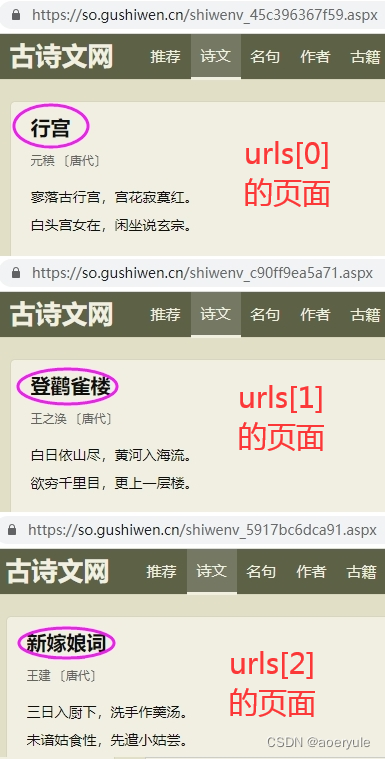
# 假定已经通过父链接得到所有的子链接list。
urls = ['https://so.gushiwen.cn/shiwenv_45c396367f59.aspx',
'https://so.gushiwen.cn/shiwenv_c90ff9ea5a71.aspx',
'https://so.gushiwen.cn/shiwenv_5917bc6dca91.aspx']
b = map(func, urls) # 用map函数,传入一个函数名和可迭代对象
print(list(b)) # 返回的是结构体,需要转换类型后才可以看到真实的数据
调试输出的结果:
['行宫', '登鹳雀楼', '新嫁娘词']
❤️ 如果对你有帮助~请关注我,让我们共同进步。
4. enumerate(),枚举、列举。
获得数组的索引和值,多用于在for循环中得到计数。
先用for循环来模拟enumerate()方法的作用,方便理解,示例1:
name = ['张三','李四','王五','赵六','周七']
for i in range (len(name)):
print(i, name[i])
改造成enumerate()方法
name = ['张三','李四','王五','赵六','周七']
for i,j in enumerate(name):
print(i, j)
调试输出的结果都是:
0 张三
1 李四
2 王五
3 赵六
4 周七
直接输出enumerate()的结果看看
name = ['张三','李四','王五','赵六','周七']
# 返回的是结构体,需要转换类型后才可以看到真实的数据
print(list(enumerate(name))) # 转换成list后,发现是一个二维的数组,在list中包裹了tuple
print(dict(enumerate(name))) # 转换成字典后,发现是一个键值对类型的结构。
调试输出的结果:
[(0, '张三'), (1, '李四'), (2, '王五'), (3, '赵六'), (4, '周七')]
{0: '张三', 1: '李四', 2: '王五', 3: '赵六', 4: '周七'}
拆字,示例2:
# 来数数txt中有多少个字吧!
txt = '夫何一佳人兮,步逍遥以自虞。魂逾佚而不反兮,形枯槁而独居。'
print('txt的长度为:', len(list(enumerate(txt))))
# 当然也可以用for循环遍历出每一个字符
for i, j in enumerate(txt):
print(i, j)
调试输出结果:
txt的长度为: 29
0 夫
1 何
2 一
3 佳
4 人
5 兮
6 ,
7 步
8 逍
9 遥
10 以
11 自
12 虞
13 。
14 魂
15 逾
16 佚
17 而
18 不
19 反
20 兮
21 ,
22 形
23 枯
24 槁
25 而
26 独
27 居
28 。
利用他提供序列的特性,来判断行数。示例3:
可能你会说统计文件的行数我可以这样写:
count = len(open(文件路径, 'r').readlines())
但是它的速度很慢,而且要重新打开一次文件特地读一次,而且当文件很大的时候还会出现卡死。这时利用enumerate()则方便许多。
len(list(enumerate(数据)))
END ,感谢您阅读。❤️ 如果本文对你有帮助~请关注我,让我们共同进步。