PCB(Part-based Convolutional Baseline)
参考链接:
Re:从零开始的行人重识别(五)
RPP结构图:
毕设项目演示地址:
链接
毕业项目设计代做项目方向涵盖:
目标检测、语义分割、深度估计、超分辨率、3D目标检测、CNN、GAN、目标跟踪、竞赛解决方案、人脸识别、数据增广、人脸检测、数据集、NAS、AutoML、图像分割、SLAM、实例分割、人体姿态估计、视频目标分割、Re-ID、医学图像分割、显著性目标检测、自动驾驶、人群密度估计、PyTorch、人脸、车道线检测、去雾 、全景分割、行人检测、文本检测、OCR、6D姿态估计、 边缘检测、场景文本检测.
网络流程:
-
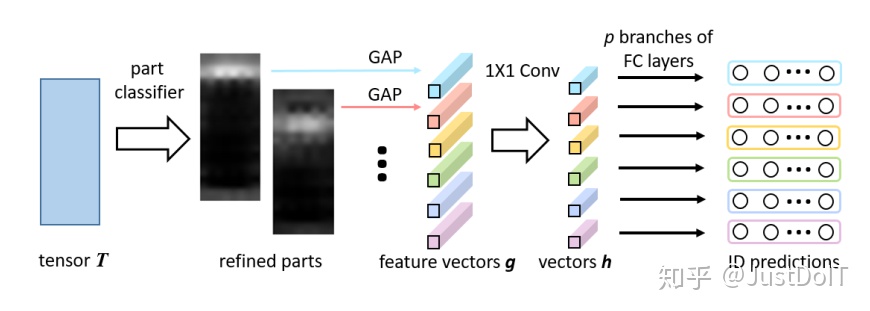
经过一个backbone得到特征图T。T中的每列向量称为f(1,1,c)。
如:输入(384,128,3)经过backbone降采样16倍后得到特征图T(24,8,c)。
-
将T从上到下切成p(p=6)片。记为P_i(i=1…p)。——测试时接第3步,训练PCB时接第4步
-
RPP(Refined Part Pooling)
-
每个f接同一个1×1卷积+softmax,得到该f属于每个P_i的概率
P(P_i|f)
。 -
计算每个P_i特征图。
T中所有的f
都计算其属于P_i的概率
P(P_i|f)
,然后与各自的f相乘,最终得到一个与T相同大小的特征图P_i(24,8,c),即上图中的refined parts,计算过程如下式,×指逐像素相乘。
Pi
=
{
P
(
P
i
∣
f
)
×
f
,
∀
f
∈
T
}
P_i=\{P(P_i|f)×f,\forall f\in T\}
P
i
=
{
P
(
P
i
∣
f
)
×
f
,
∀
f
∈
T
}
-
对每个P_i(即图中每个refined parts)进行GAP(全局平均池化)得到g_i(1,1,c)。
-
-
每片都进行平均池化,得到p个列向量g_i(1,1,c)。
-
p个g_i经过
同一个
1×1卷积降维得到p个h_i(1,1,ch)
ch<c
。 -
p个h_i
分别
接FC+softmax得到该输入图片的ID。这里每个h_i后面接的分类器是不一样的。
为什么要加RPP
因为步骤2是强制
硬切片
,很有可能P_i的部分f不属于P_i,和P的其他部分更相似,如果将其纳入P_i进行平均池化,显然会对预测结构有影响,因此通过RPP进行
软切片
,更加合理。其实RPP类似与
注意力机制
。
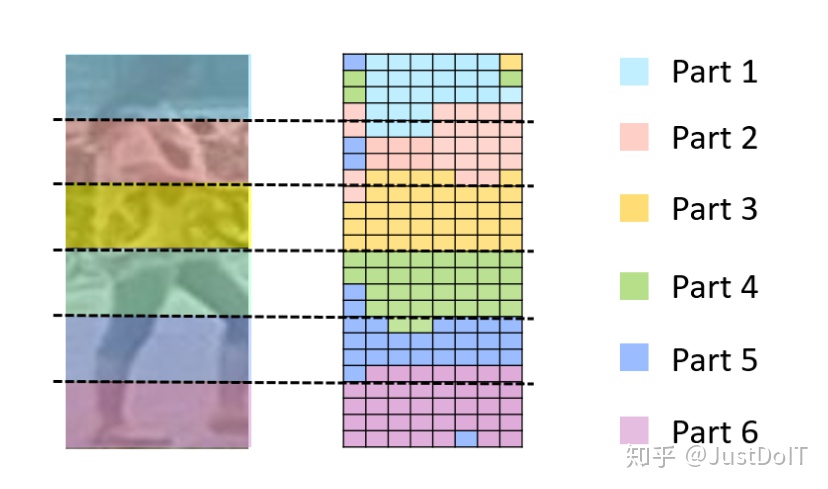
上述问题的实验证明如下图所示:
(这里只是验证硬切片的问题,继而引出RPP,对于训练是没有意义的)
-
定以一个相似度度量标准。
计算各个f与每个g_i直接的余弦距离,f离哪个g_i最近,就将f归为第P_i。如上图所示,反映了每个f所属的Part。
-
从上图可以看出,硬分类下,同一个part内大部分都是近似的,但有个别异常点不属于该part,和其他part更相似。
-
因此,这些异常点更应该参与其他与其更相似的part特征图,而不是当前硬分类对应的part。所以使用RPP的软分类,直接用全局所有的f生成对应位置的part,类似增加了注意力机制来获得每个part的特征图。
训练过程:
-
训练PCB结构图至收敛,模型为
1->2->4->5->6
。 -
将T后面的average pooling去掉,改成RPP结构,即添加用于区分f所属P_i概率的分类器(part classifier)和GAP,模型为
1->2->3->5->6
。 - 固定PCB中除RPP结构外的所有参数,在相同数据集下继续训练至收敛。也就是只训练part classifier分类器的参数。
- 解冻3中固定的PCB参数,使所有网络参数都可训练,继续在相同数据集上微调即可。
实际运用
-
图片输入后,只取g或者h,将所有的p个g或者h拼接为描述子G或者H,用来计算与其他图片之间的距离,进而筛选出最相似的对象,实现ReID。即描述子为
G=
[
g
1
,
g
2
,
.
.
.
,
g
p
]
o
r
H
=
[
h
1
,
h
2
,
.
.
.
,
h
p
]
G=[g_1,g_2,…,g_p] \ or H=[h_1,h_2,…,h_p]
G
=
[
g
1
,
g
2
,
…
,
g
p
]
orH
=
[
h
1
,
h
2
,
…
,
h
p
]
G维度更大,计算量较大但效果更好,H计算量较小效果可能较差。
为什么work
- RPP可以学习出,原始图片每个像素(也就是T中的f向量)属于6个part中的哪一部分,从而与part对应起来,使得后面的特征向量g或h更加准确。
- 对于同一个人,有的图片可能包含了整个人身体,而有的图片只包含了半个身子。那么,通过RPP,半身图片的f大多都归到了上三个part,下三个part响应很低。即半身图的上三个part和全身图的上三个part非常相似,容易匹配成功,下三个part匹配结果不稳定。
- 总的来说,就是提取出图片的6个局部特征,然后根据局部特征的距离判断类别,最终利用投票法确定该图片的ID。
注意点
- 只使用了分类损失(softmax loss)进行feature embedding(即测试时用于相似度查找的特征向量)的学习。
改进思考:
- 在feature embedding后添加triplet loss,和softmax loss共同优化feature embedding。
相似度度量方法
欧氏距离
存在量纲不一致的情况,不建议使用
余弦距离
也就是1-特征向量之间的余弦夹角,所以值越大越不相似。
d
i
s
=
1
−
a
∗
b
∣
a
∣
∗
∣
b
∣
dis = 1 – \frac{a * b}{|a|*|b|}
d
i
s
=
1
−
∣
a
∣
∗
∣
b
∣
a
∗
b
Re-Ranking
参考链接:
Re-Ranking图解(易于理解)
图解:

如上图所示,步骤为:
- 给定一个probe,从图片集gallery中找出与它相似的图片。
- 拿这些图片分别当做probe再进行查询,得到k个与其相似的图片。
- 如果其中k近邻包含之前的probe对象,说明该对象为真实对象的可能性就比较大。
rerank步骤
- 已知目标(probe)与搜索出来的前20个匹配结果(gi)的余弦距离Di
- 再计算probe与gi的杰卡德距离Dj
- 加权Di,Dj作为probe和gi的最终距离,并根据这个距离对gi重新排序
杰卡德距离计算方法:
不会:大致思路就是根据待检测图片得到了多个候选图,如果再根据候选图去进行检索,其中包含了最开始的待检测图片,那么该候选图和间检索图片之间的距离就应该越小
根据原图利用余弦距离找出距离其最近的20个图,再找出这20个图最近的6个图,判断这6个图中原图所在的位置,共同得到该图的索引模型
余弦距离+Jaccard距离
triplet loss
参考链接:
为什么triplet loss有效?(原理+本质分析)
要解决的问题:
-
分类问题中,很多时候类别数量是巨大的,尤其是在面部识别、行人重识别中,ID数将会是成千上万的,直接使用softmax这种分类方法,那么最后的分类层
参数量非常的大
。 -
所以,对于这种类别数量巨大的情况,不再直接预测得到他们的类别,而是得到每个图片的特征(一般就是最后的FC分类层前面那个FC层),然后尽可能的让
同类样本的特征更加相近,不同类样本的特征更加远
。 -
在预测时,直接根据预测图片和数据库中图片的特征,计算之间的距离,接着使用
KNN选择距离其最近
的样本类别即可完成分类。
原理
-
在triplet loss中,我们会选取一个三元组,首先从训练集中选取一个样本作为Anchor,然后再随机选取一个与Anchor属于
同一类别
的样本作为Positive,最后再从
其他类别随机
选取一个作为Negative(因此三元组简称
apn组
)这里将样本的feature embedding记为
x
,那么一个基本的三元组triplet loss如下:
lt
r
i
=
m
a
x
(
d
a
,
p
−
d
a
,
n
+
α
,
0
)
l_{tri}=max(d_{a,p}−d_{a,n}+α,0)
l
t
r
i
=
ma
x
(
d
a
,
p
−
d
a
,
n
+
α
,
0
)
da
,
p
=
∥
x
a
−
x
p
∥
a
n
d
d
a
,
n
=
∥
x
a
−
x
n
∥
d_{a,p}=∥x_a−x_p∥\ and d_{a,n}=∥x_a−x_n∥
d
a
,
p
=
∥
x
a
−
x
p
∥
an
d
d
a
,
n
=
∥
x
a
−
x
n
∥
-
从上式可以看出,triplet loss 的优化目标为:同类别样本的特征距离尽量的小,不同类样本的特征距离尽量大。其中α为margin(边界距离),指不同样本间的特征距离至少为α,越大越难以收敛。
改进版(难样本采样三元组)
参考链接:
Margin Sample Mining Loss(参考其-难样本采样三元组损失-部分)
改进思路:
-
选取三元组时,不再随机选择,而是:将距离Anchor
距离较大的同类样本
作为Positive,距离Anchor
距离较小的其他类别
作为Negative。 -
距离计算方法:
-
直接计算输入图片两两之间的欧氏距离,也就是直接利用像素值求的距离。(具体计算方法还不清楚,只知道是自定义的距离计算方法即可,并不是输入网络得到feature embedding计算距离)。
- 将一个batch的图片都输入网络得到各自的feature embedding,同损失中的距离计算一样计算其距离。
-
实现过程:
-
对于每一个训练batch,随机挑选P个ID 的行人,每个行人再随机挑选K张不同的图片,如果不足K张就
重复提取
。也就是一个batch有
P×K张
图片。 -
将P×K个图片全部
输入网络得到P×K个feature embedding
,进而获得图片
两两之间距离d
。 -
对于batch中的每一个样本a,都可以得到他的困难正样本p和困难负样本n,得到一个apn三元组,计算出该apn组的损失;那么这个batch就有
P×K个apn三元组
,P×K个
损失的平均值
就为该batch的损失,用于调整网络参数。损失计算方法为:
lo
s
s
=
1
P
×
K
∑
a
∈
b
a
t
c
h
(
max
P
∈
A
d
a
,
p
−
min
n
∈
B
d
a
,
n
+
α
)
loss = \frac{1}{P×K}\sum_{a\in batch}{(\max_{P\in A}{d_{a,p}}-\min_{n\in B}{d_{a,n}}+α)}
l
oss
=
P
×
K
1
a
∈
ba
t
c
h
∑
(
P
∈
A
max
d
a
,
p
−
n
∈
B
min
d
a
,
n
+
α
)
其中A为与a相同ID的所有样本,B为其余不同ID的样本。
实际运用
问题:
- 单独使用triplet loss虽然可以让类内聚类+类间分离,但训练相对困难。
- 逐个batch的训练,可能导致不同batch同ID得到的feature embedding也不同,不利于后续的分离。
triplet loss+softmax loss
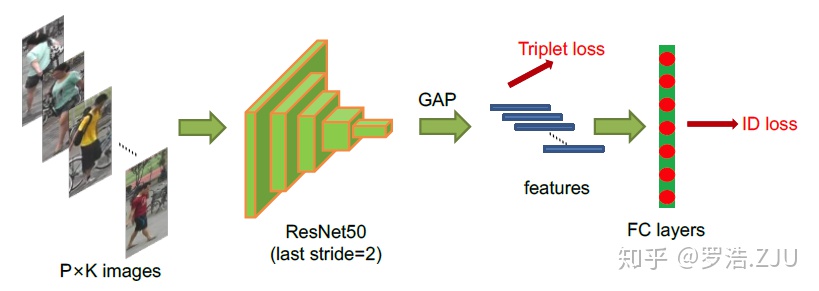
在训练时,加入softmax层,用于回归ID的类别损失,如下图所示:
原理:
- 每个batch经过GAP之后会得到P×K个feature embedding,利用这些feature embedding计算triplet loss。使得这些feature embedding类内聚合+类间分离。
- 每张图片的feature embedding后都接一个FC+softmax层,用于回归该图片的ID。使得所有(不同batch之间)相同ID图片的feature embedding大致相似。
- 测试时,依然只使用feature embedding部分,后面的FC层不需要。
优点:
- ID loss的存在使得每类的feature embedding离散程度变低,更加易于triplet loss 的训练
MGN(Multiple Granularity Network)
论文:
Learning Discriminative Features with Multiple Granularitiesfor Person Re-Identification
目标:
- reID数据集规模小且多样性若,一些不显著的信息很容易在全局特征提取中忽略,使得全局特征无法具有类内聚类+类间远离的特性。
- 因此,MGN引入了行人的局部信息,将全局信息和局部信息结合,进而实现特征的多样性,用于相似度查找。
网络流程
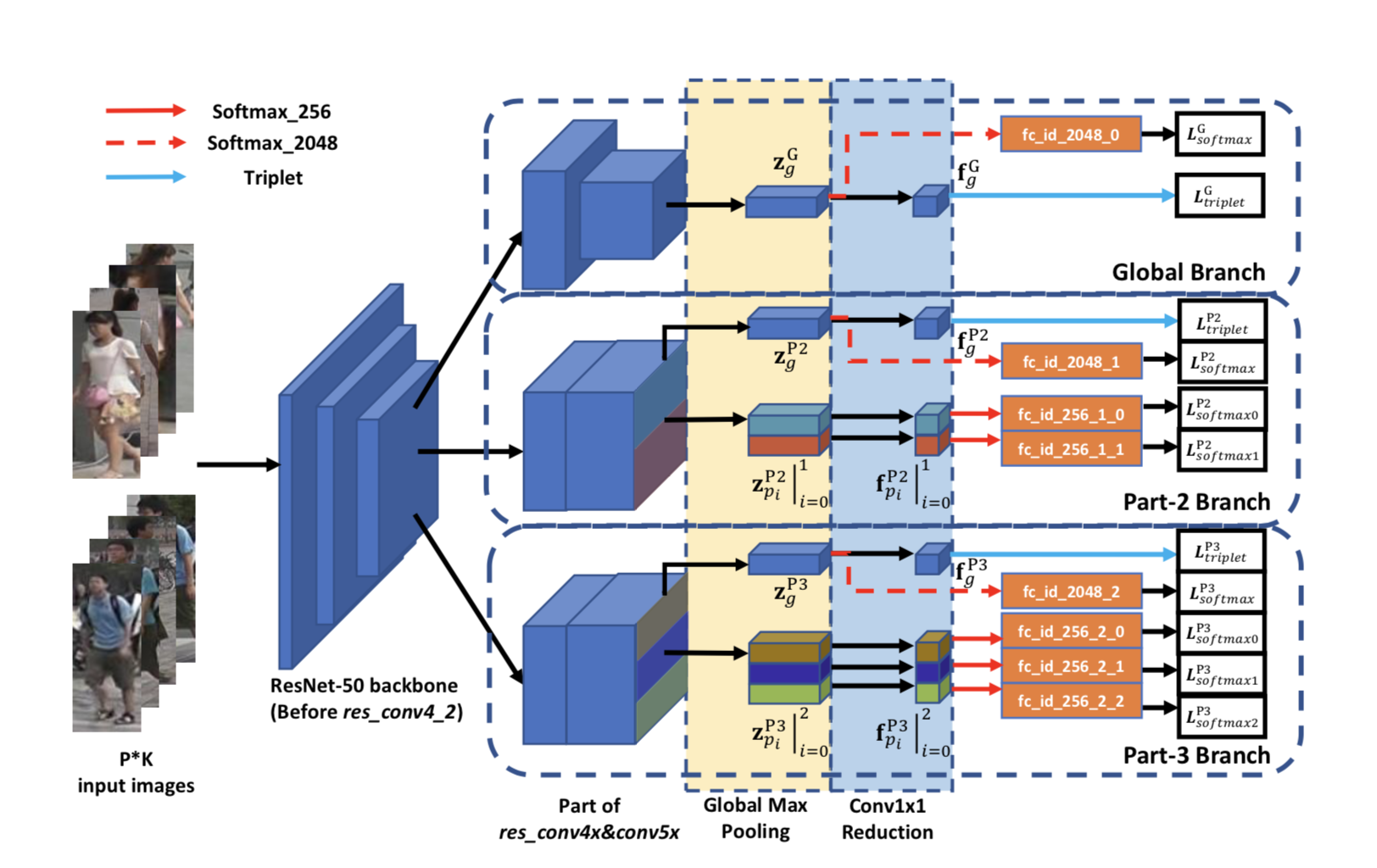
模型结构如下图所示:
-
backbone提取特征图。
-
特征图接三个分支。
-
第一个分支只提取全局信息。
GAP后接1×1卷积得到feature embedding(记为f)。GAP接一个FC+softmax用于计算分类损失;f用于计算triplet损失。
-
第二个分支提取局部信息。也分为两个分支,将特征图硬分为上下两部分,可以理解为把人划分为上半身和下半身。
- 第一个分支。同2.1直接GAP+1*1卷积+triplet loss和GAP+FC+softmax loss。
- 第二个分支。平分为上下两部分,分别接GAP+1×1卷积得到两个feature embedding,这两个局部信息的f后接FC+softmax计算分类损失。
-
第三个分支也提取局部信息。也分为两个分支,将特征图硬分为三个部分,可以理解为吧人划分为上中下三部分。
- 第一个分支。同2.1直接GAP+1*1卷积+triplet loss和GAP+FC+softmax loss。
- 第二个分支,平分为上中下三部分,分别接GAP+1×1卷积+FC+softmax loss。
-
实际运用
- 图片输入后,得到3个全局feature embedding和5个局部feature embedding,假设都是256维。把这8个feature embedding直接concat一起得到一个2048维的特征向量,用于相似度的度量。
注意点
- 只有三个全局feature embedding,使用了triplet loss。其他的局部feature embedding都是使用softmax loss优化的。
改进思考:
-
全局和局部feature embedding使用不同的loss,会不会使得量纲不一致,且分布也不一致,影响效果。
全部feature embedding都使用triplet loss+softmax loss进行优化。
ReID strong baseline(旷视研究所)
参考链接:
一个更加强力的ReID Baseline
以下全部内容来自对该链接的总结,具体不懂参考该链接。
目标:
- 只使用全局特征,不考虑任何局部特征。
- 通过各自trick提高性能。
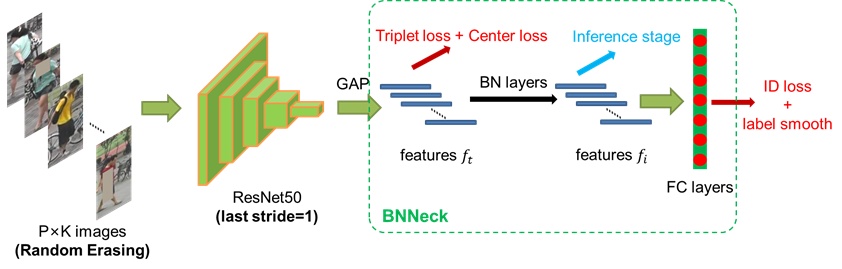
网络流程
模型结构图如下:
-
backbone提取特征。
-
GAP得到第一个feature embedding(记为
ft
f_t
f
t
)。使用triplet+center loss优化
ft
f_t
f
t
。 -
ft
f_t
f
t
后接BN层得到第二个feature embedding(记为
fi
f_i
f
i
)。 -
fi
f_i
f
i
后接FC+softmax进行ID分类。使用分类损失+label smooth优化
fi
f_i
f
i
为什么引入BNNeck
实验经验所得:
-
**现象:**如果不加BN层,只使用
ft
f_t
f
t
,由于triplet和ID损失同时优化同一个
ft
f_t
f
t
,会出现这两个loss不会同步收敛。出现一个loss一致下降,另一个loss先增大在下降的情况,即两个loss的梯度方向不一致。 -
triplet loss适合在自由的欧式空间里约束,即用于优化
没有BN归一化
的
ft
f_t
f
t
,自由区域较大,triplet loss更容易把正负样本拉开。 -
ID loss适合在归一化后的超球面里约束,即用于优化
BN归一化
后的
fi
f_i
f
i
,在该超球面内更易进行分类。 - 因此,triplet loss和ID loss分别约束不同的feature embedding,而非同一个。实现训练过程中两个loss梯度的一致下降。
center loss
????
label smooth+ID loss
目的:
通常情况下的标签都是
[0,0,1,0,0,0]
这种非常极端的约束,为了缓和label对网络的约束,提高模型的
泛化能力,减少过拟合
的风险。
方法:
对标签做一个平滑处理,公式如下:
q
i
=
{
1
−
N
−
1
N
ϵ
i
f
i
=
y
ϵ
/
N
o
t
h
e
r
w
i
s
e
q_i= \begin{cases} 1-\frac{N-1}{N}\epsilon&if\ i=y\\ \epsilon/N&otherwise \end{cases}
q
i
=
{
1
−
N
N
−
1
ϵ
ϵ
/
N
i
f
i
=
y
o
t
h
er
w
i
se
也就是说,若
label=[0,0,1,0,0,0]
,那么N=5(这里label包含了背景类,所以有6维)。若定义
ϵ
=
0.1
\epsilon=0.1
ϵ
=
0.1
,那么带入上面公式就可以得到,平滑后的label为
[0.02,0.02,0.9,0.02,0.02,0.02]
。
-
同时损失函数ID loss,由
交叉熵变为相对熵
。???存疑,建议参考《109_label smooth详解.md》相对熵的计算方法为=交叉熵-信息熵
实际运用
使用
f
t
f_t
f
t
或
f
i
f_i
f
i
都可以用于相似度度量。下面是使用不同度量方法(欧氏距离和余弦距离)和不同特征的对比表:
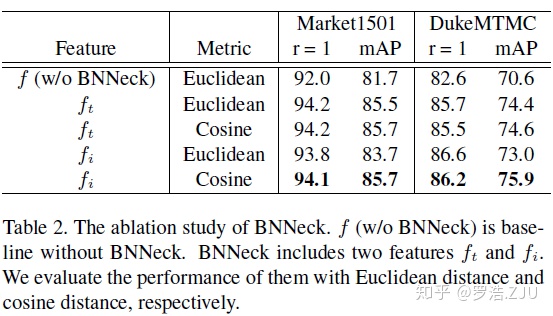
原作者建议
使用
f
i
f_i
f
i
+余弦距离
的方案。
网络对比
PCB VS MGN
| 模型\特征 | 全局信息 | 局部信息 | loss |
|---|---|---|---|
| PCB | No | 平分6段 | softmax |
| MGN | GAP | 2段和3段并连 | 全局triplet、局部softmax |
| ReID strong baseline | GAP | No | triplet+ID loss结合 |
思考
- 主框架为ReID strong baseline,提取全局特征。
- 引入PCB的RPP结构,提取局部特征(但损失改为triplet+ID loss)
- 局部特征和全局特征concat进行相似度度度量。