本篇所有代码都可以在我的
Github
找到!
文章目录
准备
-
一点点
python
基础 -
PyCharm
编程工具
成果展示
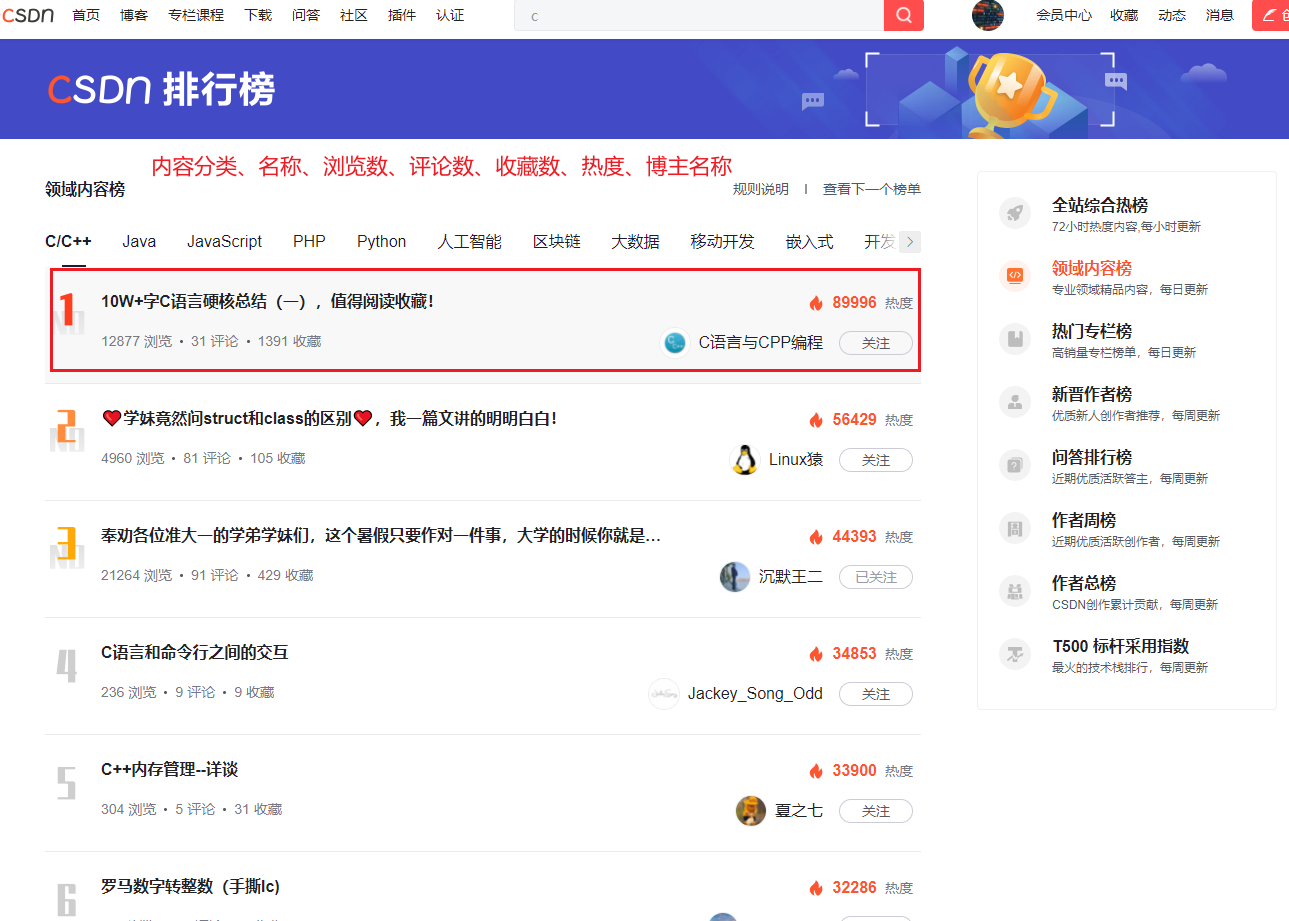
先展示下本次我们的爬虫成果
C/C++
热榜共有101篇博文入选,恭喜各位大佬!

开始
需求分析
我们的目标是爬取
CSDN
热榜上的文章信息。
具体字段为
- 内容分类
- 博文名称
- 博文链接
- 浏览数
- 评论数
- 收藏数
- 热度
- 博客名称
- 博客链接
进一步,我们还可以爬取热门博客的内容详情,博客的关注人数等等,不过这一次我们先不做。
网页分析
这里阿晨要说几句,网页分析最重要的不是技术,而是用好工具。其实网页很简单(除了特别变态加密的),零基础成为大神的比比皆是,要知道,网页是给人看的,所见即所得,我们只是用代码代替了人眼而已。
而且现在的网站大多是前后端分离的架构,前端负责渲染数据,后端负责提供数据,这些数据大部分都是
json
的。如果是
json
的数据结构,那么我们写起爬虫来将会异常轻松。不过为了演示爬虫的通常分析手段。阿晨先用分析网页元素的方式分析,后面再告诉大家直接访问接口的方式。
工具
这里用到的工具,阿晨也罗列了一下。
-
Chrome
浏览器
-
XPath Helper
xpath
调试神器,安装地址:https://chrome.google.com/webstore/detail/xpath-helper/hgimnogjllphhhkhlmebbmlgjoejdpjl
-
Postman
接口测试工具
很方便的进行接口调试或者网页元素调试,因为有时候网页加密的话,我们很难肉眼分析出加密逻辑,而适用Postman来进行调试,事半功倍!

好了,接下来就让阿晨带你好好分析下
CSDN
的热榜(阿晨也会将自己的摸索和想法毫无保留的分享出来)
网页元素分析法
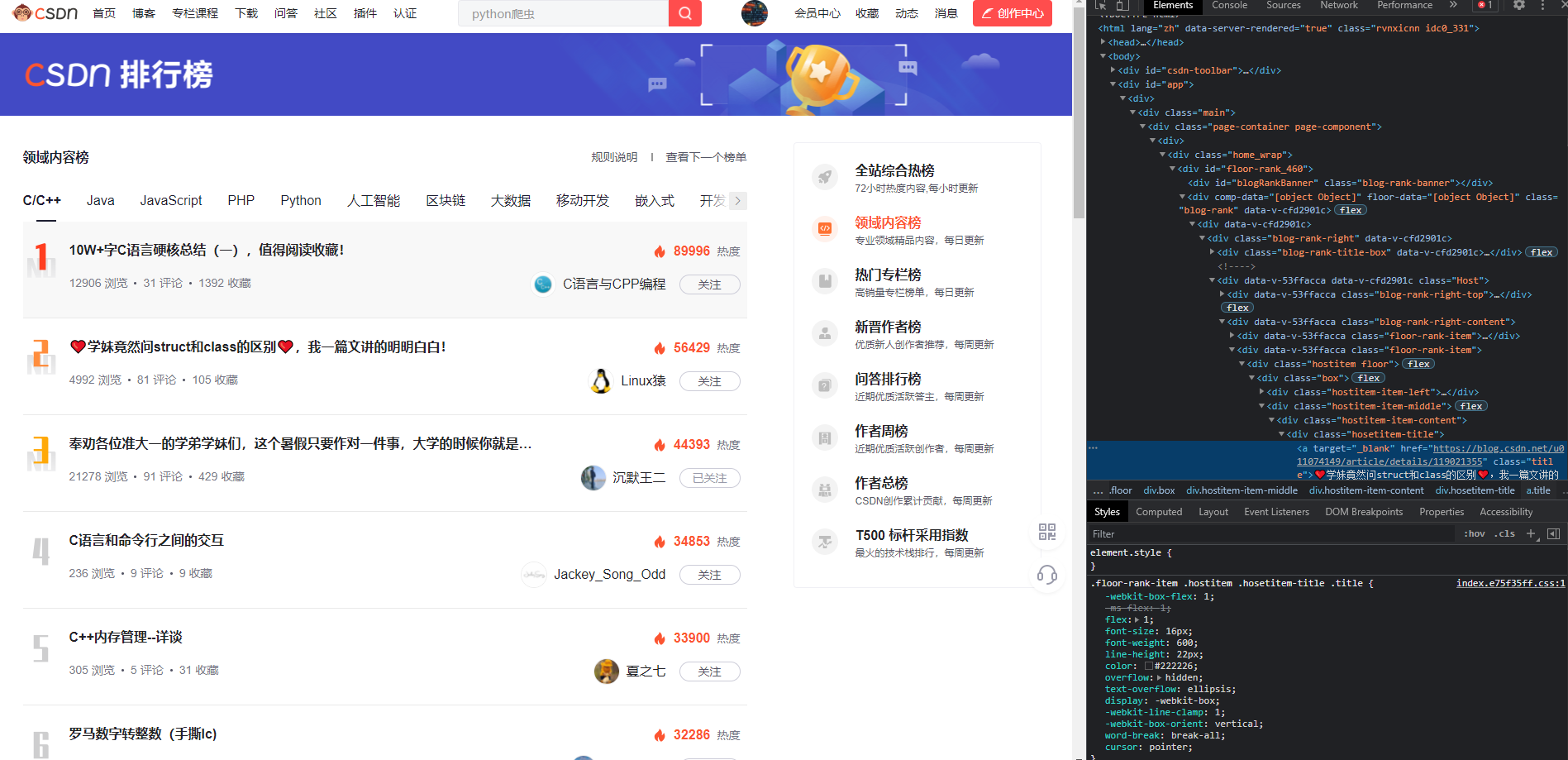
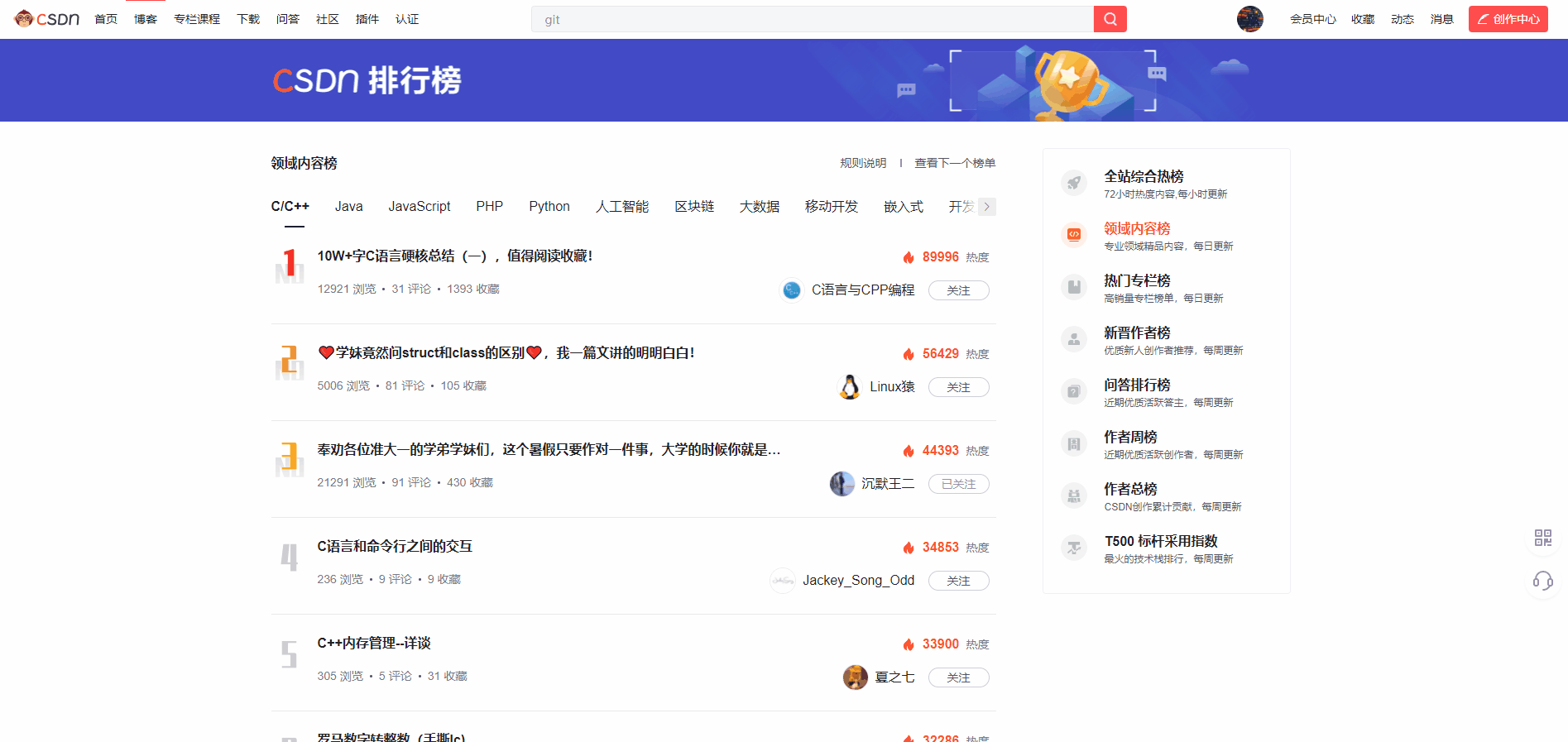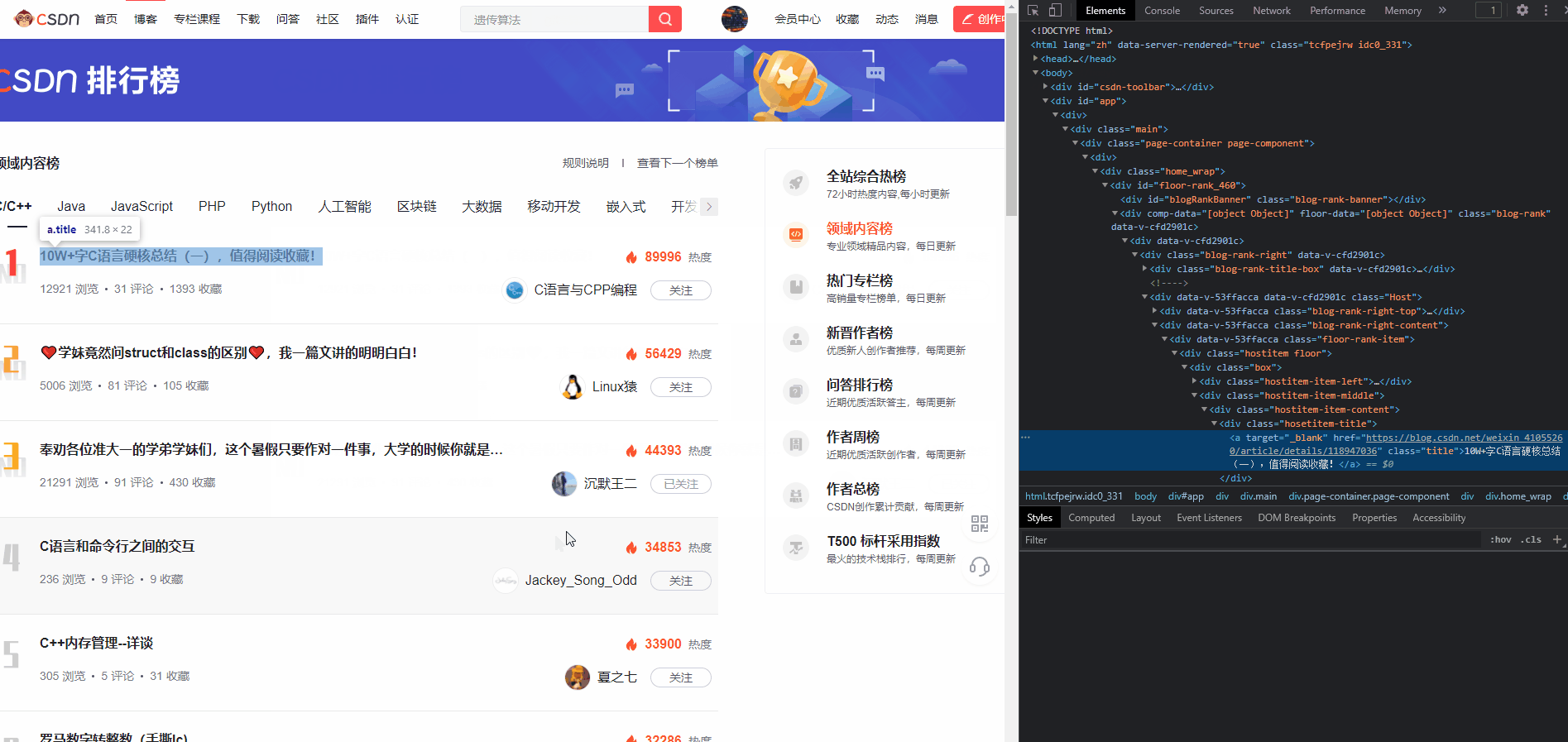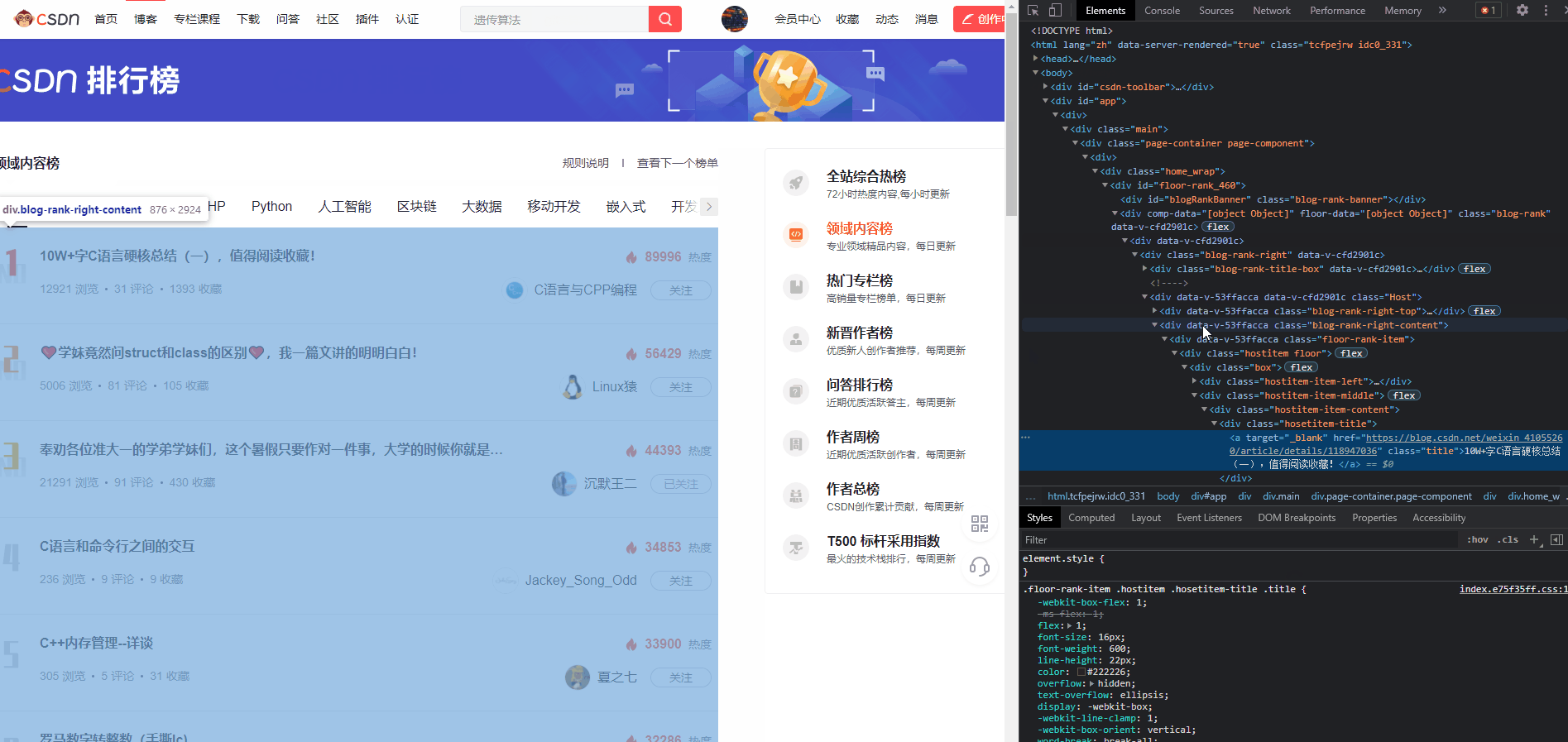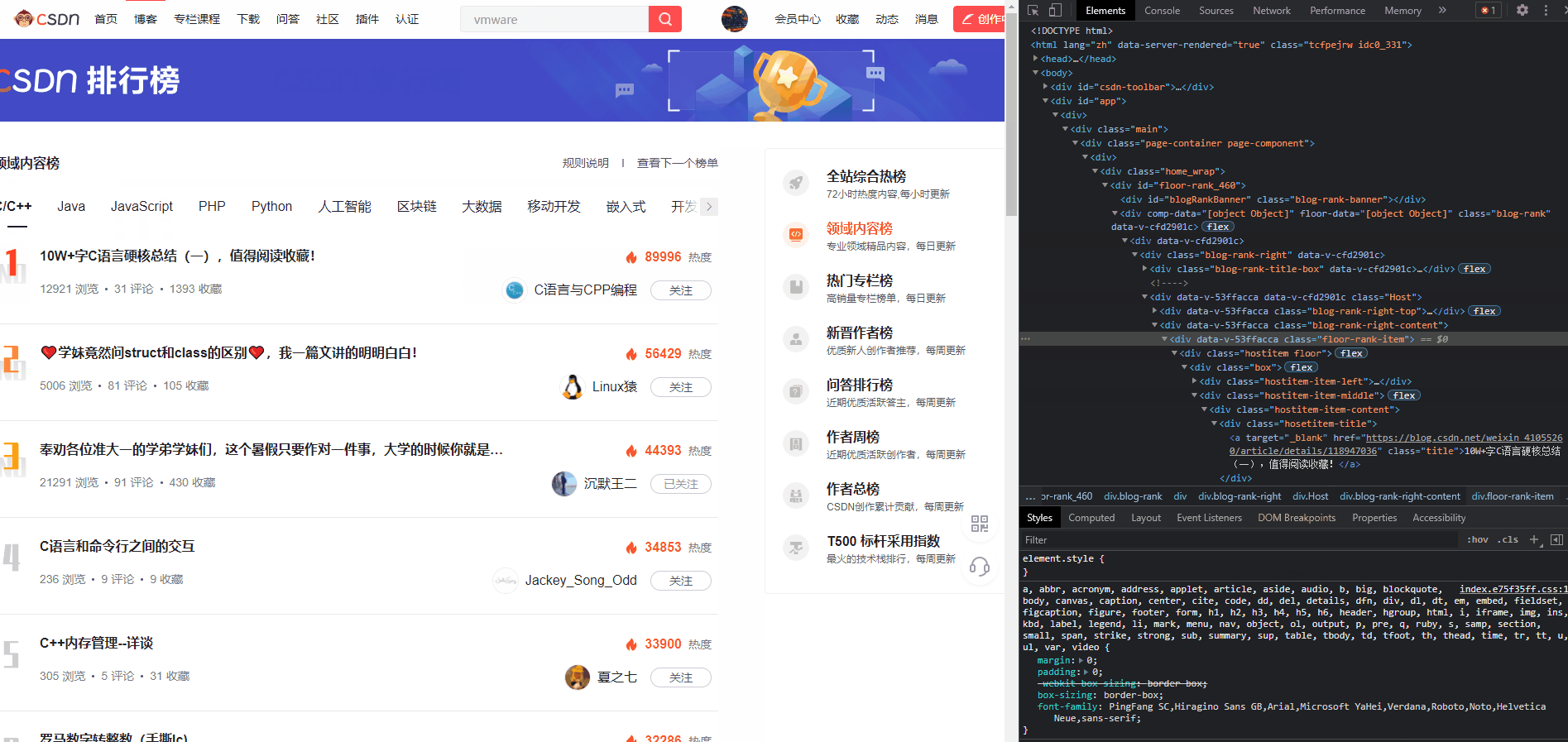
1、选中我们要的元素 -> 右键 -> 检查
最常用的就是Chrome浏览器的元素分析功能,需求上显示是一个分页列表,而我们要的内容全部都在列表的每一个item里。
我们在这一步要做的就是,分析需求里提及的所有字段,是否能使用
xpath
描述出来
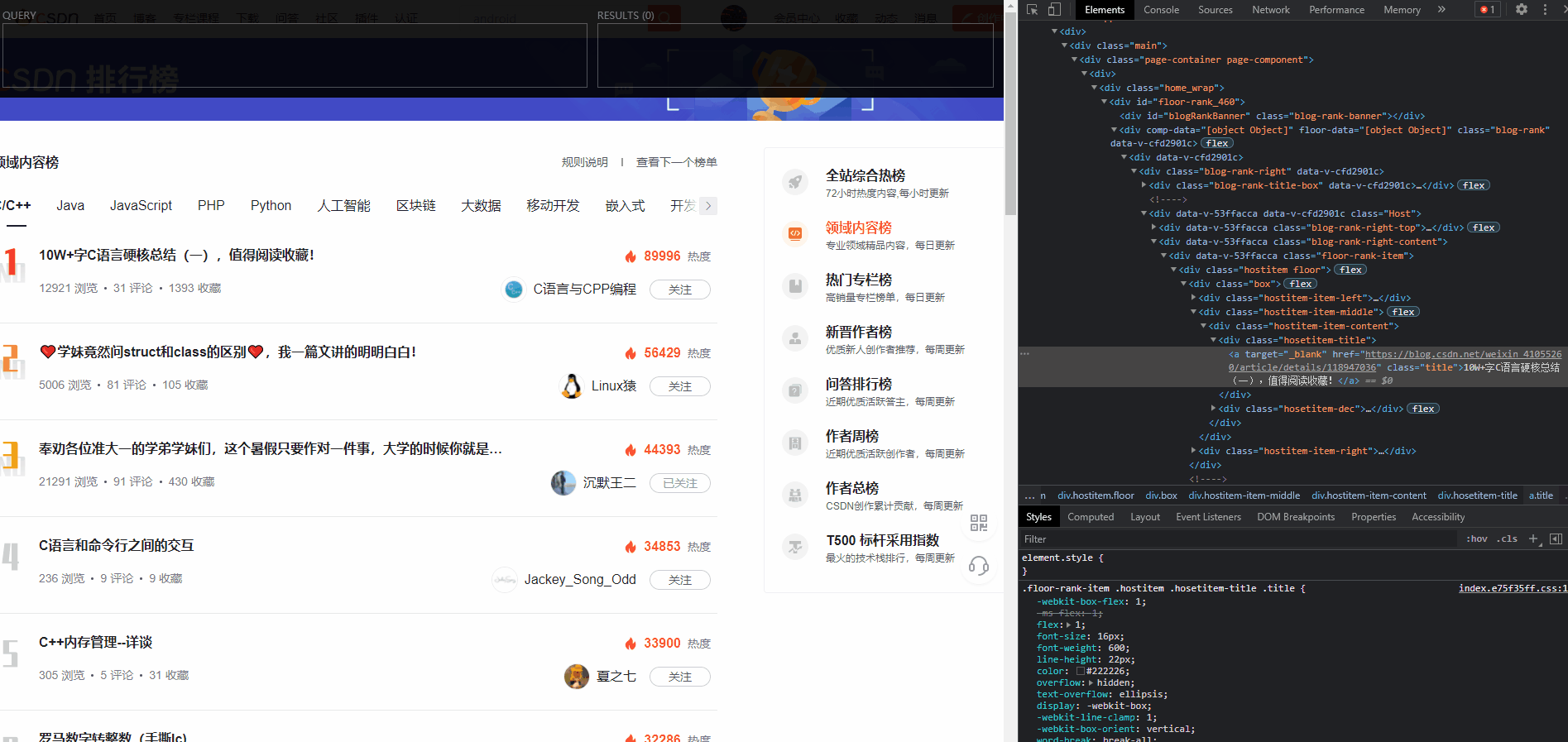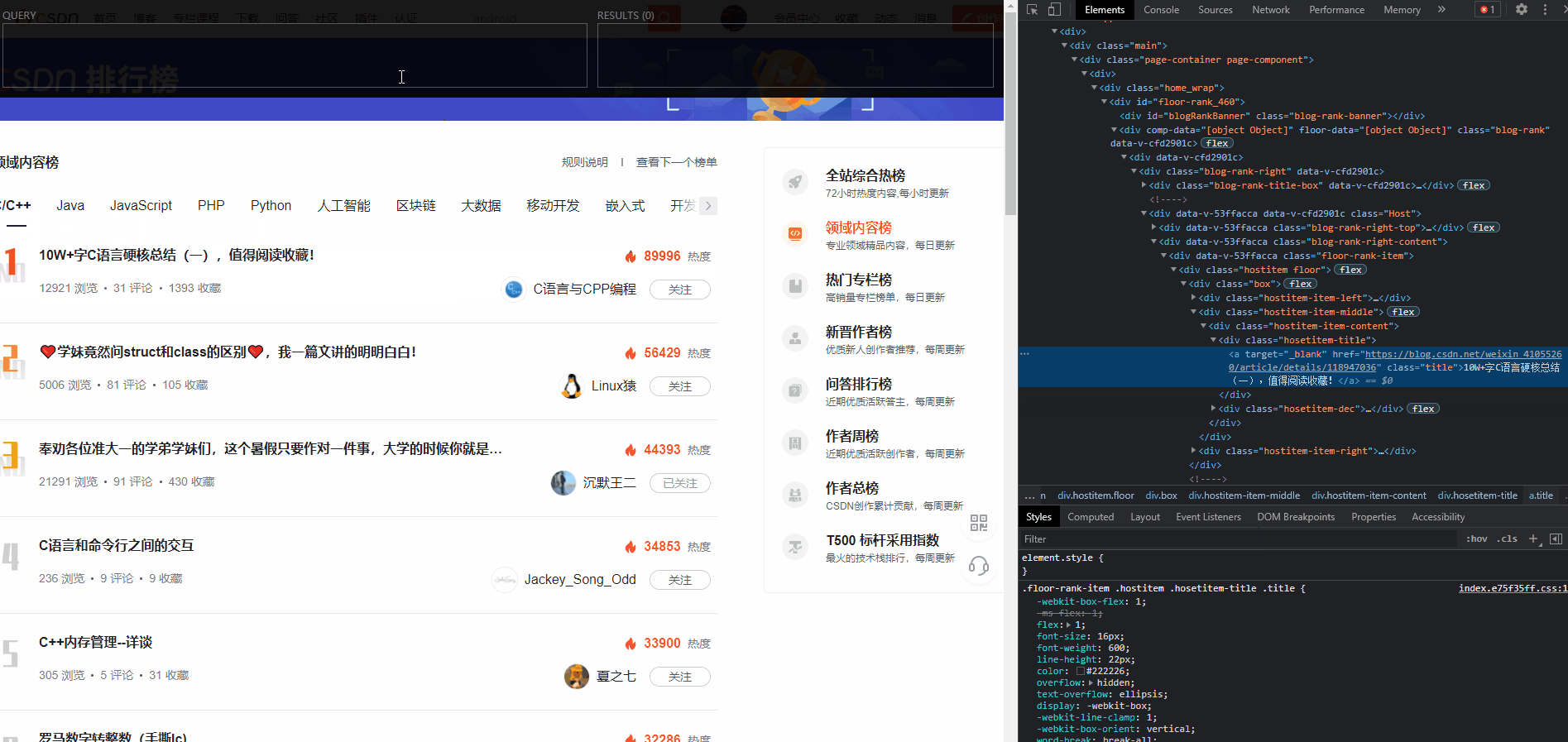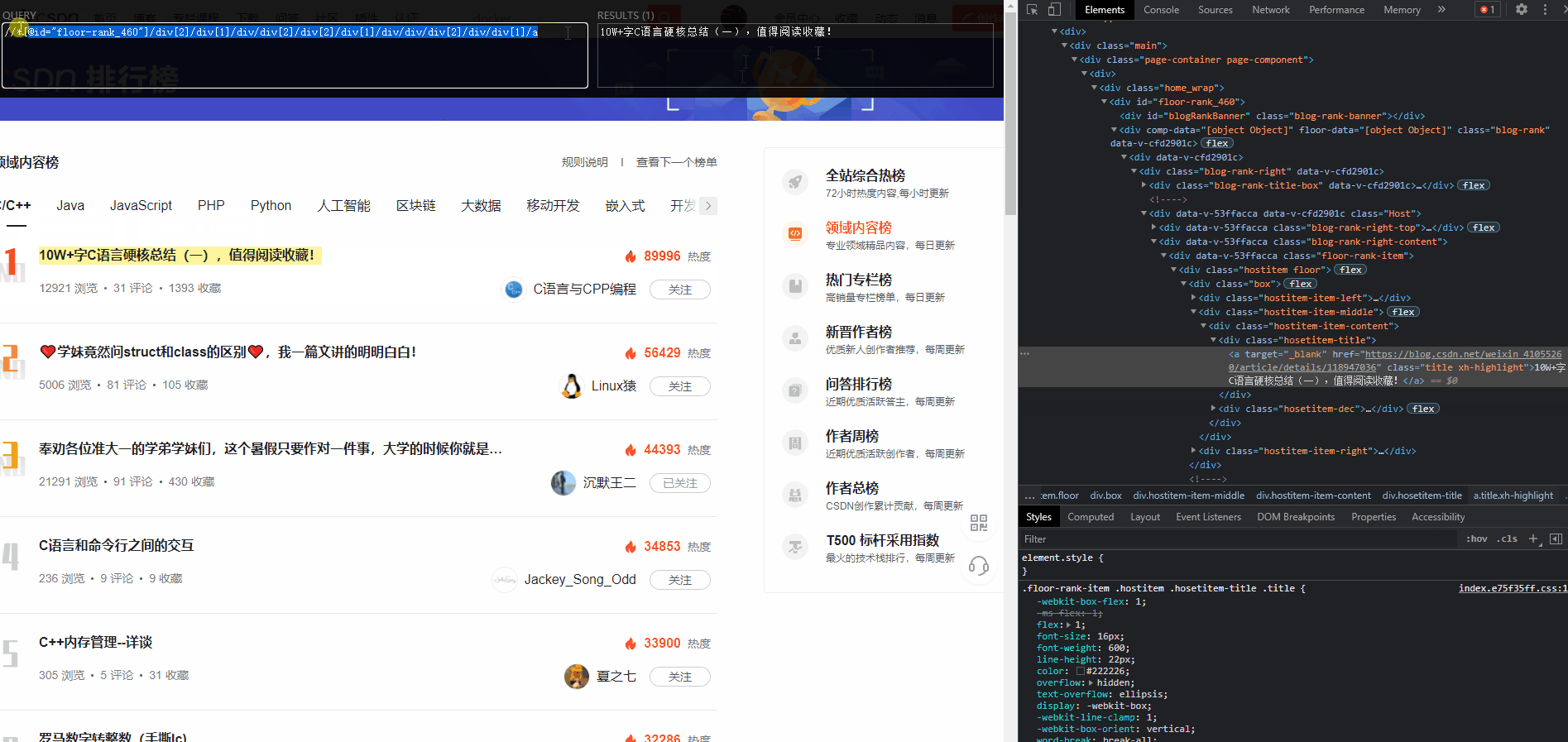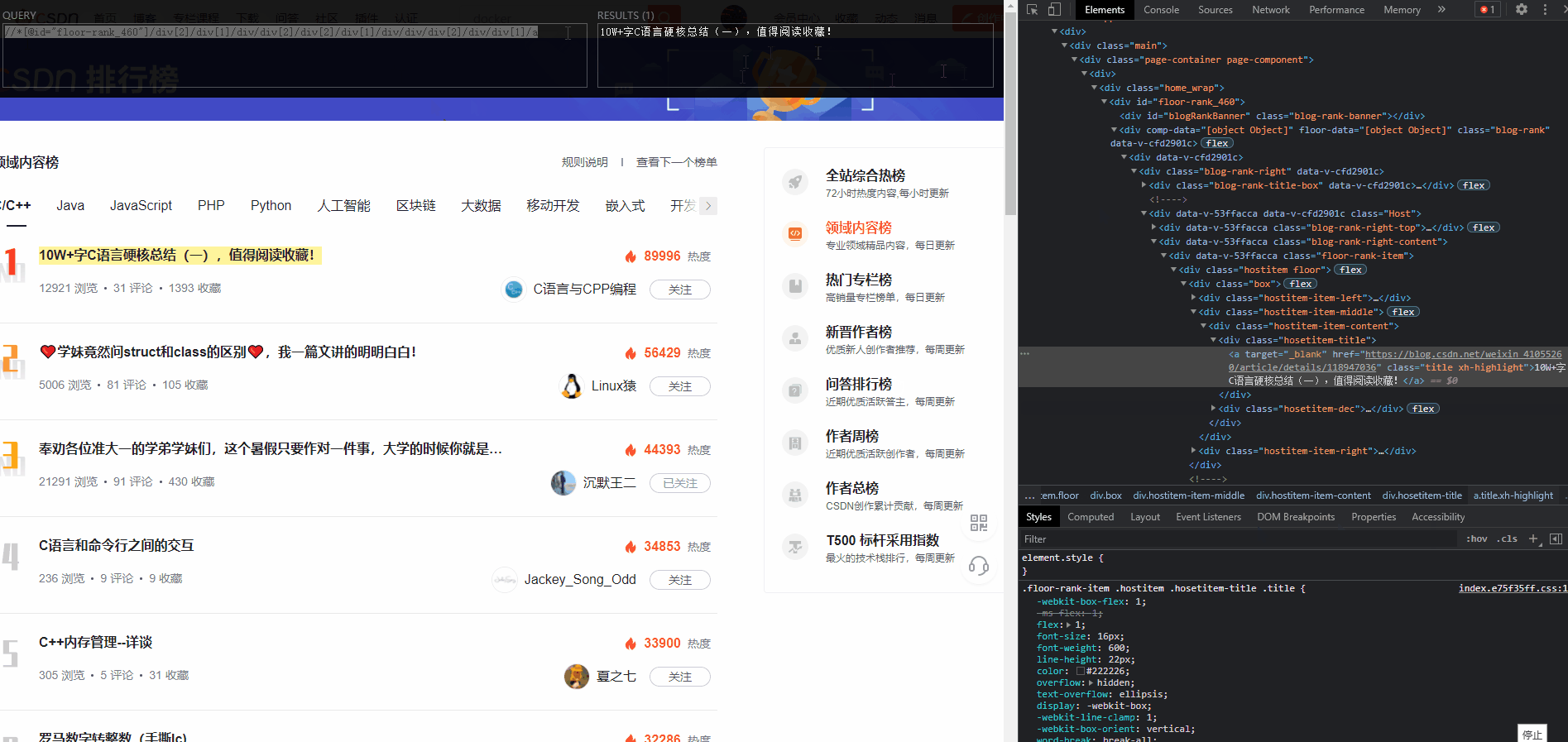
2、在右侧控制台中,分析元素结构
在这一步中,我们需要将
xpath
都分析出来
不过这个
xpath
一般无法直接使用,我们还需要进一步分析,然后不停地使用
XPath Helper
进行测试。
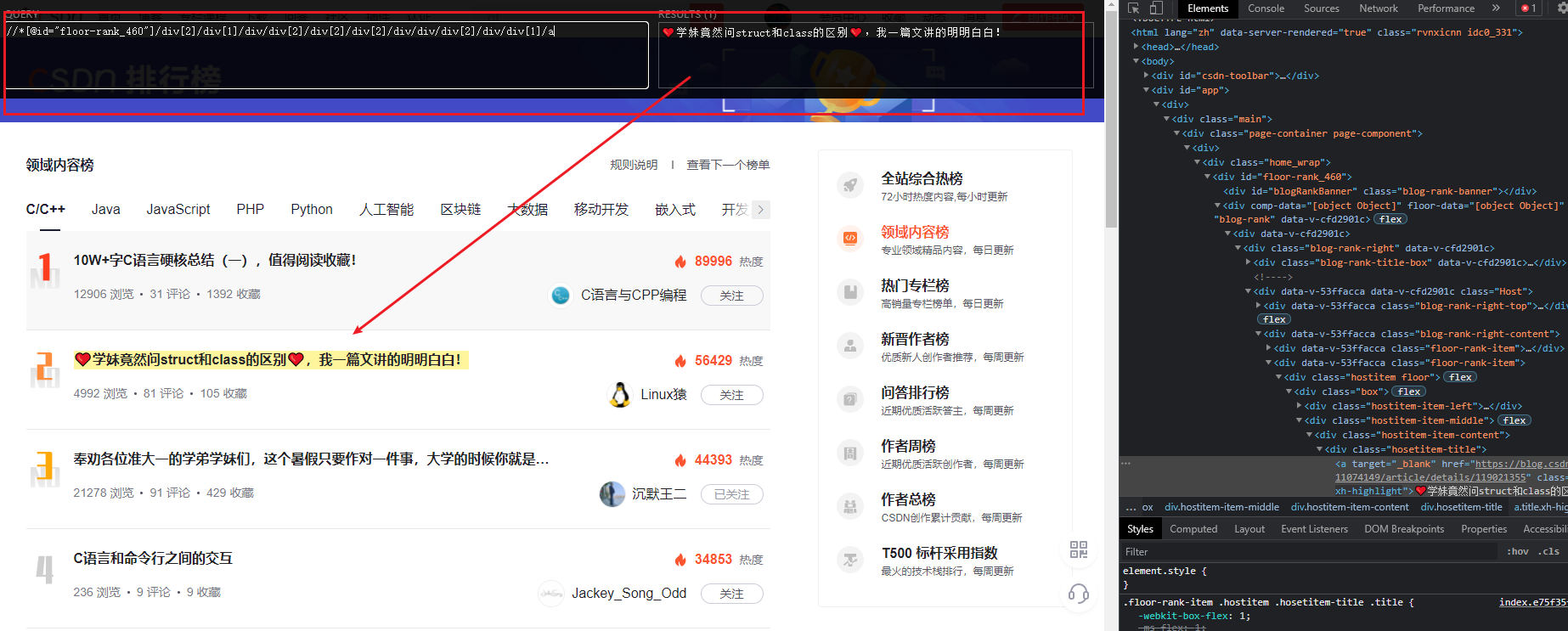
//*[@id="floor-rank_460"]/div[2]/div[1]/div/div[2]/div[2]/div[1]/div/div/div[2]/div/div[1]/a
阿晨就用简单的文章标题,做个演示
3、我们注意到,博文标题在这个页面中,有唯一的标识
class=hosetitem-title
class=hosetitem-title
我们尝试将
xpath
写成
//*[@id="floor-rank_460"]//*[@class="hosetitem-title"]
一把成!
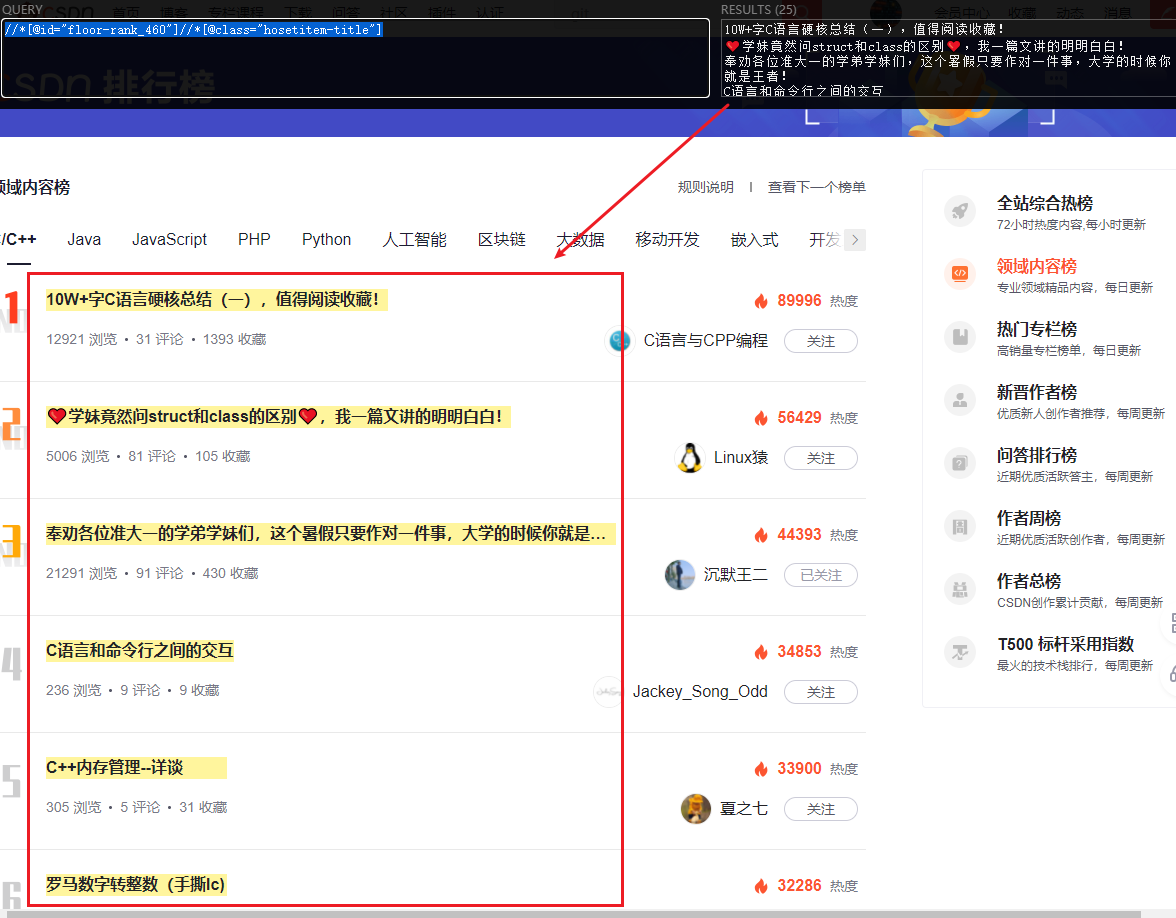
像这样,我们就可以完整的获取到本页面所有的博文标题了。其他字段的
xpath
也可以照这个写出来,阿晨将结果列一下,大家可以使用
XPath Helper
自行尝试下哦!
内容分类=//*[@class="host-move"]/ul/li[@class="active"]/text()
博文名称=//*[@id="floor-rank_460"]//*[@class="hosetitem-title"]/a/text()
博文链接=//*[@id="floor-rank_460"]//*[@class="hosetitem-title"]/a/@href
浏览数=//*[@id="floor-rank_460"]//*[@class="hosetitem-dec"]/span[1]/text()
评论数=//*[@id="floor-rank_460"]//*[@class="hosetitem-dec"]/span[2]/text()
收藏数=//*[@id="floor-rank_460"]//*[@class="hosetitem-dec"]/span[3]/text()
热度=//*[@id="floor-rank_460"]//*[@class="hostitem-item-right"]//span[@class="num"]/text()
博客名称=//*[@id="floor-rank_460"]//*[@class="hostitem-item-right"]/div[@class="right"]/a/text()
博客链接=//*[@id="floor-rank_460"]//*[@class="hostitem-item-right"]/div[@class="right"]/a/@href
接口分析法
阿晨其实一开始就注意到,
csdn
的技术是比较先进的前后端分离技术,而且接口也是设计的非常好的!而且,接口分析不仅简单快速,而且不费脑子!
1、开着控制台访问网页
按
F12
打开控制台,切换到
Network
标签页,然后刷新页面
2、分析接口
上一步中,我们注意到,刷新网页的时候,页面访问了多个接口,其中
https://blog.csdn.net/phoenix/web/blog/hotRank?page=0&pageSize=25&child_channel=c%2Fc%2B%2B
这个接口,就是我们想要的数据。
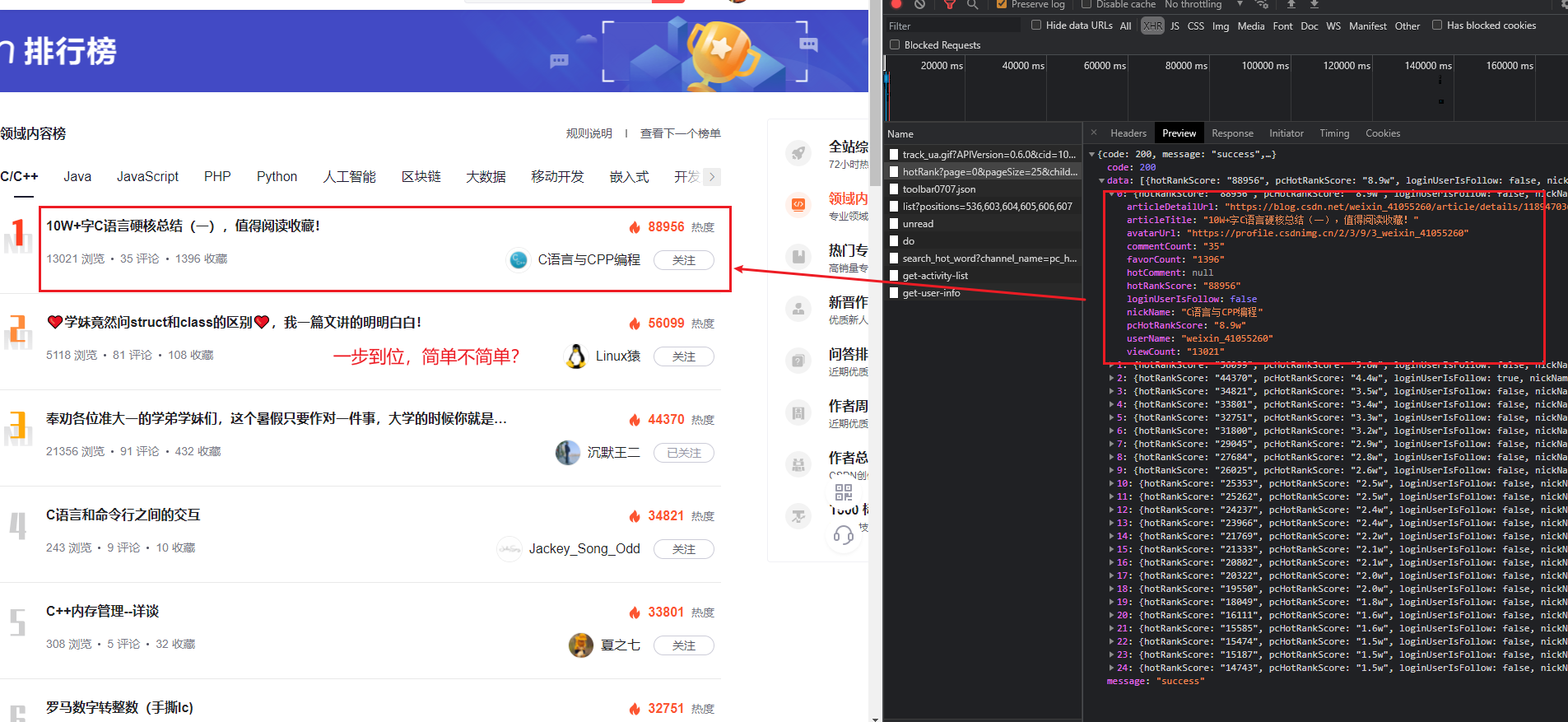
3、使用
Postman
进一步分析接口
Postman
这一步是为了确认接口是否有加密措施,或者参数是否可以调整,以简化爬虫开发。
调试步骤很简单,不停地修改接口参数就行,看看响应是否正常
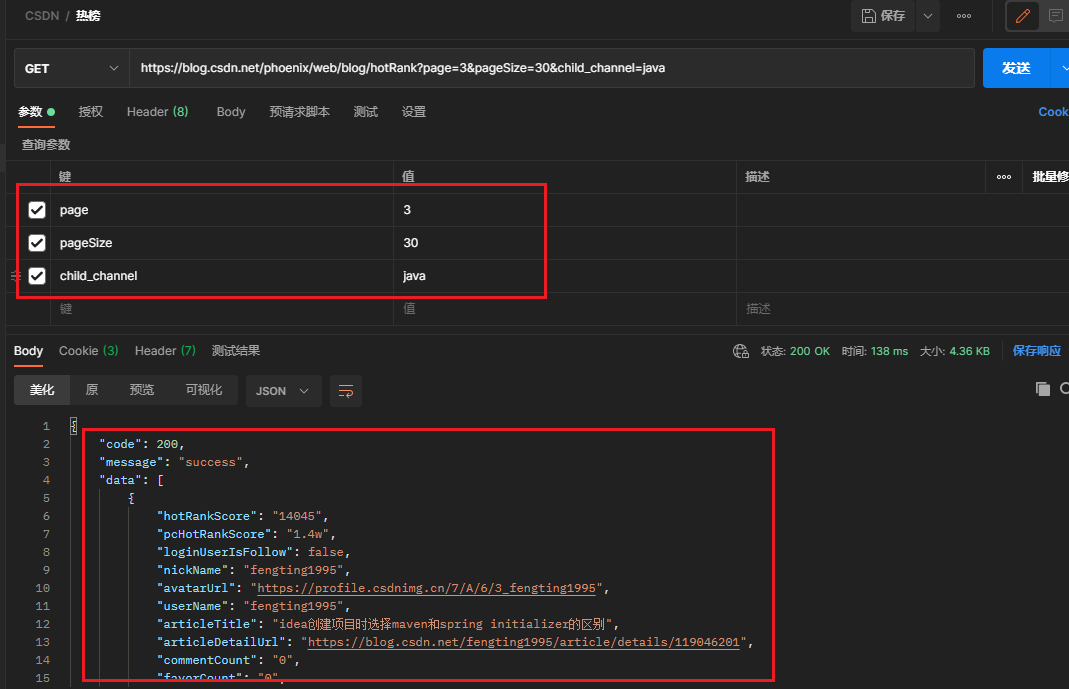
4、编写接口文档
阿晨将热榜的接口文档分享一下。
请求方式=GET
请求路径=https://blog.csdn.net/phoenix/web/blog/hotRank
# 请求参数
page=当前页,从0开始,0为第一页,1为第二页
pageSize=每页显示数量,这个参数可以极大的简化我们的爬虫开发(比如改成1000,一下就把数据全拿到了),但是谨慎修改,可能会被目标网站识别为爬虫。
child_channel=内容分类
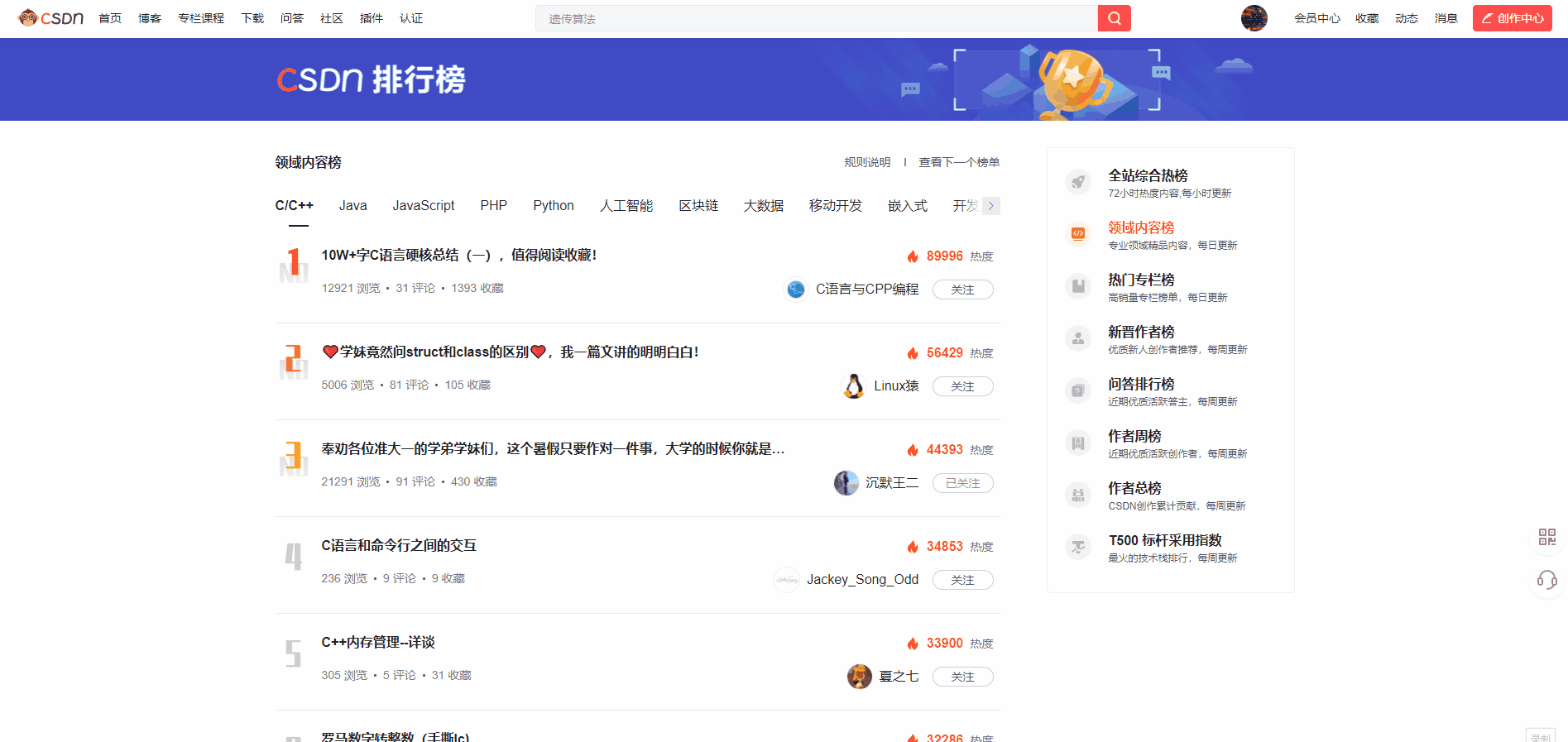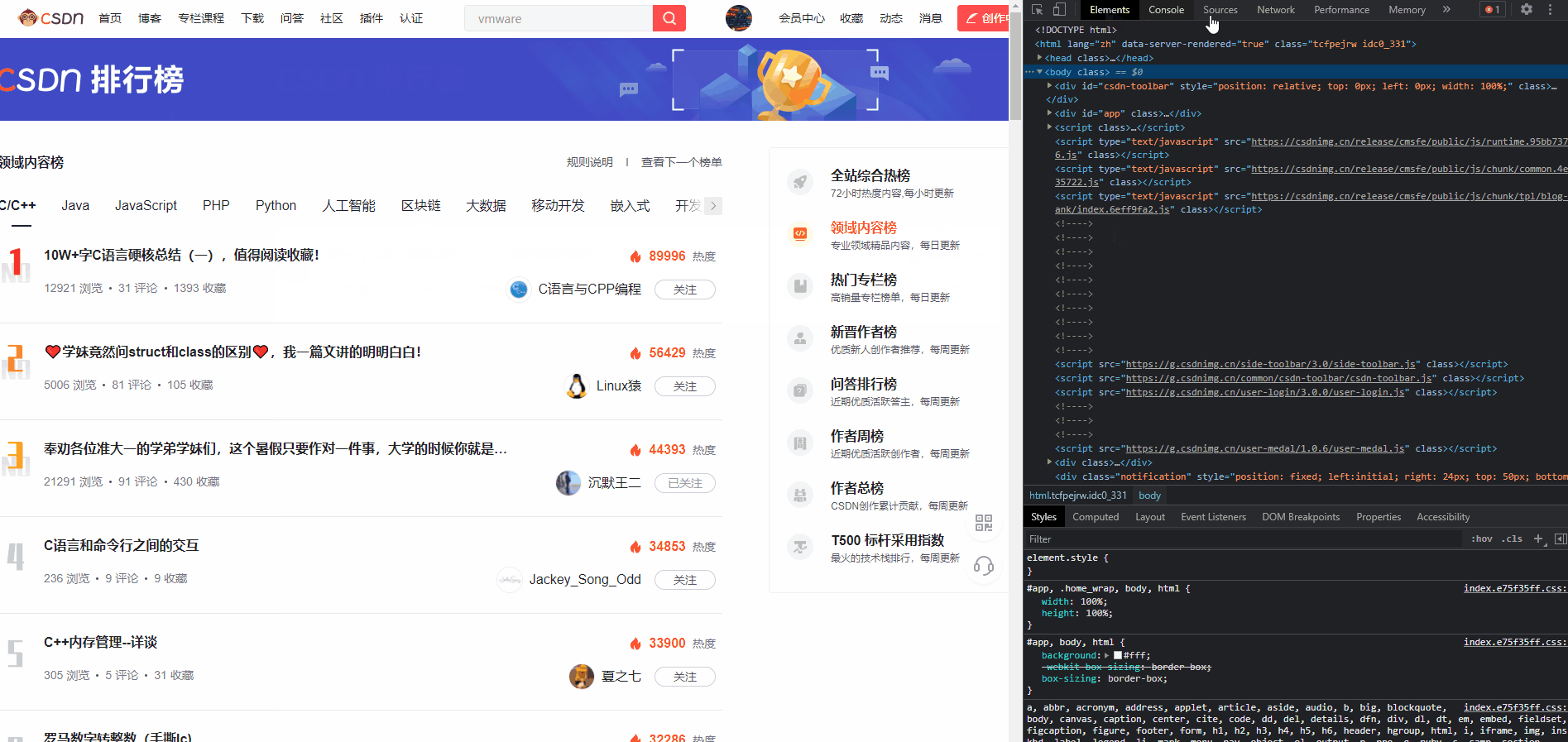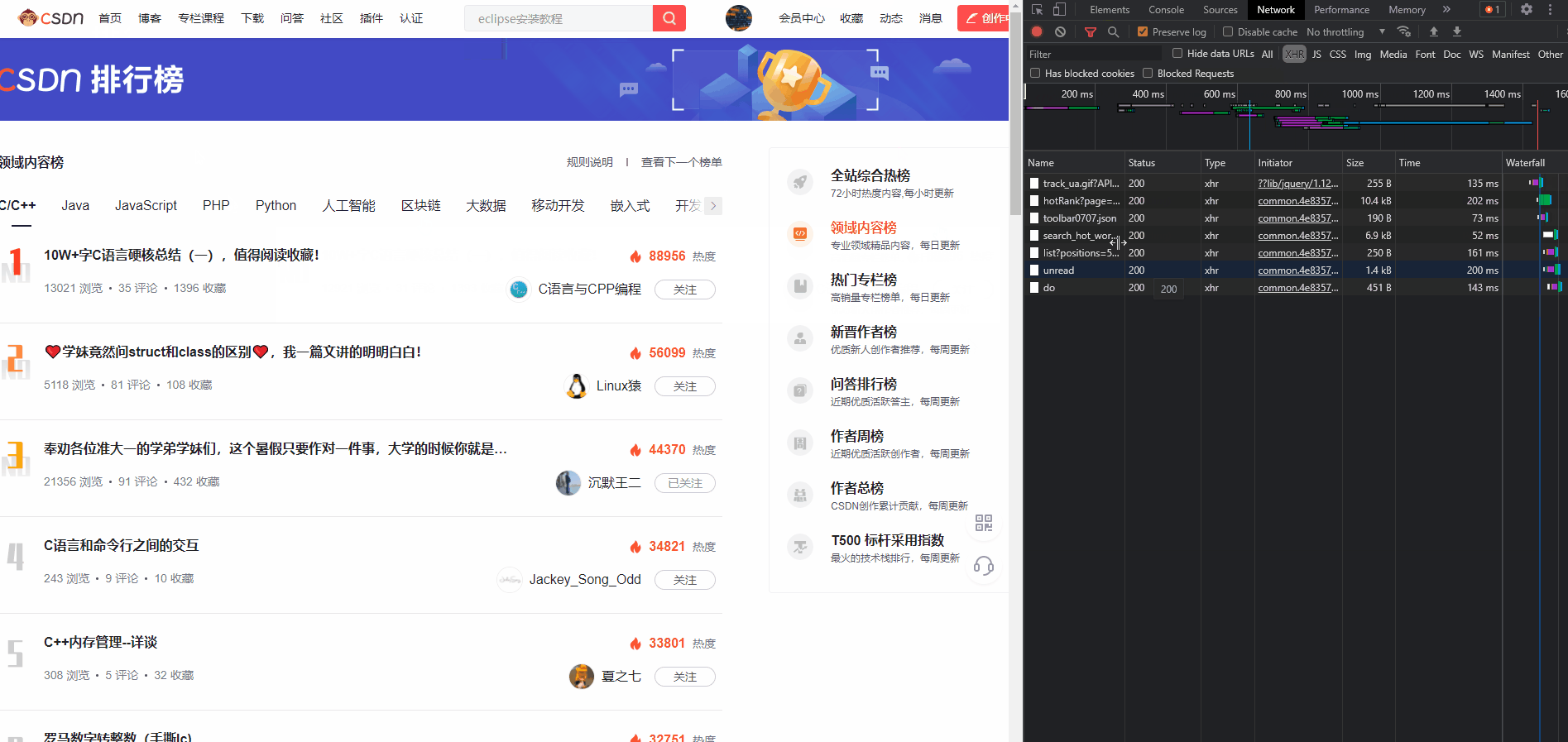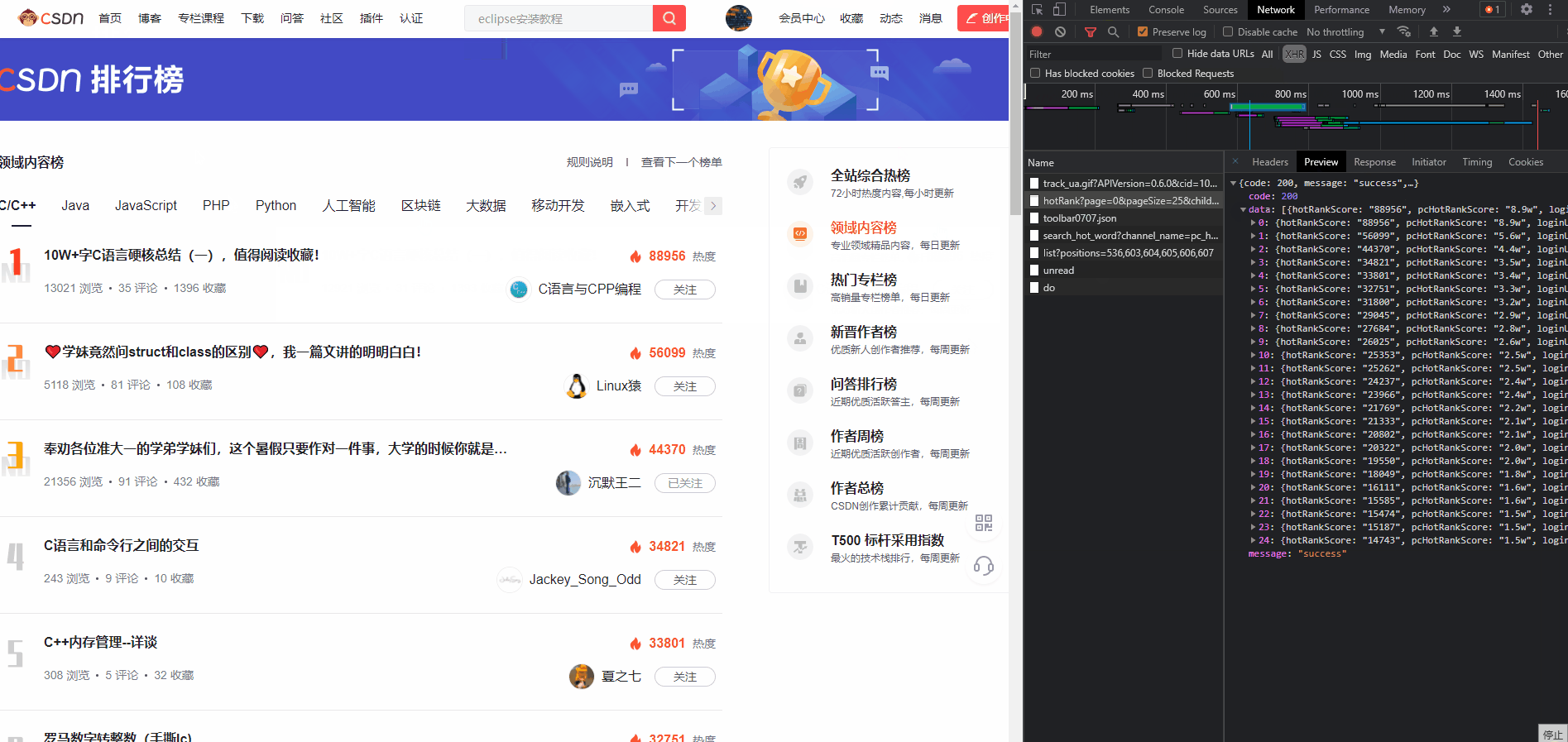
接口响应
{
"code": 200,
"message": "success",
"data": [
{
"hotRankScore": "88956", // 热度
"pcHotRankScore": "8.9w", // 热度文案
"loginUserIsFollow": false, // 登录用户是否已关注此博客
"nickName": "C语言与CPP编程", // 博客名称
"avatarUrl": "https://profile.csdnimg.cn/2/3/9/3_weixin_41055260", // 头像
"userName": "weixin_41055260", // 博客id
"articleTitle": "10W+字C语言硬核总结(一),值得阅读收藏!", // 博文名称
"articleDetailUrl": "https://blog.csdn.net/weixin_41055260/article/details/118947036", // 博文链接
"commentCount": "35", // 评论数
"favorCount": "1399", // 收藏数
"viewCount": "13057", // 浏览数
"hotComment": null // 未知,可能是热门评论?
}
]
}
编码
我们使用上文中接口分析法的结果,来编写我们的爬虫。
1、使用
PyCharm
新建项目
PyCharm
2、安装
Scrapy
Scrapy
在项目根目录打开控制台,输入
$ pip install Scrapy
$ scrapy version
Scrapy 2.5.0
3、新建
Scrapy
爬虫项目
Scrapy
在项目根目录打开控制台,输入
$ scrapy startproject csdnHot
New Scrapy project 'csdnHot', using template directory 'd:\devtools\python\python39\lib\site-packages\scrapy\templates\project', created in:
D:\WorkSpace\Personal\my-scrapy\csdnHot
You can start your first spider with:
cd csdnHot
scrapy genspider example example.com
此刻,我的项目目录是
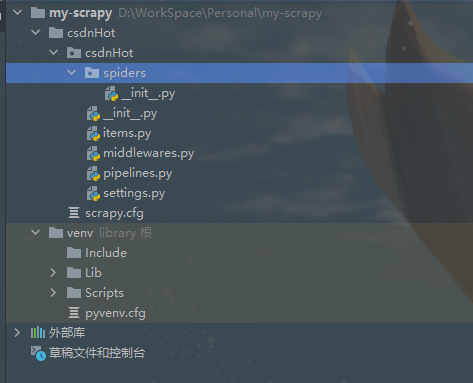
4、新建爬虫
Spider
Spider
在项目根目录打开控制台,输入
$ cd csdnHot/csdnHot/spiders
$ scrapy genspider hotList blog.csdn.net
1、编写爬虫数据类
# items.py
from scrapy import Field, Item
class HotList(Item):
hotRankScore = Field()
nickName = Field()
avatarUrl = Field()
userName = Field()
articleTitle = Field()
articleDetailUrl = Field()
commentCount = Field()
favorCount = Field()
viewCount = Field()
2、编写爬虫
# hotList.py
import json
import scrapy
from csdnHot.items import HotList
class HotlistSpider(scrapy.Spider):
name = 'hotList'
allowed_domains = ['blog.csdn.net']
current_page = 0
start_urls = [
f'https://blog.csdn.net/phoenix/web/blog/hotRank?page={current_page}&pageSize=25&child_channel=c%2Fc%2B%2B'
]
def parse(self, response):
items = json.loads(response.body)["data"]
if len(items) > 0:
for item in items:
hot_list = HotList()
hot_list["hotRankScore"] = item["hotRankScore"]
hot_list["nickName"] = item["nickName"]
hot_list["avatarUrl"] = item["avatarUrl"]
hot_list["userName"] = item["userName"]
hot_list["articleTitle"] = item["articleTitle"]
hot_list["articleDetailUrl"] = item["articleDetailUrl"]
hot_list["commentCount"] = item["commentCount"]
hot_list["favorCount"] = item["favorCount"]
hot_list["viewCount"] = item["viewCount"]
yield hot_list
# 如果还能获取到data,默认还有下一页
self.current_page = self.current_page + 1
next_page = f'https://blog.csdn.net/phoenix/web/blog/hotRank?page={self.current_page}&pageSize=25&child_channel=c%2Fc%2B%2B'
yield scrapy.Request(next_page, callback=self.parse)
3、运行爬虫并保存结果到文件
在项目根目录打开控制台,输入
$ cd csdnHot/csdnHot/spiders
$ scrapy runspider hotList.py -o csdn_hotList.csv
...
'scheduler/enqueued': 5,
'scheduler/enqueued/memory': 5,
'start_time': datetime.datetime(2021, 7, 24, 13, 17, 51, 934035)}
2021-07-24 21:17:53 [scrapy.core.engine] INFO: Spider closed (finished)
看到这个,证明我们的爬虫运行成功了,看下成果!好的,
C/C++
热榜共有101篇博文入选!恭喜各位大佬!!!
如果本篇博客对您有一定的帮助,大家记得留言+点赞+收藏哦。
我是阿晨,在技术的道路上我们一起砥砺前行!