目录
最近在做文本生成相关的任务,调研的时候刷到一篇文本生成的论文:
《A Contrastive Framework for Neural Text Generation》
它认为GPT2生成模型再生成的token具有各异向性,使得token之间的相似性非常接近没有很好的区分度,最后解码的时候造成了文本重复——text degeneration;因此论文提出了一种新的训练策略(SimCTG)+解码算法(contrastive search),在多语言任务和实际的工业场景中进行人工评测,很显著的提升了文本生成的质量。关于该论文提出的text degeneration的原因知乎上有很多大佬和论文作者进行讨论和剖析,最后得出的结论是text degeneration的原因并不是SIMCTG提出的Contrastive Training,它并不能保证表征各向同质性,之所以在文本生成的质量上(少无意义的重复)有实实在在的提升,完全来自于新提出的解码策略——contrastive search decoding。既然这么有效的解码策略,是应该好好学习一下。
一、contrastive search decoding
这是一种非topK、topP以及BeamSearch的解码策略,感觉非常有意思。其核心思想就是对比——把当前要生成的token和已经生成的所有token做相似度计算,得到最大的相似度值;然后使得该token的概率与最大的相似度值的差值最大化的那个token就是我们要生成的token;具体的公式如下:
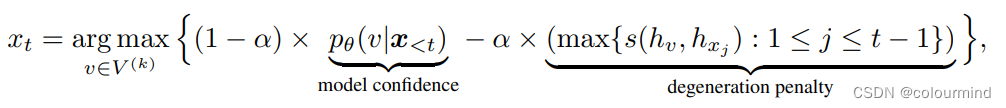
V(k)是指token在模型输出的分布中top_k个最可能的结果,论文中提出K值通常设置3~10。看完公式觉得思想很简单,一下子就理解了公式要表达的思想,但是这里还是有几个值得注意的地方:
1、如何高效的得到当前token的embedding,也就是hv;以及如何得到h1,…..ht-1(已经生成的token的embedding)
2、如何高效的计算当前token的embedding和之前所有文本的embedding的相似度的最大值
3、如何计算整体上的最大值得到V(k)最佳的v
在问题1已经解决的情况下,2和3问题比较好解决,直接采用矩阵计算使用GPU并行计算,就可以很好的解决计算的效率问题;第一个问题理解起来有点点难,对于不太熟悉GPT2模型的人来说,确实不太好理解。本人再阅读起实现源码后,和作者沟通后,再加上对GPT2生成流程的理解后,才完全理解到底应该怎么求hv的。
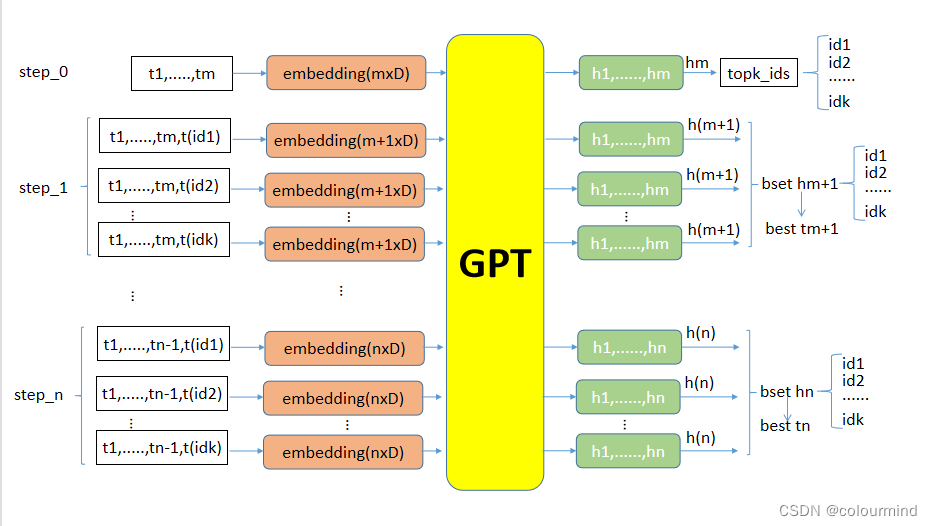
contrastive search decoding大体上的解码流程如上图所示,当前轮次文本输入gpt2模型,使用hm得到新的k个候选生成tokens;然后把这些tokens和之前的文本拼接起来输入到下一轮模型,得到hm+1。这里的hm+1就是前面说的上一轮应该生成的token的embedding,通过解码公式的计算,选出最佳的hm+1也就得到了tm+1——当前轮最佳的那个token。按照上述流程循坏下去就可以得到生成一个句子了。
二、代码实现理解和实验
1、代码走读
上面的核心思想简单的分析了,下面看看如何具体的使用代码实现,先上整体的实现代码,然后再慢慢解析:
def contrastive_search_decode(curr_input_tensor,attention_mask,tokenizer):
"""
对比搜索解码策略
"""
alpha = 0.5
beam_width = 5
generated = [item for item in curr_input_tensor.tolist()]
past_key_values = None
max_length = 64 + curr_input_tensor.shape[1]
stop = False
with torch.no_grad():
for index in range(max_length):
if index == 0:
inputs = prepare_inputs_for_generation(curr_input_tensor, attention_mask, past=past_key_values)
output = model(**inputs,return_dict = True,use_cache=True,output_hidden_states=True)
past_key_values = output.past_key_values
last_hidden_states = output.hidden_states[-1] # [B, S, E]
logit_for_next_step = output.logits[:, -1, :] # [B, V]
bsz, seqlen, embed_dim = last_hidden_states.size()
next_probs = F.softmax(logit_for_next_step, dim=-1)
_, top_k_ids = torch.topk(logit_for_next_step, dim=-1, k=beam_width) # [B, K]
top_k_probs = torch.gather(next_probs, dim=1, index=top_k_ids) # [B, K]
# compute new hidden
past_key_values = enlarge_past_key_values(past_key_values, beam_width)
output = model(
input_ids=top_k_ids.view(-1, 1),
attention_mask=torch.ones_like(top_k_ids.view(-1, 1)),
past_key_values=past_key_values,
output_hidden_states=True,
use_cache=True,
)
# past_key_values是一个二维list;里层list元素是tensor
past_key_values = output.past_key_values
logits = output.logits[:, -1, :] # [B*K, V]
next_hidden = output.hidden_states[-1] # [B*K, 1, E]
context_hidden = last_hidden_states.unsqueeze(1).expand(-1, beam_width, -1, -1).reshape(bsz * beam_width,seqlen,embed_dim) # [B*K, S, E]
selected_idx = ranking_fast(
context_hidden,
next_hidden,
top_k_probs, # [B, K]
alpha,
beam_width,
) # [B]
# prepare for the next step
next_id = top_k_ids[range(len(top_k_ids)), selected_idx].unsqueeze(-1) # [B, 1]
temp = torch.split(next_hidden.squeeze(dim=1), beam_width)
next_hidden = torch.stack(temp) # [B, K, E]
next_hidden = next_hidden[range(bsz), selected_idx, :] # [B, E]
last_hidden_states = torch.cat([last_hidden_states, next_hidden.unsqueeze(1)], dim=1) # [B, S+1, E]
past_key_values = select_past_key_values(past_key_values, beam_width, selected_idx)
temp = torch.split(logits, beam_width)
logit_for_next_step = torch.stack(temp)[range(bsz), selected_idx, :] # [B, V]
tokens = next_id.squeeze(dim=-1).tolist()
for idx, t in enumerate(tokens):
generated[idx].append(t)
for token in tokens:
if token == 102:
stop = True
break
if stop:
break
res = tokenizer.batch_decode(generated, skip_special_tokens=True)说说几个细节
a、past_key_values扩充和压缩
由于每次需要传入past_key_values加快模型的推理速度,并且要在top_k中得到最佳的那个token,因此需要把K个token都要纳入计算中,为了能够矩阵计算需要把每次输入都扩充K倍:
past_key_values扩充
def enlarge_past_key_values(past_key_values, beam_width):
# from [B, num_head, seq_len, esz] to [B*K, num_head, seq_len, esz]
new_key_values = []
for layer in past_key_values:
items = []
for item in layer:
# item is the key and value matrix
bsz, num_head, seq_len, esz = item.size()
item = item.unsqueeze(1).expand(-1, beam_width, -1, -1, -1).reshape(bsz*beam_width, num_head, seq_len, esz) # [bsz*beam, num_head, seq_len, esz]
items.append(item)
new_key_values.append(items)
return new_key_valuespast_key_values中每个tensor的维度变化[B, num_head, seq_len, esz] to [B*K, num_head, seq_len, esz]
past_key_values压缩
def select_past_key_values(past_key_values, beam_width, selected_idx):
'''select_idx: [B]'''
new_key_values = []
for layer in past_key_values:
items = []
for item in layer:
bsz_and_beam, num_head, seq_len, esz = item.size()
bsz = int(bsz_and_beam//beam_width)
temp = torch.split(item, beam_width, dim=0)
item = torch.stack(temp) # [B, K, num_head, seq_len, esz]
item = item[range(bsz), selected_idx, :, :, :] # [B, num_head, seq_len, esz]
items.append(item)
new_key_values.append(items)
return new_key_valuespast_key_values中每个tensor的维度从[B*K, num_head, seq_len, esz]变回到[B, num_head, seq_len, esz]
b、当前token和之前所有token的相似度并行计算
def ranking_fast(context_hidden, next_hidden, next_top_k_probs, alpha, beam_width):
'''
context_hidden: bsz*beam x seqlen x embed_dim
next_hidden: bsz*beam x 1 x embed_dim
next_top_k_probs: bsz x beam
'''
_, context_len, embed_dim = context_hidden.size()
norm_context_hidden = context_hidden / context_hidden.norm(dim=2, keepdim=True)
norm_next_hidden = next_hidden / next_hidden.norm(dim=2, keepdim=True)
cosine_matrix = torch.matmul(norm_context_hidden, norm_next_hidden.transpose(1,2)).squeeze(-1) # [B*K, S]
scores, _ = torch.max(cosine_matrix, dim=-1) # [B*K]
next_top_k_probs = next_top_k_probs.view(-1) # [B*K]
scores = (1.0 - alpha) * next_top_k_probs - alpha * scores
temp = torch.split(scores, beam_width)
scores = torch.stack(temp) # [B, K]
selected_idx = scores.max(dim=-1)[1] # [B]
return selected_idx需要注意到这里的torch.matmul()的计算
context_hidden:[B*K,S,D]
next_hidden:[B*K,1,D]
需要计算batch中每一条数据(每个token的embedding)和之前所有token的embedding的cos相似度
torch.matmul([B*K,S,D],B*K,1,D].T(2,1))=torch.matmul([B*K,S,D],B*K,D,1])=[B*K,S,1]
然后再求最大的那个score的index即可
2、生成效果展示

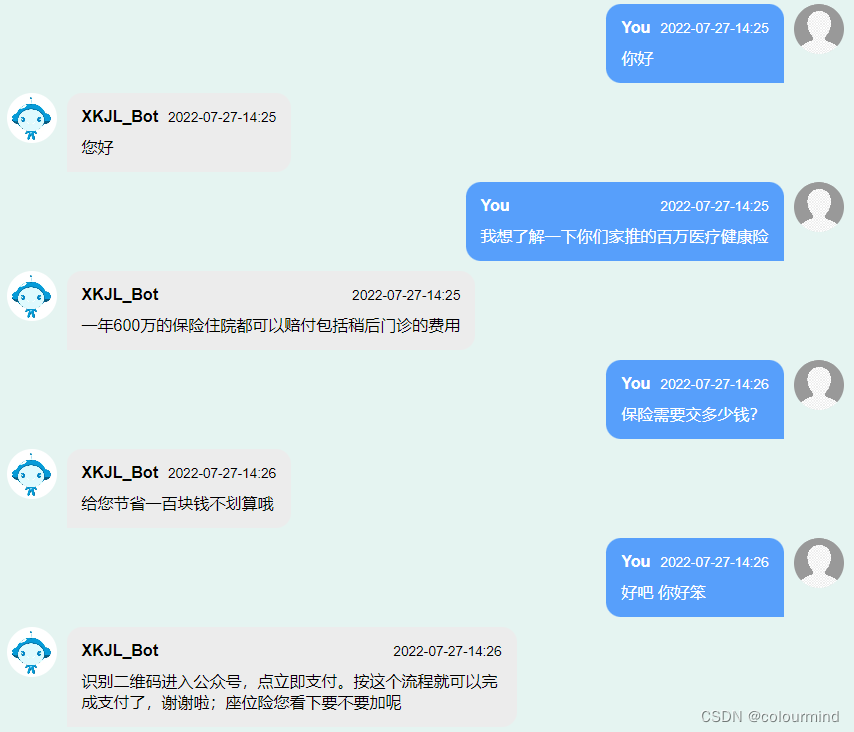
生成的语句还是比较流畅的,重复性得到改善,逻辑性这个是模型本身的问题;但是具体比之前采用beamsearch + sample效果具体能好多少,这边我没有做太多的验证,需要上线使用机器人聊一段时间才知道,不过beamsearch + sample在实际使用的时候就算加上了重复惩罚系数,生成的时候也会有部分重复的,生成例子:
现在财务下班了,财务下班了,明天下午到账
不是,我们不是一个公司的,不是一个公司的
好的,那我给您改一下。那我这边给您改一下
[让我看看][让我看看][让我看看][让我看看]
代理点:506经办200019经办200019经办200019经办
2000块钱,2000块钱,2000块,2000块钱,20002000块钱,2000200020
真实的contrastive search decoding效果,还有待观察,不过目前简单的测试几条来看生成还可以。
3、方案的缺陷
一般而言,我们都要求生成的句子具有多样性——有不同的生成,contrastive search decoding是一个确定性方案,每次只能生成固定的结果。这里作者有提出一个比较合适的方法:
就是先使用beamsearch + sample等方法生成部分句子,然后再使用contrastive search decoding对生成的句子进行补齐。
具体的实现不是特别困难,这里就不实现了。
还有一种方法,实现上比较麻烦,我也提一下思想:就是那个公式中选择v的时候,不选最大的那一个,多选择几个,但是要小于K值。
公式中的argmax 换成 top_n,n取2、3、4这种比K/2小的值感觉比较合适。
参考文章: