
作者 |泳鱼
来源 |算法进阶
一、深度森林的介绍
目前深度神经网络(DNN)做得好的几乎都是涉及图像视频(CV)、自然语言处理(NLP)等的任务,都是典型的数值建模任务(在表格数据tabular data的表现也是稍弱的),而在其他涉及符号建模、离散建 模、混合建模的任务上,深度神经网络的性能并没有那么好。
深度森林(gcForest)
是深度神经网络(DNN)之外的探索的一种深度模型,原文:
it may open a door towards alternative to deep neural networks for many tasks
。不同于深度神经网络由可微的神经元组成,深度森林的基础构件是不可微的
决策树
,其训练过程不基于 BP 算 法,甚至不依赖于梯度计算。它初步验证了关于深度学习奏效原因的猜想–即只要能做到
逐层加工处理、内置特征变换、模型复杂度够
,就能构建出有效的深度学习模型,并非必须使用神经网络。
深度森林主要的特点是:
-
拥有比其他基于决策树的集成学习方法更好的性能
-
拥有更少的超参数,并且无需大量的调参
-
训练效率高,并且能够处理大规模的数据集
深度森林目前还处于探索阶段,评估模型(gcForest)的表现,在MNIST数据集准确率不错:
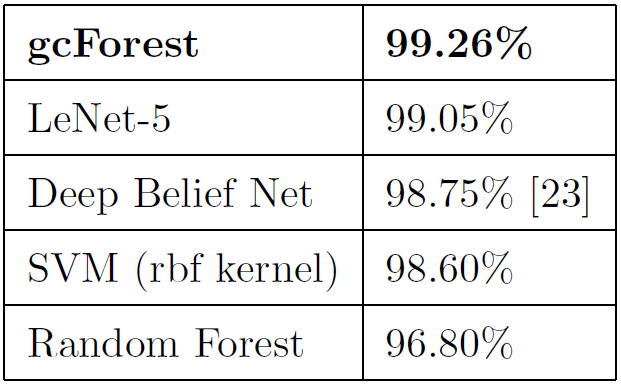
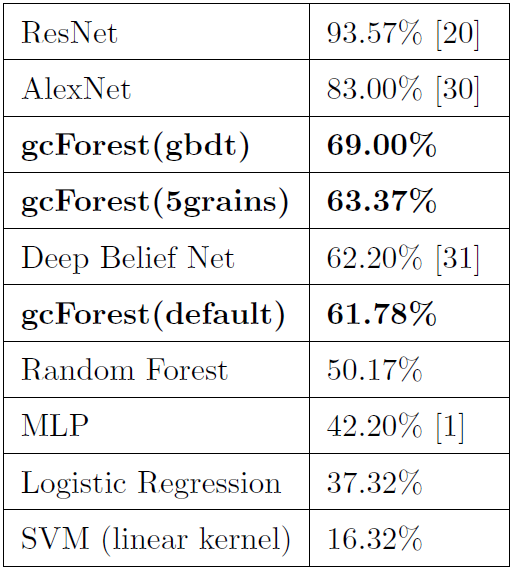
在CIFAR-10数据集上准确率欠佳(高维图像还是DNN的天下):
二、深度森林原理
深度森林其实也就是
ensemble of ensemble
的模型,可以看作是在集成树(森林)模型的基础上,进一步stacking集成学习及优化(Complete Random Forest、shortcut-connection、Multi-Grained Scanning等),以解决深层容易过拟合的问题。
2.1 特征的处理
深度森林借鉴了CNN滑动卷积核的特征提取,通过多粒度扫描(Multi-Grained Scanning)方法,滑动窗口扫描原始特征,生成输入特征。
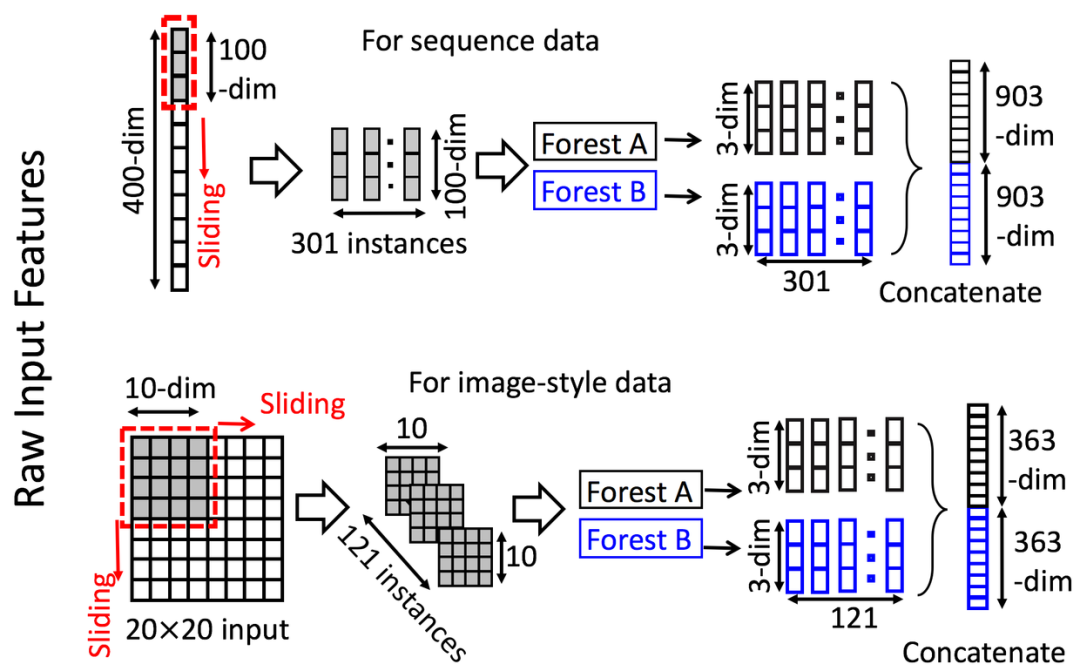
如上图,假设我们现在有一个400维(序列数据)的样本输入,现在设定采样窗口是100维的,那我们可以通过逐步的采样,最终获得301个子样本(默认采样步长是1,得到的子样本个数 = (400-100)/1 + 1)。
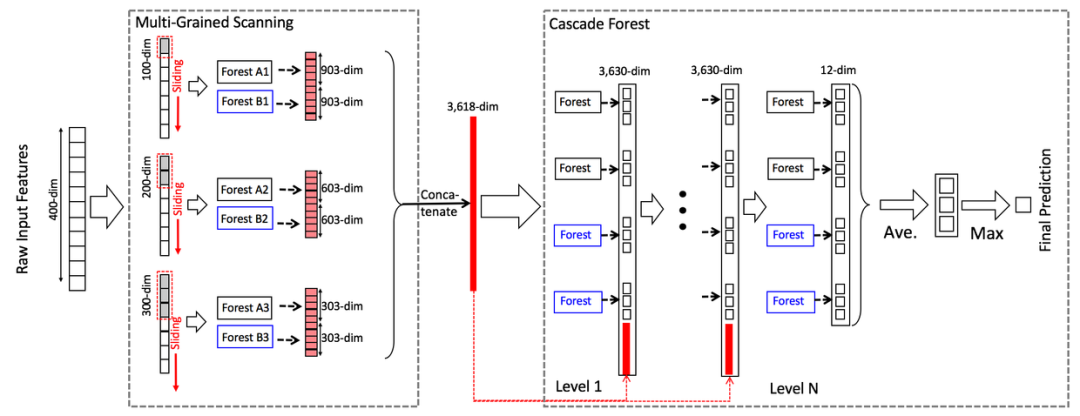
整个特征处理的过程就是:先输入一个完整的P维样本,然后通过一个长度为k的采样窗口进行滑动采样,得到S = (P – K)/1+1 个k维特征子样本向量,接着每个子样本都用于完全随机森林和普通随机森林的训练并在每个森林都获得一个长度为C(类别数)的概率向量,这样每个森林会产生长度为S*C的表征向量(即经过随机森林转换并拼接的概率向量),最后把每层的F个森林的结果拼接在一起得到本层输出。
2.2 深度森林的架构
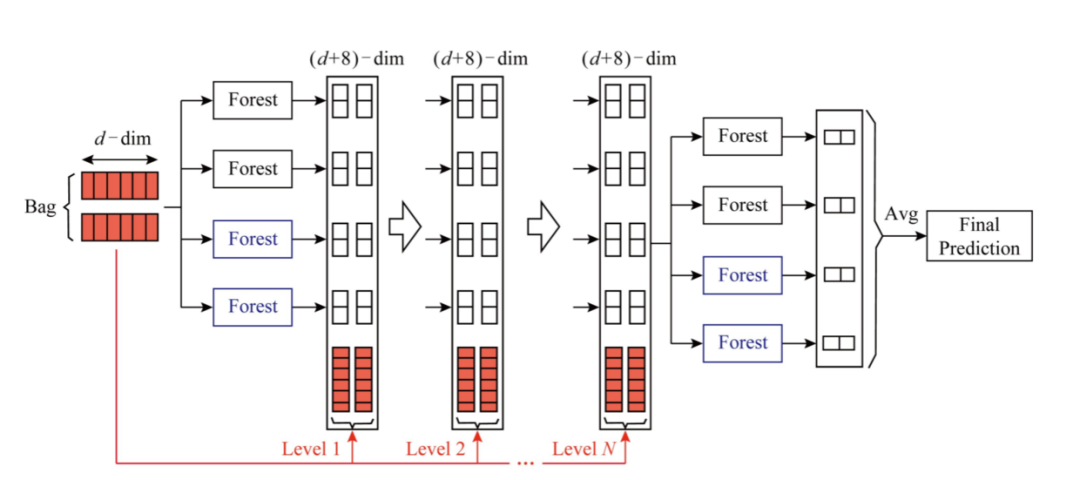
整个模型的架构采用一个级联结构(如上图), 每一级都采用两种森林构建:random forests (black) and completely-random tree forests(blue),使用completely-random可以增加基模型的多样性,以减少过拟合风险,提高集成学习的效果。
完全随机森林(completely-random tree forests):由多棵树组成,每棵树包含所有的特征,并且随机选择一个特征作为分裂树的分裂节点。一直分裂到每个叶子节点只包含一个类别或者不多于是个样本结束。
随机森林(random forests):同样由多棵树构成,每棵树通过随机选取Sqrt(特征总数)个特征 ,然后通过GINI分数来筛选分裂节点。
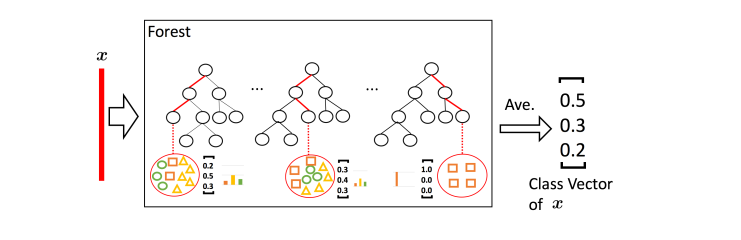
每一层的级联接收前一层处理的特征信息,并将处理结果(类向量)输出到下一层(如上图)。以三分类为例,输入特征为向量x,经过每个森林学习后(注:每个森林的学习的数据利用k折交叉验证得到,以减少过拟合风险),得到预测类分布,然后求平均,再与之前原始特征拼接(类似shortcut-connection),作为下一层的输入。
扩展完一层后,整个级联结构可在验证集上面测试性能,若没有显著提高,训练过程会终止,故而层数可以自动确定。这也是gcForest能够自动决定模型复杂度的原因。
三、深度森林预测
本节简单使用深度森林模型用于波士顿房价回归预测及癌细胞分类任务。
安装:pip install deep-forest
-
波士顿房价回归预测,使用默认参数效果还不错:Testing MSE: 8.068
# 回归预测--波士顿房价
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from deepforest import CascadeForestRegressor
X, y = load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
model = CascadeForestRegressor(random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("\nTesting MSE: {:.3f}".format(mse))-
癌细胞分类任务,准确率不错,Testing Accuracy: 95.105 %
# 分类预测--癌细胞分类数据集
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from deepforest import CascadeForestClassifier
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
model = CascadeForestClassifier(random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred) * 100
print("\nTesting Accuracy: {:.3f} %".format(acc))


往
期
回
顾
资讯
技术
技术
资讯

分享

点收藏

点点赞

点在看