算法开发流程介绍,以
客户流失预测项目
为案例
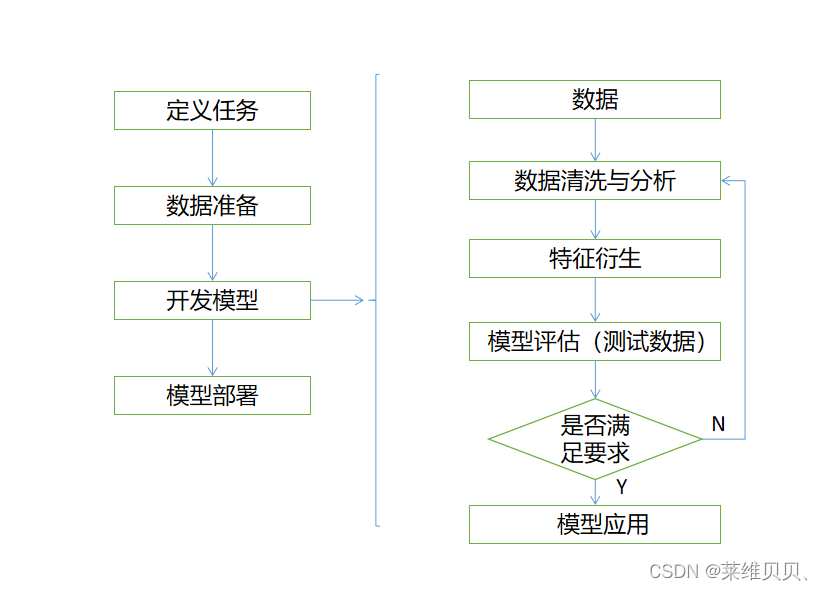
一、定义任务
-
项目的背景
是什么?
答:
银行每年都要面对严重的客户流失问题,构建客户预警模型,输出客户流失概率,分析出一个客户是否可能是潜在的易流失客户对银行具有极大的价值。 -
项目的目标
是什么?
答:
根据用户基本信息与历史账单信息,
构建有效的客户流失预警模型,并分析客户流失前的主要特征
。 -
项目的评估指标
是什么?
答:
评估指标是
AUC
(这个指标需要甲方的需求而定) -
项目的数据与项目的目标是否存在关系?
答:
训练数据与目标存在关系
(如果不存在关系,你模型再好,也没用)。 -
评估指标和业务目标是否一致?
答:
AUC越高,客户流失预警模型成功预测目标的概率就越大。 -
达到业务目标的最低性能是什么?
答:
没上限(一般得有合理的最低性能)。 -
目前的解决方案/解决方法是什么?(如果有的话,能否复现?)
答:
根据
客户流失
关键词搜索相关论文与博客,了解解决此类问题的方向。 尽可能复现前人的假设,再创新。
二、数据准备
结合业务特性明确模型所需要的训练数据
。脱离业务的特征数据是没有灵魂的。(拿用户的历史通话信息预测银行的客户是否流失 = 白日做梦( ̄┰ ̄*))
1. 公司本身数据
2. kaggle
3. 购买数据
…
自采数据注意事项
:
- 是否合法合规
- 确保删除或保护敏感性(例如:匿名)
- 操作数据的副本(保持原始数据的完整性)
- 为所有数据编写转换函数,原因是:
1) 方便下次准备数据集;
2)解决方案啊生效后,可以用来清洗和准备新的数据实例;
三、开发模型
3.1 初期的数据清洗与分析
审视数据
(观察数据类型:连续型数据、离散型数据、类别型数据、时间类型数据、缺失值情况)
操作
: data.info(),data.head(),data.describe(),data.isna().sum()
目的
: 整体认识数据的特征情况,方便后期进行数据处理。
处理缺失值和唯一值
操作
: 待补充
目的
:删除无意义的特征,缺失值90%以上、唯一值的特征可以直接删除。
数据类型分类
(连续型数据、离散型数据、类别型数据、时间类型数据)
操作
:待补充
目的
:方便后期对相同类型的数据进行统一处理。
连续型数据处理
操作
:处理异常值、分布异常
目的
:去除不合理的特征。
类别型数据处理
操作
:映射有序特征(A,B,C,D—>1,2,3,4)、Labelencoder处理无序特征、【
类别特征总结链接
】
目的
:将数据处理成模型可用的类型。
时间类型数据处理
操作
:【
时间特征总结链接
】
目的
:提取时间的特征。
3.2 特征工程
连续型数据的特征衍生
操作
:业务理解特征构造、特征进行分箱处理、连续特征之间进行加减乘除
离散型数据的特征衍生
操作
:某个类别特征(类别数据转换成了类别特征,即离散型数据)情况下另一个特征的nunique特征、count特征。
离散型数据
+
连续型数据
操作
:统计特征(mean、min、max、std)
3.3 基准模型
分类模型
:逻辑回归、KNN、SVM、NN、随机森林、XGBoost、
LightGBM
、CatBoost等。
回归模型
:线性回归、NN、随机森林、XGBoost、
LightGBM
、CatBoost等
聚类模型
:K-means、
iForest
、DBSCAN、OPTICS等。
注意
:不是树模型的需要进行
标准化
。
3.4 模型优化
过拟合
:训练集表现
好
,测试集表现
不好
操作
:正则化、剔除训练和测试数据中分布相差大的特征、增加训练数据、交叉验证等
欠拟合
:训练集表现
不好
,测试集表现
不好
操作
:增加训练数据、重新审视数据与目标是否存在联系。
超参数调节
:
操作
: 随机抽取、网格搜索、贝叶斯优化调参等
3.5 模型融合
模型融合的目的
:提高模型的泛化性。
模型融合的假设
:对于独立训练的多个表现良好的模型,
它们表现良好可能是因为不同的原因:
每个模型都从略微不同的角度观察数据来做出预测,得到了部分“真相”,但不是全部。
模型融合的口号
:集成的模型应该
尽可能好
,同时尽
可能不同
四、模型部署 (后期填补)
4.1 向利益相关者解释你的工作并设定预期
4.2 部署推断模型
4.3 监控模型在真实环境中的性能
4.4 维护模型
4.5 更新模型
参考
- https://blog.csdn.net/is_badboy/article/details/104520461
- https://blog.csdn.net/ChenVast/article/details/82107490
- https://blog.csdn.net/ChenVast/article/details/82107490
- https://blog.csdn.net/qq_39521554/article/details/78877505
- https://zhuanlan.zhihu.com/p/149360150
- https://zhuanlan.zhihu.com/p/92611443
- https://zhuanlan.zhihu.com/p/24988645
- 《Python深度学习(第二版)》,[美] 弗朗索瓦·肖莱