第八章 图像压缩
引言
图像压缩是一种减少描绘一幅图像所需数据量的技术和科学,它是数字图像处理领域中最有用和商业上最成功的技术之一。
8.1 基础知识
术语数据压缩是指减少表示给定信息量所需数据量的处理。在该定义中,数据和信息是不相同的事情;数据是信息传递的手段。因为相同数量的信息可以用不同数量的数据表示,包含不相关或重复信息的表示称之为冗余数据。如果我们令b和b’代表相同信息的两种表示中的比特数(或信息携带单元),那么用b比特表示的相对数据冗余R是
R
=
1
−
1
C
R=1-\frac{1}{C}
R
=
1
−
C
1
其中,C通常称为压缩率,定义为
C
=
b
b
′
C=\frac{b}{b’}
C
=
b
′
b
在数字图像压缩的内容中,上式中的b通常是以二维灰度值阵列表示一幅图像所需的比特数。二位灰度阵列是人们观察和解释图像的首选格式,并且以它作为判定所有其他表示的标准。然而,当它变成紧凑的图像表示时,这些格式就远不是最佳格式了。二位灰度阵列受如下可被识别和利用的三种主要类型的数据冗余的影响:
-
编码冗余
。编码是用于表示信息实体或事件集合的符号系统(字母、数字、比特和类似的符号等)。每个信息或事件被赋予一个编码符号的序列,称之为码字。每个码字中的符号数量就是该码字的长度。在多数二维灰度阵列中,用于表示灰度的8比特编码所包含的比特数要比表示该灰度所需要的比特数多。 -
空间和时间冗余
。因为多数二维灰度阵列的像素是空间相关的(即每一个像 素类似于或取决于相邻像素),在相关像素的表示中,信息被没有必要地重复了。在视频序列中,时间相关的像素(即类似于或取决于相邻帧中的那些像素)也是重复的信息。 -
不相关的信息
。多数二维灰度阵列中包含有- -些被人类视觉系统忽略或与用途无关的信息。从没有被利用的意义上看,它是冗余的。
8.1.1 编码冗余
当对事件集合(例如灰度值)分配码的时候,如果不取全部事件概率的优势,就会出现编码冗余。当用自然二进码表示-幅图像的灰度时, 编码冗余几乎总是存在的。其原因是大多数图像都是由规则的、在某种程度上具有可预测形态(形状)与反差的物体组成的,并且这些图像被取样,所以,描述的物体远大于图像元素。对大多数图像来说,自然的结果是某些灰度与其他灰度相比更可能出现(即多数图像的直方图是不均匀的)。自然二进制编码对最大和最小可能值分配相同的比特数,从而产生了编码冗余。
8.1.2 空间冗余和时间冗余
在多数图像中,像素是空间(在x和y方向)和时间相关的(当该图像是视频序列的一部分时)。 因为多数像素灰度可根据相邻像素灰度进行合理的预测,所以单个像素携带的信息较少。在这种意义上,一个像素可由其相邻像素推断出来,那么它的视觉贡献的大多数就是冗余的。为减少空间与时间相关的像素涉及的冗余,二维灰度阵列必须变换为更有效但通常不可见的表示。例如,行程长度或相邻像素之间的差异可供利用。这种类型的变换称为映射。如果原始二二维灰度阵列的像素可以根据变换后的数据集合无误地重建,则称这个映射是可逆映射,否则称这个映射是不可逆映射。
8.1.3 不相关的信息
压缩数据集最简的方法之一是从集合中消除多 余的数据。在数字图像压缩方面,被人的视觉系统忽略的信息或与图像预期的应用无关的信息显然都是删除的候选者。消除冗余是可能的,因为这种信息本身对于正常的视觉处理和/或期望的图像用途并不是本质的。由于去除这种信息会导致定量信息的损失,这种信息的去除通常称为量化。这一术语与该词的标准用法一致, 它通常意味着将较宽范围的输人值映射为有限数量的输出值。因为信息损失了,所以量化是一种不可逆的操作。
8.1.4 图像信息的度量
山农第一定理
山农第一定理也称为无噪声编码定理,它给出了
在无损情况下,数据压缩的临界值。
在无损压缩的情况下,压缩任何东西
所需要的比特数都大于香农第一定理所给出的值
。其数字表述如下:
考虑序列发送系统,其中的序列都是来自于 X的 n个字符。如果序列中的每一个字符都服从 p(x) 分布,也就是说,它们独立同分布。
那么:
H
(
X
)
≤
L
n
<
H
(
X
)
+
1
n
H(X)\le L_n \lt H(X)+ \frac{1}{n}
H
(
X
)
≤
L
n
<
H
(
X
)
+
n
1
其中
L
n
L_n
L
n
为每输入字符期望码字长度,因此,
通过使用足够大的分组长度,可以获得一个编码,可以使其每字符期望码长任意地接近熵
。
那么问题就来了,如果不是独立同分布怎么办,那岂不是凉凉?当然有解决办法,这个东西叫做
熵率
,而下面这个式子也是更具有普适的理论价值。
H
(
X
1
,
X
2
,
.
.
.
,
X
n
)
n
≤
L
n
∗
<
H
(
X
1
,
X
2
,
.
.
.
,
X
n
)
n
+
1
n
\frac{H(X_1,X_2,…,X_n)}{n} \le L_n^* \lt \frac{H(X_1,X_2,…,X_n)}{n} + \frac{1}{n}
n
H
(
X
1
,
X
2
,
…
,
X
n
)
≤
L
n
∗
<
n
H
(
X
1
,
X
2
,
…
,
X
n
)
+
n
1
其中
H
(
X
1
,
X
2
,
.
.
.
,
X
n
)
H(X_1,X_2,…,X_n)
H
(
X
1
,
X
2
,
…
,
X
n
)
是联合熵。对于一个随机过程而言,它给出了最简洁描述该过程所需要的每个字符期望比特数。而随机过程,又恰恰可以建模很多现象和发展规律。也就是说,上式是一个具有普适价值的式子。
8.1.5 保真度准则
去除“与视觉不相关”信息会导致真实的或一定数量的图像信息的丢失。因为信息的丢失,因此需要一种量化这种丢失的本质的方法。两类准则可用于这样的评估: (1) 客观保真度准则; (2) 主观保真度准则。
当信息损失可以表示为压缩处理的输人和输出的数学函数时,则称其是以客观保真度准则为基础的。尽管客观保真度准则提供了一种简单方便的评估信息损失的方法,但解压缩后的图像最终还是由人来观察的。因此,使用人的主观评估来衡量图像的质量通常更为适当。主观评估是通过向观察者显示解压缩的图像,并将他们的评估结果进行平均得到的。
8.1.6 图像压缩模型
图像压缩系统是由两个不同的功能部分组成的: 一个编码器和一个解码器。 编码器执行压缩操作,解码器执行解压缩的互补操作。两种操作可用软件执行,如在Web浏览器和许多商业图像编辑程序中那样,或者使用硬件和固件相结合的形式执行,如商业DVD播放器。codec 是一个具有编码和解码能力的装置或程序,它有编码和解码的能力。
图像f(x,…)[f(x,…)在静止图像中被表示f(x,y),在视频应用中表示f(x,y,t)]被输入到编码器中,这个编码器创建该输入的压缩表示。把这一表示存储起来以备后续应用,或为传输而存储,以便远程应用。当压缩后的表示送人其互补的解码器中时,就会产生重建的输出图像
f
^
(
x
,
.
.
.
)
\widehat{f}(x,…)
f
(
x
,
…
)
。
编码或压缩过程
通过编码去除码字与码字之间的各种冗余从而达到压缩的目的通常需要三个阶段。
第一个阶段, 映射器把f(x,…)变换为设计来降低空间和时间冗余的形式(通常不可见)。
第二阶段量化器根据预设的保真度准则来降低映射器输出的精度。其目的是排除压缩表示的无关信息。这一操作是不可逆的。 当希望进行无误差压缩时,这一步必须略去。在视频应用中,通常需要度量编码输出的比特率(比特/秒),并调整量化器的操作,以保持预设的平均输出比特率。这样,输出的视觉质量就可根据图像内容逐帧变化。
在第三阶段,即信源编码处理的最后阶段,符号编码器生成一个定长编码或变长编码来表示量化器的输出,并根据该编码来变换输出。在大多数情况下,使用变长编码。最短的码字赋予出现频率最高的量化器输出值,以最小化编码冗余。这种操作是可逆的。
解码或解压缩过程
解码器仅包含两个部分: 一个符号解码器和一个反映射器。它们以相反的顺序执行编码器的符号编码器和映射器的反操作。因为量化导致了不可逆的信息损失,所以反量化器模块没有包含在通常的解码器模型中。在视频应用中,解码后的输出帧保留在内部帧存储器中(没有显示),并用于重新插入在编码器中去除的时间冗余。
8.2 一些基本的压缩方法
8.2.1 霍夫曼编码
计算机数据处理中,霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表]是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
8.2.2 Golomb编码
格伦布编码(Golomb code)是一种无损的数据压缩方法,由数学家Solomon W.Golomb在1960年代发明。Golomb编码只能对非负整数进行编码,符号表中的符号出现的概率符合几何分布(Geometric Distribution)时,使用Golomb编码可以取得最优效果,也就是说Golomb编码比较适合小的数字比大的数字出现概率比较高的编码。它使用较短的码长编码较小的数字,较长的码长编码较大的数字。
8.2.3 算术编码
算术编码是图像压缩的主要算法之一。是一种无损数据压缩方法,也是一种熵编码的方法。和其它熵编码方法不同的地方在于,其他的熵编码方法通常是把输入的消息分割为符号,然后对每个符号进行编码,而算术编码是直接把整个输入的消息编码为一个数,一个满足(0.0≤n<1.0)的小数n。
8.2.4 LZW编码
LZW压缩算法的基本原理:提取原始文本文件数据中的不同字符,基于这些字符创建一个编译表,然后用编译表中的字符的索引来替代原始文本文件数据中的相应字符,减少原始数据大小。看起来和调色板图象的实现原理差不多,但是应该注意到的是,我们这里的编译表不是事先创建好的,而是根据原始文件数据动态创建的,解码时还要从已编码的数据中还原出原来的编译表。
8.2.5 行程编码
行程编码也叫作RLE压缩编码,其中RLE是Run-Length-Encoding的缩写,这种压缩方法是最简单的图像压缩方法。行程编码的基本原理是在给定的数据图像中寻找连续的重复数值,然后用两个字符取代这些连续值。例如,一串字母表示的数据为“aaabbbbccccdddeeddaa”,经过行程编码处理可表示为“3a4b4c3d2e2d2a”。
8.2.6 基于符号的编码
基于符号的编码(Symbol-based coding)是一种数据压缩技术,它通过利用符号的统计特性对数据进行编码和压缩。符号可以是单个字符、数字、字节或其他固定长度的数据单元。
基于符号的编码的基本思想是将出现频率高的符号用较短的编码表示,而出现频率低的符号用较长的编码表示,以达到数据压缩的目的。常用的基于符号的编码算法包括霍夫曼编码(Huffman Coding)、算术编码(Arithmetic Coding)等。
霍夫曼编码是一种无损的编码技术,它通过构建霍夫曼树来生成变长编码。在霍夫曼树中,出现频率高的符号位于较靠近根节点的位置,而出现频率低的符号位于较靠近叶子节点的位置。通过将这些符号编码为树中相应路径上的比特序列,可以实现对数据的压缩。
算术编码是一种更高效的基于符号的编码技术,它根据符号出现的概率来动态调整编码范围。它将整个数据序列视为一个连续的数值范围,通过不断缩小范围的方式来进行编码。在解码时,可以根据编码值所对应的范围来确定符号。由于算术编码可以实现更高的编码效率,因此在许多数据压缩领域中得到广泛应用。
基于符号的编码在数据压缩、通信和存储等领域具有重要的应用,它可以有效地减小数据量,提高传输效率,并在保持数据完整性的同时实现数据的压缩。
8.2.7 比特平面编码
比特平面编码又称为位平面编码,位平面编码是一种通过单独地处理图像的位平面来减少像素间冗余的有效技术。它将一幅多级图像分解为一系列二值图像并采用几种熟知的二值图像压缩方法对每一幅二值图像进行压缩。位平面编码分为两个步骤:位平面分解和位平面编码。
8.2.8 块变换编码
块变换编码(Block Transform Coding)是一种常用的数据压缩技术,用于将数字信号或图像信号进行有效地编码和压缩。它的主要思想是将信号分解为多个较小的块,然后对每个块进行变换,使得能量较集中的部分集中在低频系数中,而能量较分散的部分则分布在高频系数中。这样就可以通过量化和编码高频系数的较小变化来实现数据的压缩。
最常用的块变换编码算法之一是离散余弦变换(Discrete Cosine Transform,简称DCT)。DCT将信号分解为一系列的频域系数,其中低频系数表示信号的慢变化部分,高频系数则表示信号中的细节信息。通过对高频系数进行量化和编码,可以实现对信号的压缩。
在图像和视频压缩中,块变换编码通常与其他技术如量化和熵编码结合使用。量化将变换后的系数进行近似表示,以减小系数的位数,从而减少数据量。而熵编码则利用信号统计特性,将出现频率高的系数用较短的码字表示,而出现频率低的系数用较长的码字表示,进一步提高数据的压缩率。
块变换编码在许多应用中都有广泛的应用,比如在图像和视频压缩、无线通信、音频编码等领域。它可以有效地减小数据量,提高存储和传输效率,并在保持较高质量的情况下实现对信号的压缩。
8.2.9 预测编码
预测编码(Predictive coding)是一种数据压缩技术,通过利用数据序列中的相关性和模式来进行编码和压缩。它基于一个基本假设,即当前数据点的值可以通过前面的数据点的值进行预测。预测编码将预测误差(当前数据点的值与预测值之间的差异)进行编码,而不是直接编码原始数据点的值。
预测编码的基本过程包括两个步骤:预测和编码。在预测步骤中,根据前面的数据点建立预测模型,用来预测当前数据点的值。常用的预测模型包括线性预测和非线性预测。在编码步骤中,将实际数据点的值与预测值进行比较,得到预测误差,然后对预测误差进行编码。
常见的预测编码算法包括差分编码(Differential Coding)、差分脉冲编码调制(Differential Pulse Code Modulation,DPCM)、自适应预测编码(Adaptive Predictive Coding)等。这些算法根据不同的预测模型和编码策略,对数据进行不同方式的预测和编码。
预测编码在许多领域中都有广泛的应用,特别是在图像、音频和视频压缩中。由于预测编码可以利用数据的相关性和模式,通过编码预测误差来实现数据的压缩,因此可以有效地减小数据量,提高传输和存储效率,并在一定程度上保持数据的质量。
8.2.10 小波编码
小波编码(Wavelet Coding)是一种基于小波变换的数据压缩技术,用于对信号、图像或视频进行编码和压缩。它利用小波变换的多尺度分析特性,在时域和频域上对信号进行分解和编码。
小波变换将信号分解为不同尺度的频带,其中低频分量表示信号的慢变化部分,高频分量则表示信号中的细节信息。小波编码的基本思想是,对于大部分信号来说,细节信息的能量相对较小,可以进行较强的压缩,而保留较高能量的低频分量,以实现对信号的压缩。
小波编码的具体过程包括以下步骤:
- 将信号进行小波变换,得到不同尺度的频带系数。
- 对高频系数进行量化和编码,通常使用比较高效的编码算法如熵编码、算术编码等。
- 对低频系数可以选择进行进一步的分解,或者直接量化和编码。
- 对压缩后的系数进行解码和逆小波变换,恢复原始信号。
小波编码在图像和视频压缩中得到广泛的应用。与传统的基于块变换的编码方法相比,小波编码具有更好的时频局部化特性,可以有效地处理信号或图像中的边缘和细节信息,提供更好的视觉质量和压缩效率。
虽然小波编码在一些应用中取得了良好的效果,但它也存在一些缺点,包括计算复杂度较高、固定尺度分析等。因此,随着新的编码算法和技术的不断发展,小波编码也逐渐与其他数据压缩技术结合使用,以求更好的压缩效果和适用性。
实验:离散余弦压缩与霍特林变换压缩
实验代码如下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimSun' # 设置为宋体或其他中文字体
# 离散余弦压缩
def DCTCompress(img, th=0.995):
fc = cv2.dct(img.astype(np.float32))
ef = fc * fc
E = np.sum(ef)
w = img.shape[0]
for i in range(img.shape[0]):
e = np.sum(ef[:i + 1, :i + 1])
if e / E > th:
w = i
break
if w < img.shape[0]:
fc[w + 1:, :] = 0
fc[:, w + 1:] = 0
restore = cv2.idct(fc)
print('离散余弦变换 能量损失率:', 1 - e / E, '压缩率:', (w / (img.shape[0])) ** 2)
return restore.astype(np.uint8)
# 霍特林变换压缩
def HaarCompress(img, m=25):
imgs = []
for i in range(0, img.shape[0], 8):
for j in range(0, img.shape[1], 8):
imgs.append(img[i:i + 8, j:j + 8])
x = np.array([img.flatten() for img in imgs]).T
A = np.dot(x, x.T)
w, v = np.linalg.eig(A)
idx = np.argsort(w)[::-1]
w = w[idx]
v = v[:, idx]
total = np.sum(w)
e = np.sum(w[m + 1:]) / total
print('霍特林变换 能量损失率:', e, '压缩率:', m / len(imgs))
y = np.dot(v[:, :m].T, x)
xr = np.dot(v[:, :m], y)
rimgs = [xr[:, i].reshape(8, 8) for i in range(xr.shape[1])]
rimgs = np.array(rimgs).reshape(img.shape[0] // 8, img.shape[1] // 8, -1)
restore = RestoreImage(rimgs)
return restore.astype(np.uint8)
# 图像降采样成低分辨率子图像
def DownSample(img, n):
r = img.shape[0] // n
c = img.shape[1] // n
Imgs = np.zeros((r, c, n * n), dtype=img.dtype)
for i in range(r):
for j in range(c):
for k in range(n * n):
di = k // n
dj = k % n
Imgs[i, j, k] = img[i * n + di, j * n + dj]
Img = np.zeros((r * n, c * n), dtype=img.dtype)
k = 0
for i in range(n):
for j in range(n):
Img[i * r:(i + 1) * r, j * c:(j + 1) * c] = Imgs[:, :, k]
k += 1
return Imgs, Img
# 子图像合成恢复原图像
def RestoreImage(imgs):
r, c, frame = imgs.shape
n = int(np.sqrt(frame))
Img = np.zeros((r * n, c * n), dtype=imgs.dtype)
for i in range(r):
i0 = i * n
for j in range(c):
j0 = j * n
for k in range(frame):
di = k // n
dj = k % n
Img[i0 + di, j0 + dj] = imgs[i, j, k]
return Img
# 读取图像
img = cv2.imread('C:/Users/Yuao/Pictures/learningTest/color.jpg', cv2.IMREAD_GRAYSCALE)
# 离散余弦压缩
restore = DCTCompress(img)
plt.subplot(121)
plt.imshow(restore, cmap='gray')
plt.title("离散余弦变换")
# 关闭坐标轴
plt.axis('off')
# 霍特林变换压缩
restore = HaarCompress(img)
plt.subplot(122)
plt.imshow(restore, cmap='gray')
plt.title('霍特林变换')
plt.axis('off')
plt.show()
实验结果:

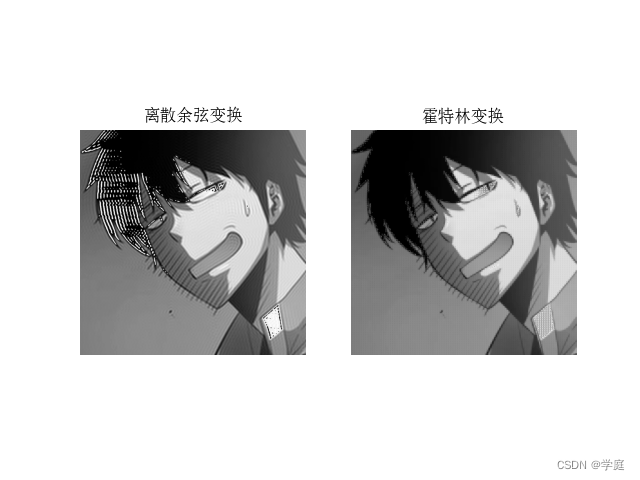
实验分析:
以下是对离散余弦压缩(Discrete Cosine Transform, DCT)和霍特林变换压缩(Haar Wavelet Transform)这两种压缩方法的实验结果分析:
- 图像质量:DCT压缩和Haar变换压缩在不同压缩比下可能会对图像质量产生不同的影响。通常情况下,DCT压缩对图像细节的保留更好,能够产生更高质量的重建图像,但可能出现压缩伪影。而Haar变换压缩则更加适用于简单结构的图像,对于复杂纹理区域压缩效果可能会较差。
- 压缩比:DCT通常能够实现较高的压缩比,可以在保持较好图像质量的同时,显著减小图像文件的大小。相比之下,Haar变换压缩的压缩比一般较低,因为Haar变换在每个尺度只能实现2倍的压缩。
8.3 数字图像水印
数字图像水印(Digital Image Watermarking)是一种在数字图像中嵌入隐藏信息的技术,用于保护图像的版权、验证图像的完整性或主人的身份。水印可以是一些不可见的信息,如数字代码、文本、图像或其他标识符,嵌入在原始图像中,并且应该对图像的视觉感知性能影响较小。
数字图像水印通常包含以下步骤:
- 水印嵌入(Embedding):选择要嵌入的水印信息,将其根据某种算法进行加密和压缩,然后将水印信息嵌入原始图像中。嵌入算法可以根据不同的要求进行设计,例如将水印嵌入到图像的特定区域或特定频率范围中。
- 水印提取(Extraction):当需要验证图像的水印信息时,水印提取算法被用来从包含水印的图像中提取出原始嵌入的水印信息。
- 水印检测和验证(Detection and Verification):对于接收到的含有水印的图像,进行水印检测和验证,以确定图像是否包含有效水印,以及该水印是否被篡改。
数字图像水印技术可以分为可见水印和不可见水印。可见水印指的是人眼可以看到的水印,通常用于版权保护和宣传,但易于被篡改。不可见水印是无法察觉的,更常用于版权保护或隐秘的身份验证。
数字图像水印技术在数字版权保护、图像验证、隐私保护等方面具有广泛的应用。然而,随着技术的发展,一些攻击方式(如压缩、滤波等)可能会对水印的可靠性和鲁棒性产生影响。因此,设计强大的数字图像水印算法是一个重要的研究方向,以提高水印的可见性和鲁棒性。
实验:在彩色图像各通道嵌入不同内容的数字盲水印
实验代码如下:
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
# 在彩色图像各通道嵌入不同内容的数字盲水印
img = cv.imread('C:/Users/Yuao/Pictures/learningTest/color.jpg', 1) # 加载原始图片,单通道
# 加载或生成水印信息
watermark = cv.imread('C:/Users/Yuao/Pictures/learningTest/10001.jpg', 0) # # 加载水印图片,单通道
markResize = cv.resize(watermark, img.shape[:2]) # 调整图片尺寸与 img 大小相同
_, binary = cv.threshold(markResize, 175, 1, cv.THRESH_BINARY) # 0/1 二值图像
mark1 = np.ones(img.shape[:2], np.uint8)
cv.putText(mark1, str(np.datetime64('today')), (50, 100), cv.FONT_HERSHEY_SIMPLEX, 2, 0, 2)
cv.putText(mark1, str(np.datetime64('now')), (50, 150), cv.FONT_HERSHEY_DUPLEX, 1, 0)
mark2 = np.ones(img.shape[:2], np.uint8)
cv.putText(mark2, "test for csdn", (50, 300), cv.FONT_HERSHEY_SIMPLEX, 2, 0, 2)
cv.putText(mark2, "Copyright@yuaf, 2023", (50, 350), cv.FONT_HERSHEY_DUPLEX, 1, 0)
# 对原始图像嵌入水印
# img: (g7,g6,...g1,0) -> imgH7: (g7,g6,...g1,0)
imgH7 = (img >> 1) << 1 # 右移->左移,图像最低位 LSB=0
# imgH7: (g7,g6,...g1,0) OR b -> imgMark: (g7,g6,...g1,b)
# 对各通道分别插入数字水印 binary,mark1,mark2
b = cv.bitwise_or(imgH7[:, :, 0], binary) # (g7,g6,...g1,b)
g = cv.bitwise_or(imgH7[:, :, 1], mark1) # (g7,g6,...g1,m1)
r = cv.bitwise_or(imgH7[:, :, 2], mark2) # (g7,g6,...g1,m2)
imgMark = cv.merge([b, g, r])
# # 从嵌入水印图像中提取水印
b, g, r = cv.split(imgMark) # 拆分为 BGR 独立通道
bMark = cv.bitwise_and(b, 1) # 按位与运算,取 B 通道的最低位 LSB
gMark = cv.bitwise_and(g, 1) # 按位与运算,取 G 通道的最低位 LSB
rMark = cv.bitwise_and(r, 1) # 按位与运算,取 R 通道的最低位 LSB
plt.figure(figsize=(9, 6))
plt.subplot(231), plt.title("original gray"), plt.axis('off')
plt.imshow(cv.cvtColor(img, cv.COLOR_BGR2RGB))
plt.subplot(232), plt.title("watermark"), plt.axis('off')
plt.imshow(binary, cmap='gray')
plt.subplot(233), plt.title("embedding watermark"), plt.axis('off')
plt.imshow(cv.cvtColor(imgMark, cv.COLOR_BGR2RGB))
plt.subplot(234), plt.title("watermark ch-B"), plt.axis('off')
plt.imshow(bMark, cmap='gray')
plt.subplot(235), plt.title("watermark ch-G"), plt.axis('off')
plt.imshow(gMark, cmap='gray')
plt.subplot(236), plt.title("watermark ch-R"), plt.axis('off')
plt.imshow(mark2, cmap='gray')
plt.show()
实验结果:

实验分析:
分离彩色图像的各个通道进行数字水印实验是一种常见的方法,下面是对这种实验的分析:
- 相同内容的数字水印嵌入:在这种情况下,将相同的数字水印嵌入到彩色图像的不同通道中。通过将同一水印信息嵌入到不同通道中,可以提高水印的鲁棒性和可靠性,因为不同通道中的信息具有一定的冗余性。当进行数字水印的检测时,可以从不同通道中提取水印信息,并进行融合以恢复原始水印内容。
- 不同内容的数字水印嵌入:在这种情况下,将不同的数字水印嵌入到彩色图像的不同通道中。这样可以实现在一个图像中嵌入多个水印,每个水印对应一个通道。每个数字水印可以包含不同的信息,例如不同的标识符、所有者信息等。通过这种方式,可以实现多个水印的同时嵌入和提取,提供更多的图像信息隐藏能力。