写在前面
都知道语音识别有GMM-HMM模型,也分别了解了什么是:
GMM(混合高斯模型)
https://blog.csdn.net/qq_37385726/article/details/89198387
MMC(马尔可夫链)
通俗理解马尔科夫链_啧啧啧biubiu的博客-CSDN博客_通俗理解马尔科夫链
HMM(隐马尔可夫模型)
通俗理解隐马尔科夫模型_啧啧啧biubiu的博客-CSDN博客
但是却发现不清楚GMM与HMM与语音识别有什么关系,更不知道GMM-HMM模型究竟是什么
好像没有看到有系统讲解很清楚的博客
于是我根据这些零散的学习,整理出了一套比较方便适于理解的系列博客。
由于文章的主要内容均为借鉴,故标为转载。
原始整理为:qq_37385726
转载请注明出处
系列博客
目录
GMM-HMM模型应用于语音识别任务步骤及原理
一、训练GMM-HMM模型
1. 对原始语音信号预处理
2. 对原始语音提取声学特征(Acoustic Feature)
3. GMM利用EM算法建模声学特征
4. 利用声学特征训练HMM
二、应用GMM-HMM模型识别语音
GMM-HMM模型应用于语音识别任务步骤及原理
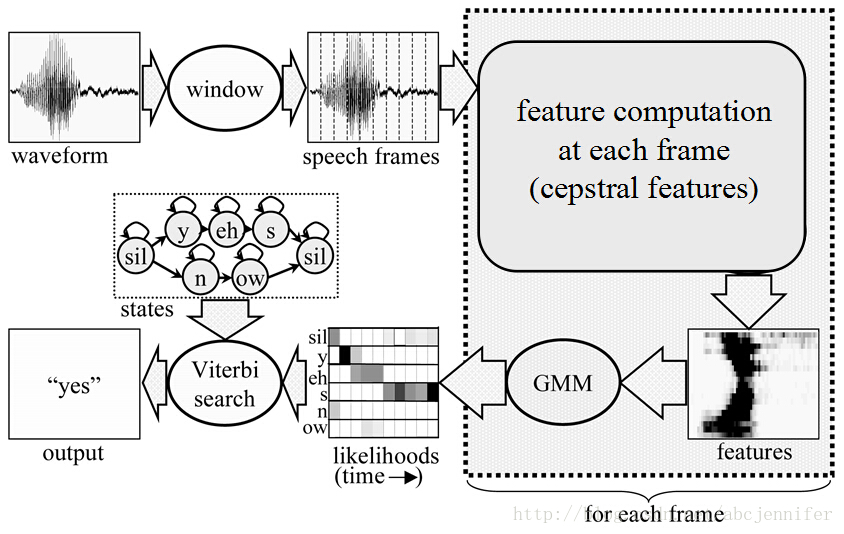
一、训练GMM-HMM模型
1. 对原始语音信号预处理
-
信号预处理
通过消除噪声和信道失真对语音进行增强。
-
分帧
分帧就涉及到帧长,对于帧长要满足的条件有两点:
- 正常语速下,音素的持续时间大约是 50~200 毫秒,所以帧长一般取为小于 50 毫秒。
- 语音的基频,男声在 100 赫兹左右,女声在 200 赫兹左右,换算成周期就是 10 毫秒和 5 毫秒。既然一帧要包含多个周期,所以一般取至少 20 毫秒。
综上
帧长一般取为 20 ~ 50 毫秒,20、25、30、40、50 都是比较常用的数值
,以上摘自
知乎
逻辑上很合理的解释,
我通常听见的是(10-30ms)
一帧的数据长度 N=帧时间长度/T=帧时间长度(单位秒)*fs(单位Hz)
可以理解为若干帧对应一个音素,若干音素对应一个单词,如果我们想要识别对应的单词状态,我们只要知道对应的帧状态就行
2. 对原始语音提取声学特征(Acoustic Feature)
在过去,最流行的语音识别系统采用MFCC或RASTA-PLP作为特征向量。
3. GMM利用EM算法建模声学特征
GMM被整合进HMM中,用来拟合基于状态的输出分布。
原始的语音数据经过短时傅立叶变换或取倒谱后会成为特征序列,在忽略时序信息的条件下,GMM就非常适合拟合这样的语音特征。
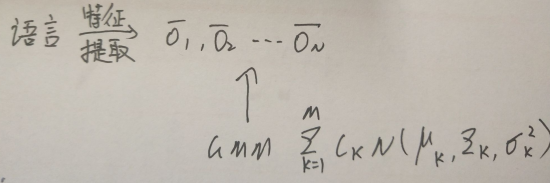
用GMM建模声学特征(Acoustic Feature)O1,O2,…,On,可以理解成:
每一个特征是由一个音素确定的,即不同特征可以按音素来聚类。由于在HMM中音素被表示为隐变量(状态),故等价于:
每一个特征是由某几个状态确定的,即不同特征可以按状态来聚类。
则设P(O|Si)符合正态分布,则根据GMM的知识,O1,O2,…,On实际上就是一个混合高斯模型下的采样值。
因此,GMM被整合进HMM中,用来拟合基于状态的输出分布。
4. 利用声学特征训练HMM
确定状态转移矩阵,是执行解码问题的基础。
而状态转移矩阵的确定即等价于HMM的训练问题(即状态转移矩阵u=max(P(u|O)))
,从语音特征序列中利用EM算法学习得到状态转移矩阵。
二、应用GMM-HMM模型识别语音
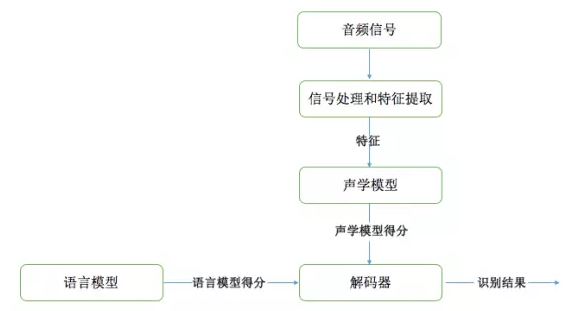
-
对待识别语音做信号预处理
-
对待识别语音提取声学特征
-
对声学特征利用Viterbi算法解码
对声学特征解码后得到的是状态序列,即音素序列。
如果把声学模型的结果表示为句子,往往效果不尽如意,所以还需要用语言模型把识别出的各个音素纠正为正确的句子。
HMM一开始是在信息论中应用的,后来才被应用到自然语言处理还有其他图像识别等各个方面。
下面举两个例子说明他的应用,一个是输入法的整句解码,一个是语音识别。
有图为证:
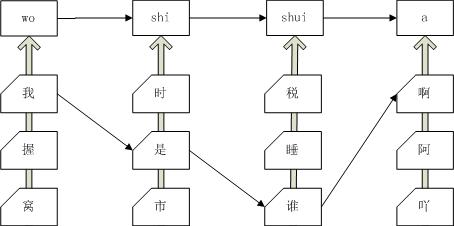
将上图中的拼音换成语音,就成了语音识别问题,转移概率仍然是二元语言模型,其输出概率则是语音模型,即语音和汉字的对应模型。
-
利用语言模型优化
对声学特征解码后得到的是状态序列,即音素序列。
如果把声学模型的结果表示为句子,往往效果不尽如意,所以还需要用语言模型把识别出的各个音素纠正为正确的句子。