环境:
Windows 10+
tensorflow-gpu-1.6.0
前期准备:完成
Object Detection api
配置
文件目录结构
├─Annotation
│ └─XML文件
├─data
│ ├─csv文件
│ └─Record文件
├─images
│ └─图片
├─eval
│ └─测试集结果
├─training
│ ├─pbtxt文件
│ ├─config文件
│ └─model.ckpt文件
├─model
│ └─输出模型
一、准备图片
利用labelImg截取图片中的对象并添加标签,生成XML文件保存在Annotation目录下,注意文件命名与图片对应同时命名遵从以一定规律。
labelImg下载地址:https://github.com/tzutalin/labelImg/releases
批量命名可参考下面命令,用法cd到当前目录并运行:
@echo off&setlocal EnableDelayedExpansion
set a=1
for /f "delims=" %%i in ('dir /b *.jpg') do (
if not "%%~ni"=="%~n0" (
ren "%%i" "20180609(data)!a!.jpg"
set/a a+=1
)
)
二、xml转换到csv
因在制作用于训练的
.record格式文件时用到的是csv格式文件,所以需要将xml转换到csv,转换可以通过下面的python程序处理,其中程序中的
xml_df = xml_to_csv(image_path) image_path为xml目录路径,生成的csv文件默认保存在程序目录下。
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
image_path = os.path.join(os.getcwd(), 'annotations')
xml_df = xml_to_csv(image_path)
xml_df.to_csv('raccoon_labels.csv', index=None)
print('Successfully converted xml to csv.')
main()
三、数据集整理

在使用数据集进行训练前需将数据集分为训练集和测试集。训练集的作用在于训练模型,测试集的作用在于测试训练后模型,对数据集分离的目的在于避免产生过拟合使得训练出来的模型难以泛化到新的数据,两者的比例一般为9:1,可根据实际进行调整。
- 训练集:用于训练模型的子集。
- 测试集:用于测试训练后模型的子集。
四、生成tfrecord格式文件
官方在教程中提供了
生成自己的
tfrecord格式文件,参考其方法及国外论坛的资料,编写
generate_tfrecord.py
用于生成自己的
tfrecord格式文件
,其中#TO-DO replace this with label map下的内容需要根据自己的数据集进行修改,修改为自己数据集的标签。
"""
Usage:
# From tensorflow/models/
# Create train data:
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=train.record
# Create test data:
python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=test.record
"""
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'cola':
return 1
elif row_label == 'milk':
return 2
else:
None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(os.getcwd(), 'images')
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()运行格式如下,默认图片在当前文件夹images文件下。
python generate_tfrecord.py --csv_input=csv文件路径
--output_path=输出record文件名字(**.record)
五、准备训练文件
1、.pbtxt文件,文件内容根据标签确定。
item {
id: 1
name: 'cola'
}
item {
id: 2
name: 'milk'
}
2、model.ckpt文件为训练模型,一般采用预训练模型,可降低训练所需时间,根据实际需求选择适合自己的模型,下载完成后解压,将名字带有model.ckpt的三个文件移动到training目录下。
各种模型下载链接:
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
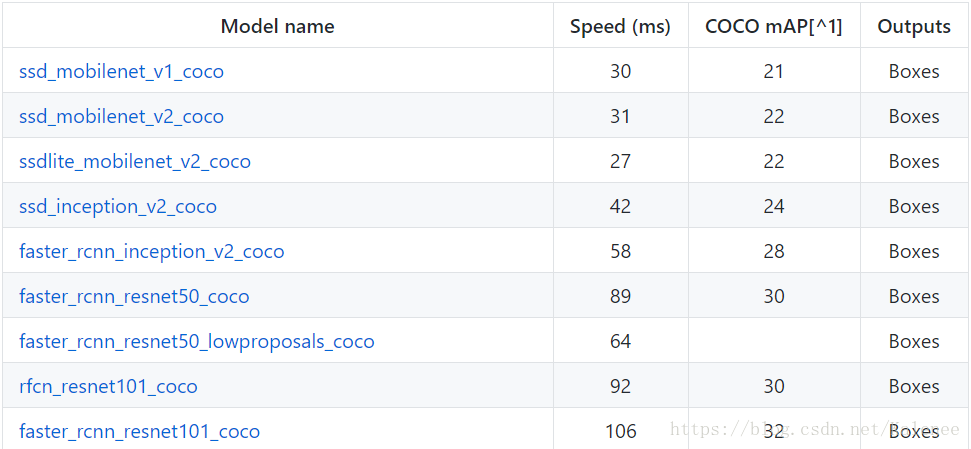
3、.config文件在目录models-master\research\object_detection\samples\configs下选择,根据选择的预训练模型选择对应.config文件,同时修改文件中路径为对应目录
fine_tune_checkpoint: "../training/model.ckpt"
train_input_reader: {
tf_record_input_reader {
input_path: "../data/train.record"
}
label_map_path: "../training/*.pbtxt"
}
eval_input_reader: {
tf_record_input_reader {
input_path: "../data/eval.record"
}
label_map_path: "../training/*.pbtxt"同时根据硬件条件选定合适的批次(batch_size)和初始学习速率(initial_learning_rate)。
批次(batch)是每一次迭代中模型训练使用的样本集,批次规模(batch_size)为一个批次中的样本数量。一般情况下对于小数据集批次规模越大越好,这样可以提高计算的速度和效率,同时降低训练震荡,若数据集足够小,可采用全数据集的形式进行训练,但这种情况容易造成计算量增长过大导致溢出,因此批次规模的大小需根据实际情况进行设置。
学习速率(learning rate)是在训练模型过程中用于梯度下降的一个变量,在训练过程中,每次迭代梯度下降法都会将学习速率与梯度相乘,因此其值是随着训练进行不断变化。而初始学习速率(initial_learning rate)是模型开始训练前设置的最开始的学习速率,在训练过程中,模型会根据学习率变化策略以初始学习速率为起点设置学习速率,初始学习速率一般情况下应设置为一个较小的值,然后在之后训练过程中逐步调大。
train_config: {
batch_size: 6
optimizer {
rms_prop_optimizer: {
learning_rate: {
exponential_decay_learning_rate {
initial_learning_rate: 0.004
decay_steps: 800720
decay_factor: 0.95
}
}
momentum_optimizer_value: 0.9
decay: 0.9
epsilon: 1.0
}
}
batch_size: 6
optimizer {
rms_prop_optimizer: {
learning_rate: {
exponential_decay_learning_rate {
initial_learning_rate: 0.004
decay_steps: 800720
decay_factor: 0.95
}
}
momentum_optimizer_value: 0.9
decay: 0.9
epsilon: 1.0
}
}
六、训练模型
建议:windows环境下建议采用git base
训练所用python文件都在..\models-master\research\object_detection目录下,可复制到数据集文件夹中,运行时需cd到python文件路径下。
模型训练命令,训练结果保存于training目录下。
python train.py \
--logtostderr \
--pipeline_config_path=${定义的Config} \
--train_dir=${训练结果要存放的目录}监视训练状况命令,建议cd 到training目录上一级然后运行,运行后将窗口中显示的链接复制到浏览器地址栏。
tensorboard --logdir=training模型验证命令,输出结果保存于eval目录下。
python eval.py \
--logtostderr \
--pipeline_config_path=${定义的Config} \
--checkpoint_dir=${训练结果存放的目录}
--eval_dir=${输出结果目录}
模型验证可视化命令,建议cd 到eval目录上一级然后运行
tensorboard --logdir=eval
七、模型导出
模型导出命令,model.ckpt需选定training目录下其中一个model.ckpt,因为在训练过程中,程序会定期进行保存,路径建议采用绝对路径。
python export_inference_graph.py \
--input_type image_tensor
--pipeline_config_path config文件path \
--trained_checkpoint_prefix model.ckpt-*文件path \
--output_directory 输出结果路径
在output_directory路径下会生成三个文件:
frozen_inference_graph.pb、model.ckpt.data-00000-of-00001、model.ckpt.meta、model.ckpt.data
参考
https://developers.google.com/machine-learning/crash-course/prereqs-and-prework