本文参考《推荐系统实践》中基于用户的协同过滤算法内容。基于老师上课讲解,自己实现了其中的代码,了解了整个过程。
UserCF算法实现
实现原理
基于用户的协同过滤算法:
第一步,找到和目标用户兴趣相似的用户集合
第二步,找到这个集合中的用户喜欢的物品,然后过滤掉目标用户已经看到过或听说过的物品(发生过用户行为的),把没有听说过的物品推荐给目标用户
模拟数据
数据格式为 u-i(用户-物品)字典
A B C ……为用户 a b c ……为物品
并添加了用户分别对某一物品的评分
import math
from operator import itemgetter
UserCF_dict = {"A": {"a": 4.0, "b": 0.0, "c": 5.0, "d": 3.5, "e": 0.0, "f":2.0, "h":0.0},
"B": {"a": 0.0, "b": 3.0, "c": 4.5, "d": 1.0, "e": 3.5, "f":0.0, "h":3.0},
"C": {"a": 2.5, "b": 2.0, "c": 1.0, "d": 0.0, "e": 3.0, "f":4.0, "h":0.0},
"D": {"a": 1.0, "b": 0.0, "c": 0.0, "d": 6.5, "e": 1.5, "f":0.0, "h":4.0},
"E": {"a": 0.0, "b": 4.0, "c": 3.0, "d": 0.0, "e": 2.0, "f":1.0, "h":1.5},
"F": {"a": 4.0, "b": 1.5, "c": 0.0, "d": 0.5, "e": 1.5, "f":3.5, "h":0.0}}
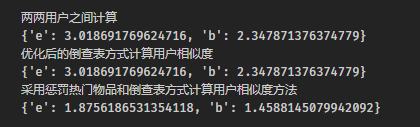
两两用户之间计算
用两两用户之间计算兴趣相似度,给定用户u和用户v,其中N(u)表示用户u曾经有过用户行为的物品集合(u喜欢的物品集合),N(v)表示用户v曾经有过用户行为的物品集合,然后我们有两种公式计算uv的兴趣相似度:
1.Jaccard公式
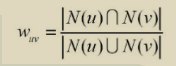
2.余弦计算相似度公式
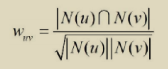
附图解释:

def UserSimilarity(dict_):
w = dict()
for u in dict_.keys():
w[u] = dict() #太久不写生疏了 字典要一步一步添加
for v in dict_.keys():
if u == v :
continue
# print(dict_[u].keys)
u_dict = set([k for k in dict_[u].keys() if dict_[u][k] != 0]) # 对于u用户找出它发生过用户行为的物品集合 (即打过评分的物品集合)
v_dict = set([k for k in dict_[v].keys() if dict_[v][k] != 0])
w[u][v] = len(u_dict & v_dict)
w[u][v] /= math.sqrt(len(u_dict) * len(v_dict) * 1.0)
return w
# len(UesrCF_dict['A'] & UesrCF_dict['B'])
w1 = UserSimilarity(UserCF_dict)
优化后的倒查表方式计算用户相似度
根据模拟数据建立物品到用户的倒查表,即对于每个物品保存对该物品产生过用户行为的用户列表
count字典存的是统计两个用户间是否有相同喜欢的物品,大大减少两两用户间没有相关性却遍历进行计算的时间
def UserSimilarity_better(dict_):
items_users = dict()
for u,items in dict_.items():
# print(u)
for i in items.keys():
# print(i)
items_users.setdefault(i,set())
# print(dict_[u][i])
if dict_[u][i] != 0:
items_users[i].add(u)
# print(items_users[i])
# print(items_users)
count = dict()
num = dict()
for i,ur in items_users.items(): #i:{a,b,c,d,……}
for u in ur:
num.setdefault(u,0)
num[u] += 1
# items_users.setdefault(i,set())
count.setdefault(u,dict()) #key: A B C ……
for v in ur:
count[u].setdefault(v,0)
if u == v:
continue
count[u][v] += 1 #gonggong
w = dict()
for u,realted_u in count.items():
w.setdefault(u,dict())
for v,cuv in realted_u.items():
if u == v:
continue
w[u].setdefault(v,0)
w[u][v] = cuv/math.sqrt(num[u] * num[v] * 1.0)
return w
w2 = UserSimilarity_better(UserCF_dict)
采用惩罚热门物品和倒查表方式计算用户相似度方法
同倒查表方式,只不过增加了一个 log函数 降低热门物品的影响

def UserSimilarity_best(dict_):
items_users = dict()
for u,items in dict_.items():
# print(u)
for i in items.keys():
# print(i)
items_users.setdefault(i,set())
# print(dict_[u][i])
if dict_[u][i] != 0:
items_users[i].add(u)
count = dict()
num = dict()
for i,ur in items_users.items(): #i:{a,b,c,d,……} ur:用户集合 热门
for u in ur:
num.setdefault(u,0)
num[u] += 1
# items_users.setdefault(i,set())
count.setdefault(u,dict()) #key: A B C ……
for v in ur:
count[u].setdefault(v,0)
if u == v:
continue
count[u][v] += 1/math.log(1 + len(ur)) #gonggong log惩罚
w = dict()
for u,realted_u in count.items():
w.setdefault(u,dict())
for v,cuv in realted_u.items():
if u == v:
continue
w[u].setdefault(v,0)
w[u][v] = cuv/math.sqrt(num[u] * num[v] * 1.0)
return w
w3 = UserSimilarity_best(UserCF_dict)
推荐函数
在推荐函数中要注重k值的选取,从表格中可以看出随着k值变化 (准确率,召回率)先增加后减少 而覆盖率先减少后增加,表明我们推荐的物品比较集中 不太好 应尽量覆盖全面商品
流行度逐渐增加,表现我们推荐的物品集中于热门物品。应做好K值的选取。

def recommend(u,dict_,w_,k):
#先得到用户对于喜欢物品的字典
#再找到目标用户相似度最高的k个用户
#获取k个用户的喜欢物品 删掉其中目标用户已发生过行为的物品
#再计算物品的推荐分数 = 目标用户与前k用户的相似度*前k用户喜欢物品的评分(求和)
cout = dict()
for i in dict_.keys():
cout[i] = set()
for j in dict_[i].keys():
if dict_[i][j] != 0:
cout[i].add(j)
# print(cout)
# print(w_[u])
x = sorted(w_[u].items(),key = itemgetter(1),reverse = True)[:k]
# print(x)
cout_item = dict()
for i in range(k):
# cout_item[x[i]] = set()
cout_item[x[i][0]] = [ki for ki in cout[x[i][0]] if ki not in cout[u]]
# print(cout_item)
rank = dict()
for j in cout_item.keys():
for i in range(len(cout_item[j])):
# print(cout_item[j][i])
rank.setdefault(cout_item[j][i],0)
rank[cout_item[j][i]] += w_[u][j] * dict_[j][cout_item[j][i]]
# rank[ans] = 0
print(rank)
#调用
ans = ['两两用户之间计算','优化后的倒查表方式计算用户相似度','采用惩罚热门物品和倒查表方式计算用户相似度方法']
li = [w1,w2,w3]
for i in range(3):
print(ans[i])
recommend('A',UserCF_dict,li[i],2)