1.k-NN简介
k-NN,即K邻近法(k-nearest neighbor ),是一种基本分类与回归方法,本文只介绍分类方法。,应用场景有字符识别、文本分类、图像识别等领域.
1.1基本思想
对每一个测试样本,基于事先选择的距离度量,KNN算法在训练集中找到距离最近(最相似)的k个样本,然后将k个样本的类别的投票结果作为测试样本的类别。
1.2三要素
k值的选择,距离度量,分类决策规则
1.3k-NN流程
1)计算已知类别数据集中的点与当前点之间的距离
2)按距离递增次序排序
3)选取与当前点距离最小的k个点
4)统计前k个点所在的类别出现的频率
5)返回前k个点出现频率最高的类别作为当前点的预测分类
1.4 优缺点
优点
:
- 简单有效
- 重新训练的代价低
- 算法复杂度低
- 适合类域交叉样本
- 适合大样本自动分类
缺点
- 惰性学习,训练不能得到判别式,而是记住整个样本集
- 类别分类不标准化
- 输出可解释性不强
- 样本不均衡,容易误判,需要采用加权计算
- 计算量大
- 需要一直保留样本,储存空间大
- 分类时间随训练样本增加而线性增加
2.k-NN 模型
当上述三要素确定后,我们可以认为基本确定了k-NN 算法模型,那么我们谈谈这三要素具体是什么,要怎么去确定
2.1k值
即是要选择的距离最近的样本的个数,这个值会对模型结果产生重大影响
如果k值取的过小,会导致模型较复杂,容易过拟合,如果邻近的点恰好是噪声,那么会预测错误;相反的,如果偏大,近似误差会比较大,模型变得简单,对较远的临近点(不相似的)也起到预测作用,使预测错误
2.2 距离度量
欧式距离
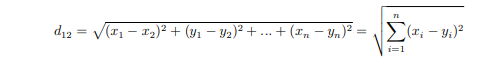
曼哈顿距离(城市街区距离)
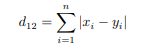
明可夫斯基距离(明氏距离)

切比雪夫距离
数学上,切比雪夫距离(Chebyshev distance)是向量空间中的一种度量,二个点之间的距离定义为其各坐标数值差的最大值。以 (x1, y1) 和 (x2, y2) 二点为例,其切比雪夫距离为max(|x2 − x1|, |y2 − y1|)。
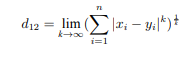
杰卡德距离
杰卡德相似系数
:两个集合 A 和 B 的交集元素在 A、B 的并集中所占的比例,称为两个
集合的杰卡德相似系数,用符号 J(A,B) 表示。
杰卡德距离
:与杰卡德相似系数相反的概念,即杰卡德距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。这是杰卡德距离(Jaccard distance)。
杰卡德相似系数与杰卡德距离的应用
:可将杰卡德相似系数用在衡量样本的相似度上。样本 A 与样本 B 是两个 n 维向量,而且所有维度的取值都是 0 或 1。例如:(0111) 和 B(1011)。我们将样本看作一个集合,1 表示集合包含该元素,0 表示集合不包含该元素。
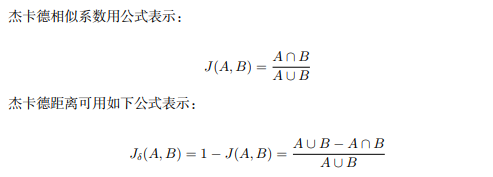
汉明距离
在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个
数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。
马氏距离
马氏距离是基于样本分布的一种距离。物理意义就是在规范化的主成分空间中的欧氏距离。所谓规范化的主成分空间就是利用主成分分析对一些数据进行主成分分解。再对所有主成分分解轴做归一化,形成新的坐标轴。由这些坐标轴张成的空间就是规范化的
主成分空间。
标准化欧氏距离
标准化欧氏距离是针对欧氏距离的缺点而作的一种改进。思路:既然数据各维分量的分布不一样,那先将各个分量都“标准化”到均值、方差相等。假设样本集X的均值(mean)为m,标准差(standard deviation)为s,X的“标准化变量”表示为:
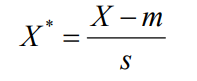
标准化欧氏距离公式:
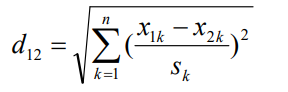
2.3分类规则
一般采用少数服从多数的思想
2.4 算法评估
实现k近邻法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索。这在特征空间的维数大及训练数据容量大时尤其必要。k近邻法最简单的实现是线性扫描(穷举搜),即要计算输入实例与每一个训练实例的距离。计算并存储好以后,再查找K近邻。当训练集很大时,计算非常耗时。为了提高kNN搜索的效率,可以考虑使用特殊的结构存储训练数据,以减小计算距离的次数。