豆瓣信息爬取
爬虫是根据自己所需在网络中进行信息爬取
注意:***
网络爬虫要在法律允许范围内进行,切记不要越线;
***
#引入库
import requests
import urllib.request
import lxml
import lxml.html
from bs4 import BeautifulSoup
import unicodecsv as ucsv
import re
import csv
import json
import pandas as pd
from lxml import etree
import time
1、根据豆瓣信息
分类页面
,查看
Network
,在刷新内容,就会出现图一中标红的文件,点击就会看见图二中电影的信息;
我们可以更改年限来爬去不同年代的电影的信息;
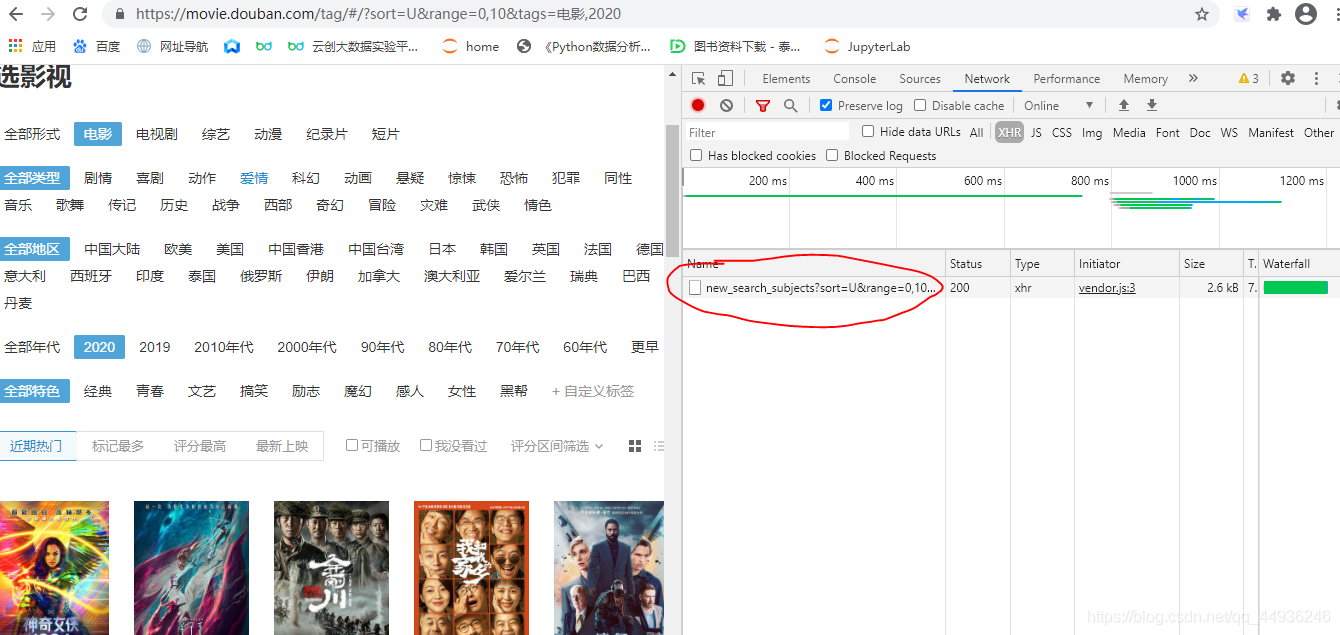
图一

图二
代码
movie_result = pd.DataFrame()
datas=[]
urls=[]
a = ["https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1&start={}&year_range=2017,2017".format(j) for j in range(0,1000,20)]
b = ["https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1&start={}&year_range=2016,2016".format(j) for j in range(0,1000,20)]
c = ["https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1&start={}&year_range=2015,2015".format(j) for j in range(0,1000,20)]
urls.extend(a)
urls.extend(b)
urls.extend(c)
a=0
for j in urls:
print(j)
try:
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
response = requests.get(j, headers=headers)
bs = json.loads(response.text)
except Exception as error:
print(error)
continue
time.sleep(5)
for i in bs['data']:
casts = i['casts'] #主演
directors = i['directors'] #导演
rate = i['rate'] #评分
title = i['title'] #片名
url = i['url'] #网址
datas.append([title,rate,directors,casts,url])
a+=0
if a%50==0:
time.sleep(10)
# 防止程序电脑关机,保存信息到表格中
pp= pd.DataFrame(datas)
pp.to_csv('./data1.csv',index=False)
爬取信息如下:
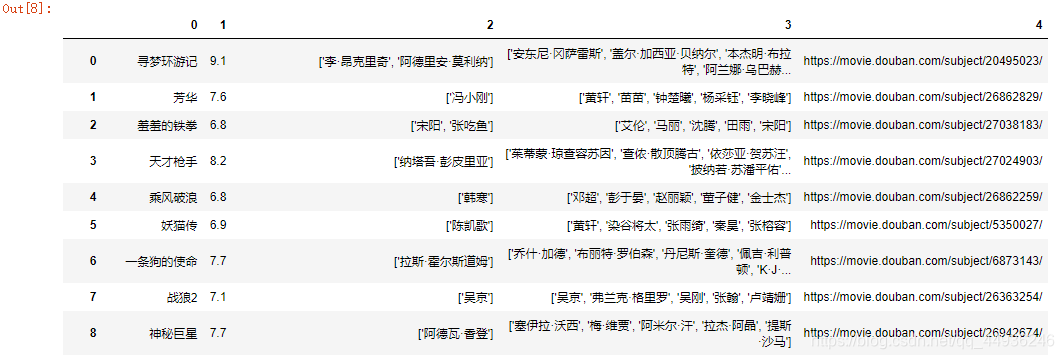
2、根据第一次爬取的信息,我们可以得到每部电影的具体url,来爬取他具体的信息,如年代,时长,主演,导演,国家,评分等;我们根据第一得到的url,来获取该电影的
IMDB连接
来获取后期要爬取的票房;
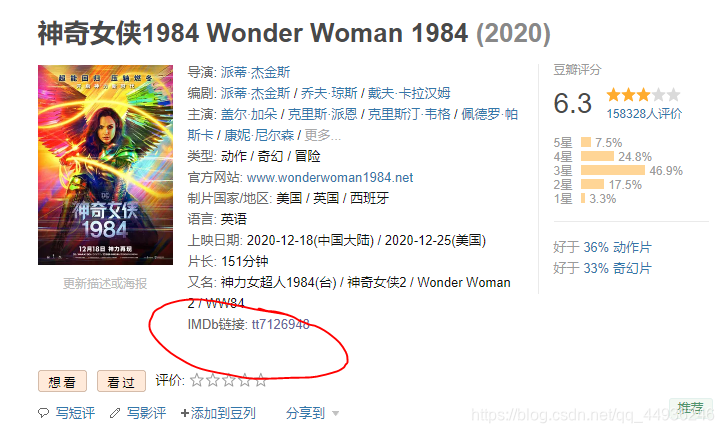
图三
代码
o = pd.read_csv('./data.csv')
datas_1=[]
a=0
for i in o['4']:
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
try:
html = requests.get(i,headers = headers)
print(html)
bs = etree.HTML(html.text)
except:
print('错误')
time.sleep(2)
system=[]#类型
for i in bs.xpath("//div[@id = 'info']/span[@property='v:genre']"):
system.append(i.text)
try:
runtime = bs.xpath("//div[@id = 'info']/span[@property='v:runtime']")[0].text#时间——片长
except:
runtime=None
try:
Time = bs.xpath('//div[@id = "content"]/h1/span')[1].text #时间_年
except:
Time=None
try:
IMDB = bs.xpath("//div[@id = 'info']/a")[-1].xpath('@href')#IMDB
except:
IMDB=None
print([IMDB,Time,runtime])
datas_1.append([IMDB,Time,runtime,system])
a+=1
print(a)
if a%50==0:
time.sleep(20)
time.sleep(5)
#pp= pd.DataFrame(datas_1)
pp.to_csv('./data2.csv',index=False)
爬取信息如下:

3、根据我们第二步爬取的IMDB的url,我们来爬去该电影的
票房
,
国家
;
代码
pp = pd.read_csv('./data2.csv')
pp.columns=['url','年','时长','leix']
data_7=[]
for i in pp['url']:
try:
data_7.append(i[2:-2])
except:
data_7.append(None)
import numpy as np
data_1000=[]
u = 0
for i in data_7:
print(i)
if i==None:
print(i)
money=None
city=None
else:
if i[:27]!='https://www.imdb.com/title/':
money=None
city=None
else:
try:
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
#requests.packages.urllib3.disable_warnings()
r = requests.get(i)
html = etree.HTML(r.text)
money=html.xpath("//div[@id = 'titleDetails']/div//*[text()='Cumulative Worldwide Gross:']/../text()")#票房
city =html.xpath("//div[@id = 'titleDetails']/div//*[text()='Country:']/../a/text()")#国家
Time =html.xpath("//div[@id = 'titleDetails']/div//*[text()='Runtime:']/../time/text()")#时长
print([money,city,Time])
#time.sleep(3)
except:
print('错误')
money=None
city=None
Time=None
# if u%50==0:
# time.sleep(10)
u+=1
print(u)
data_1000.append([money,city,Time])
print(len(data_1000))
pp.to_csv('./data3.csv',index=False)
爬取信息如下:

感谢评论点赞!
版权声明:本文为qq_44936246原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。