https://yifdu.github.io/2018/12/05/Embedding%E5%B1%82/
pytorch 中embedding词向量的使用
https://blog.csdn.net/david0611/article/details/81090371
import torch
from torch import nn
from torch.autograd import Variable
随机初始化的过程
# 定义词嵌入
embeds = nn.Embedding(2, 5) # 2 个单词,维度 5
# 得到词嵌入矩阵,开始是随机初始化的
torch.manual_seed(1)
print(" random embeds.weight{}".format(embeds.weight))
加载预训练的词向量
pretrained_weight = np.array(args.pretrained_weight) # 已有词向量的numpy
self.embed.weight.data.copy_(torch.from_numpy(pretrained_weight))
访问第 50 个词的词向量
embeds = nn.Embedding(100, 10) # embedding size为10
embeds(Variable(torch.LongTensor([50])))
读取多个向量
输入为两个维度(batch的大小,每个batch的单词个数),输出则在两个维度上加上词向量的大小。
Input: LongTensor (N, W)
N = mini-batch, W = number of indices to extract per mini-batch
Output: (N, W, embedding_dim)
# an Embedding module containing 10 tensors of size 3
embedding = nn.Embedding(10, 3)
# 每批取两组,每组四个单词
input = Variable(torch.LongTensor([[1,2,4,5],[4,3,2,9]]))#[[1,2,4,5],[4,1,2,5]])
a = embedding(input) # 输出2*4*3
print(a[0],a[1])
Embedding 层详解
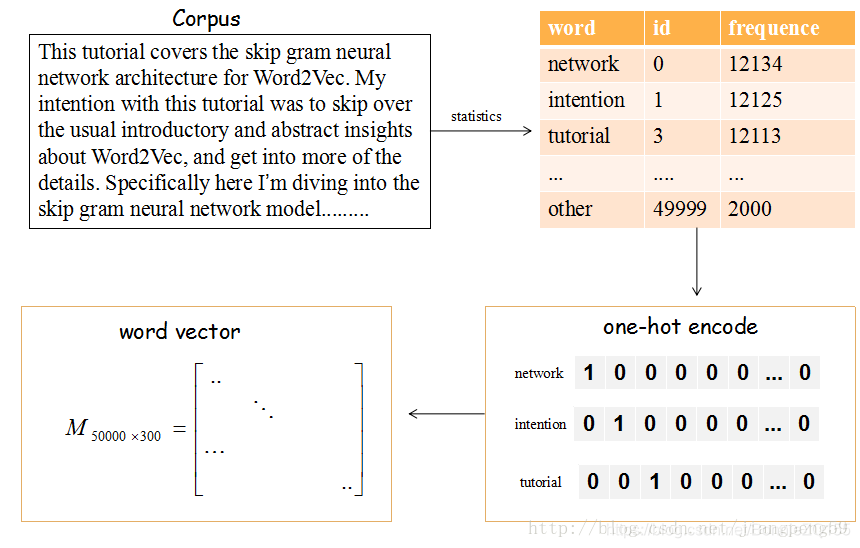
流程
(1)提取文章所有的单词,把所有单词降序排序(取前50000个,表示常出现的单词).
(2)每个编号ID都可以使用50000维的二进制(one-hot)表示
(3)产生一个矩阵M,行大小维词的个数5000,列大小为词向量的维度(嵌入的维度),比如矩阵的第一行就是编号ID=0,即network对应的词向量
矩阵怎么获得呢??
在Skip-gram模型中,随机初始化它,然后使用神经网络来训练这个权重矩阵
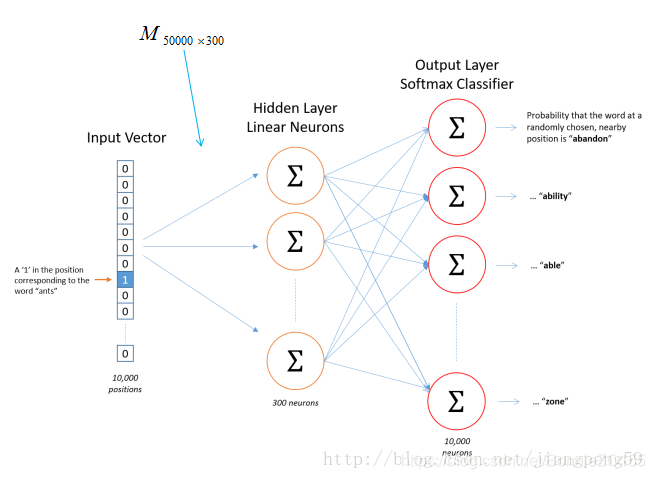
https://www.cnblogs.com/lindaxin/p/7991436.html
# –
– coding: utf-8 –
–
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
word_to_ix = {'hello': 0, 'world': 1}
embeds = nn.Embedding(2, 5)
hello_idx = torch.LongTensor([word_to_ix['hello']])
hello_idx = Variable(hello_idx)
hello_embed = embeds(hello_idx)
print(hello_embed)