原文地址:
https://www.cnblogs.com/bjwu/p/9448043.html
这次介绍Item(User)相似度的计算方法,其广泛运用于基于邻域的协同过滤算法的推荐系统。简而言之,基于邻域,就是基于相邻的元素进行推荐,而相邻元素的得到过程就是相似度的计算过程。
对于空间上的点来说:传统机器学习模型中KNN的距离度量方法(如欧式距离等),距离越近的点我们把他们归为一类,也可以说他们更相似。
对于空间上的向量来说:方向更相同,向量越相似,这就是cosine度量方法的原理。
问题来了,我们得到不同物品/用户的相似度有什么用呢?
回答:从ItemCF的角度来说,在得到物品之间的相似度ωij(物品 i 和 j )之后,通过如下公式可以计算用户u对一个物品 j 的兴趣:

(0)
这里N(u)是用户喜欢的物品的集合,S(j, k)是物品j最相似的K个物品的集合,rui是用户u对物品i的兴趣程度。
Jaccard公式
这是一个在《推荐系统实践》中看到的公式,这里我们研究两个用户users的兴趣相似度:给定用户u和用户v,令N(u),N(v)分别表示用户u,v曾经有过正反馈的物品集合。那么用户u和v的相似度为:
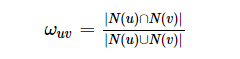
(1)
上述公式简单表述就是:

it’s the ratio of the size of the intersection to the size of the union of their preferred items
这是一个忽略了Preference value的相似度计算方式。
使用这个度量方法通常有两种情况:
-
Data中只有boolean值,并没有rating值;
-
你认为数据的噪声不是很大。
cosine公式
与上述公式相同,只是在分母中加了个根号,这里我们研究物品items的相似度:
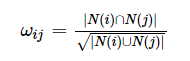
(2)
这里N(i)和N(j)分别表示喜欢物品i 和物品j 的人数。
到这里为止,我们研究的对象忽略的rating的具体分数,如果对象换做是评分,如电影评分(分数ratings有:1,2,3,4,5),那么相应的cosine公式变换为:
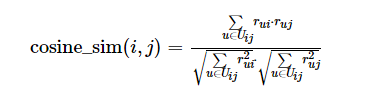
(3)
其中rui和ruj分别表示用户 u 对物品 i 和 j 的评分,Uij代表同时喜欢物品 i 和 j 的用户集合。
以下为surprise库的cosine函数源码和分析:
def cosine(n_x, yr, min_support):
### 此处省略了一些东西
for y, y_ratings in iteritems(yr):
### xi和xj分别表示物品i和j
### 以下为生成(3)式中的分母和分子
for xi, ri in y_ratings:
for xj, rj in y_ratings:
freq[xi, xj] += 1
prods[xi, xj] += ri * rj
sqi[xi, xj] += ri**2
sqj[xi, xj] += rj**2
### 以下为使用(3)式进行计算
for xi in range(n_x):
sim[xi, xi] = 1
for xj in range(xi + 1, n_x):
if freq[xi, xj] < min_sprt:
sim[xi, xj] = 0
else:
denum = np.sqrt(sqi[xi, xj] * sqj[xi, xj])
sim[xi, xj] = prods[xi, xj] / denum
sim[xj, xi] = sim[xi, xj]
return sim
### 返回的结果sim是一个对称矩阵,行列的index表示对应每个物品item,矩阵元素表示行列对应物品的相似度
Pearson Correlation(PC)
如果在(3)式的基础上进行去均值的话,那么就得到了(4)式:
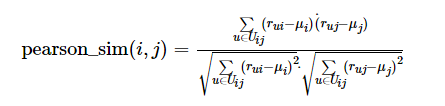
(4)
注意一点,这里的均值计算只考虑到同时喜欢物品i和j的用户集合Uij,对于其他不涉及物品i和j的用户,不要加到均值计算的过程中。
通常来说,不同用户?评分标准的差别要比不同物品评分标准差别要高很多(The differences in the rating scales of individual users are often more pronounced than the differences in ratings given to individual items),因为不同人的评分标准不一样,对于某人来说,他评分的所有物品分数都偏低。但是对于一个物品来说,不同物品之间所依据的评分标准都是大众评价的结果,这是一个被不同标准泛化了的标准。
所以,当我们计算物品相似度pearson_sim(i,j)时,减去的均值应该针对于用户,而不是物品。所以,PC可以优化为AC(Adjusted):
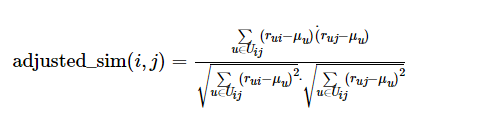
(5)
均方差(MSD)
仍然考虑物品i和j的相似度,MSD考虑的角度为同时喜欢物品i和j的用户对于这两个物品的评分差距程度:
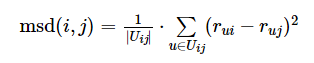
(6)
(6)式表示均方差,值越小,物品i和j相似度越大。为了与之前的相似度表示一致(值越大,物品相似度越大),定义相似度为:
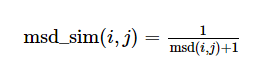
(7)
一些考虑
对于推荐系统来说,考虑到用户的数量,评分数据是相当稀疏的。上述方法得到的所有相似度权重通常只使用了很小一部分的评分。举个例子,假设两部很小众的电影正好同时只被两个人喜欢,运用上面的方法,我们得到这两部影片相似度很高。然而实际情况可能并不是这样,这可能我们取的样本太少的缘故。所以,有这样一个思想很重要,即:当计算只用到很小范围的评分时,减小这个计算的相似度的权重
Reduce the magnitude of a similarity weight when this weight is computed using only a few ratings
我们可以给计算出来的相似度一个惩罚(penalized),所用的评分集合Uij越小,惩罚越大:
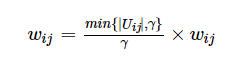
(8)
当评分的用户集合大到一定程度时,惩罚消失。
活跃度跟高的用户通常会评分很多物品,覆盖范围也更广,也就是方差(var)越大,他们的评分多,但是贡献度却要少。
为什么呢?假如一个人非常爱购物,在淘宝上疯狂买各种各样的东西,那么他的一个购买跟物品种类的相关性就很低。同样的,对于物品来说,如电影《教父》,被很多人喜欢,那么根据它也很难找到与他相似的电影。简单来说:活跃用户对物品相似度的贡献应该小于不活跃用户。
那么,我们引入一个参数:
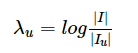
(9)
这个参数λu定义为用户u的活跃程度的倒数,I为所有物品,Iu为用户u有操作的物品,两者之商越大,代表活跃程度越低,即权重越高。
将该参数运用到Pearson中,即:
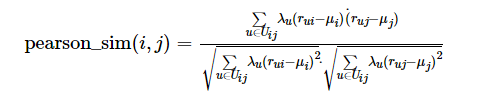
(10)
一般化,我们可以把Pearson-baseline correlation定义如下:
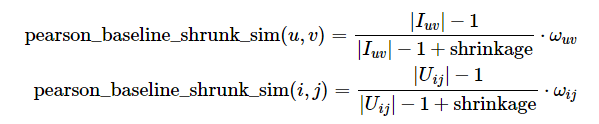
(11)
这也是surprise库中pearson_baseline()的计算方法。
性能比较
下面使用surprise库对上面介绍的几种相似度度量进行比较:
import pandas as pd
import numpy as np
from surprise.prediction_algorithms.knns import KNNBasic
from surprise import Dataset, Reader
from surprise.model_selection import train_test_split
1、读取数据,预处理
为了方便,这里只使用ml-latest_small的movielens数据集进行操作
reader = Reader(rating_scale=(1, 5), line_format='user item rating timestamp')
df_data = pd.read_csv('./data/ml-latest-small/ratings.csv', usecols=['userId','movieId','rating'])
data = Dataset.load_from_df(df_data, reader)
trainset, testset = train_test_split(data, test_size=0.2)
2、建立模型
建立KNN基于邻域的模型,其预测函数为(0)式的一个优化,即:
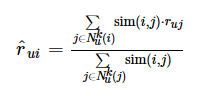
(11)
我们分别使用cosine, msd, pearson以及pearson-baseline作为相似度度量进行比较,分别得到其precision和recall(这里使用Top5作为metric)
注:precision_recall_at_k()函数见
这里
sim = ['cosine', 'msd', 'pearson','pearson_baseline']
for s in sim:
params = {'name': s, 'user_based': False}
knn = KNNBasic(k=40, min_k=1, sim_options=params)
knn.fit(trainset)
predictions = knn.test(testset)
precisions, recalls = precision_recall_at_k(predictions, k=5, threshold=3.5)
print('Precision:', sum(prec for prec in precisions.values()) / len(precisions))
print('Recall:', sum(rec for rec in recalls.values()) / len(recalls))
print('')
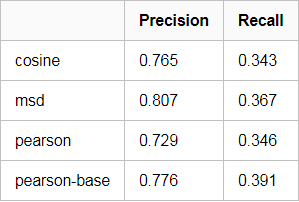
由于数据量很小,上述的评测指数仅作参考