word2vec是Google在2013年提出的一款开源工具,其是一个Deep Learning(深度学习)模型(实际上该模型层次较浅,严格上还不能算是深层模型,如果word2vec上层再套一层与具体应用相关的输出层,如Softmax,便更像是一个深层模型),它将词表征成实数值向量,采用CBOW(Continuous Bag-Of-Words Model,连续词袋模型)和Skip-Gram(Continuous Skip-GramModel)两种模型。具体原理,网上有很多。
本文是在windows下使用word2vec求词向量(linux环境下,网上有很多,就不再累赘)
1. 因为word2vec需要linux环境,所有首先在windows下安装linux环境模拟器,推荐cygwin(下载地址:http://www.cygwin.com/install.html),在安装时注意:因为默认安装下没有安装make命令工具(后面要用到),所以在安装时,选择package时,需要选择Devel与Utils模块,如下图所示:

2. 下载word2vec,下载地址为:http://word2vec.googlecode.com/svn/trunk/
将下载的所有文件放入word2vec文件夹下。
补充:
word2vec的原版代码是google code上的,也有改写的其他两个版本:
(1) c++11版本:(jdeng/word2vec) 下载地址: https://github.com/jdeng/word2vec
该代码可以在windows下编译运行,但需要编译器支持c++11; 已使用VS2013编译通过并运行:运行vs2013命令提示符,cd进入代码目录,输入cl main.cc,然后编译即可;训练命令直接是main,测试命令是“main test”。 运行和测试同样需要text8、questions-words.txt文件。 该版本输出的model文件为文本格式。
(2) java版本:下载地址:https://github.com/NLPchina/Word2VEC_java
经测试,OK。 也可以使用该java代码加载上述c++11版本的model,但需要自行添加load的代码。
3. 下载训练数据
下面提供一些网上能下载到的中文的好语料,供研究人员学习使用。
(1).中科院自动化所的中英文新闻语料库 http://www.datatang.com/data/13484
中文新闻分类语料库从凤凰、新浪、网易、腾讯等版面搜集。英语新闻分类语料库为Reuters-21578的ModApte版本。
(2).搜狗的中文新闻语料库 http://www.sogou.com/labs/dl/c.html
包括搜狐的大量新闻语料与对应的分类信息。有不同大小的版本可以下载。
(3).李荣陆老师的中文语料库 http://www.datatang.com/data/11968
压缩后有240M大小
(4).谭松波老师的中文文本分类语料 http://www.datatang.com/data/11970
不仅包含大的分类,例如经济、运动等等,每个大类下面还包含具体的小类,例如运动包含篮球、足球等等。能够作为层次分类的语料库,非常实用。这个网址免积分(谭松波老师的主页):http://www.searchforum.org.cn/tansongbo/corpus1.php
(5).网易分类文本数据 http://www.datatang.com/data/11965
包含运动、汽车等六大类的4000条文本数据。
(6).中文文本分类语料 http://www.datatang.com/data/11963
包含Arts、Literature等类别的语料文本。
(7).更全的搜狗文本分类语料 http://www.sogou.com/labs/dl/c.html
搜狗实验室发布的文本分类语料,有不同大小的数据版本供免费下载
(8).2002年中文网页分类训练集 http://www.datatang.com/data/15021
2002年秋天北京大学网络与分布式实验室天网小组通过动员不同专业的几十个学生,人工选取形成了一个全新的基于层次模型的大规模中文网页样本集。它包括11678个训练网页实例和3630个测试网页实例,分布在11个大类别中。
4. 将预料库进行分词并去掉停用词,可以使用的分词工具有:
StandardAnalyzer(中英文)、ChineseAnalyzer(中文)、CJKAnalyzer(中英文)、IKAnalyzer(中英文,兼容韩文,日文)、paoding(中文)、MMAnalyzer(中英文)、MMSeg4j(中英文)、imdict(中英文)、NLTK(中英文)、Jieba(中英文),这几种分词工具的区别,可以参加:http://blog.csdn.net/wauwa/article/details/7865526。本文使用Jieba分词工具。
5. 分词之后,所有的词以空格键或tab或,隔开写入一个文件中,如all_words中,并将该文件拷贝到word2vec目录中。
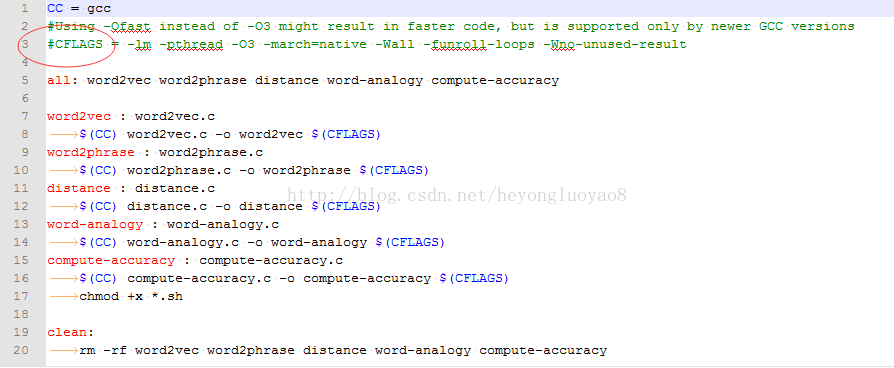
6. 启动cygwin,使用cd命令进入word2vec文件夹下,输入make命令,报如下错误
gcc word2vec.c -o word2vec -lm -pthread -O3 -march=native -Wall -funroll-loops -Wno-unused-result
gcc: 错误:unrecognized command line option ‘-pthread’
makefile:8: recipe for target ‘word2vec’ failed
make: *** [word2vec] Error 1
说明cygwin中的gcc不支持pthread多线程命令,解决方法是将word2vec目录下的makefile文件:
CFLAGS = -lm -pthread -O3 -march=native -Wall -funroll-loops -Wno-unused-result
这一行注释掉。
7. 将你自己的数据(可以打包成压缩文件),放入word2vec目录下,修改demo-word.sh文件,该文件默认情况下使用自带的text8数据进行训练,如果训练数据不存在,则会进行下载,因为需要使用自己的数据进行训练,所以可以将
if [ ! -e text8.zip ]; then
wget http://mattmahoney.net/dc/text8.zip -O text8.gz
gzip -d text8.gz -f
fi
进行注释,并将
time ./word2vec -train text8 -output vectors.bin -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 0 -iter 15
./distance vectors.bin

中的text8更改成自己的训练数据名称all_words,如果你的数据有后缀,记得带后缀。
参数解释:
-train 训练数据
-output 结果输入文件,即每个词的向量
-cbow 是否使用cbow模型,0表示使用skip-gram模型,1表示使用cbow模型,默认情况下是skip-gram模型,cbow模型快一些,skip-gram模型效果好一些
-size 表示输出的词向量维数
-window 为训练的窗口大小,8表示每个词考虑前8个词与后8个词(实际代码中还有一个随机选窗口的过程,窗口大小<=5)
-negative 表示是否使用NEG方,0表示不使用,其它的值目前还不是很清楚
-hs 是否使用HS方法,0表示不使用,1表示使用
-sample 表示 采样的阈值,如果一个词在训练样本中出现的频率越大,那么就越会被采样
-binary 表示输出的结果文件是否采用二进制存储,0表示不使用(即普通的文本存储,可以打开查看),1表示使用,即vectors.bin的存储类型
————————————-
除了上面所讲的参数,还有:
-alpha 表示 学习速率
-min-count 表示设置最低频率,默认为5,如果一个词语在文档中出现的次数小于该阈值,那么该词就会被舍弃
-classes 表示词聚类簇的个数,从相关源码中可以得出该聚类是采用k-means
8. 运行命令sh demo-word.sh,等待训练完成,如下图:

9. 模型训练完成之后,得到了vectors.bin这个词向量文件,文件的存储类型由binary参数觉得,如果为0,便可以直接用编辑器打开,进行查看,向量维度由size参数决定。于是我们可以使用这个向量文件进一步进行自然语言处理了。比如求相似词,关键词聚类与分类等。其中word2vec中提供了distance求词的cosine相似度,并排序。也可以在训练时,设置-classes参数来指定聚类的簇个数,使用kmeans进行聚类。还可以继续别的操作,可以参见http://blog.csdn.net/zhaoxinfan/article/details/11640573。
