AVOD(Aggregate View Object Detection)和MV3D类似,是一种融合3维点云和相机RGB图像的三维目标检测算法. 不同的是: MV3D中融合了相机RGB图像,点云BEV映射和FrontView映射,而AVOD则只融合相机RGB图像和点云BEV映射.
从网络结果来看,AVOD采用了基于两阶的检测网络,这让我们很容易想到同样是两阶检测网络结果的Faster RCNN物体检测网络. 一想到两阶,相信大家首先想到的就是检测精度高但检测速率慢,仅适用了是检测帧率要求不高且要求检测精度的场景.
下面是一张AVOD的网络结构图(图片来源于网络):
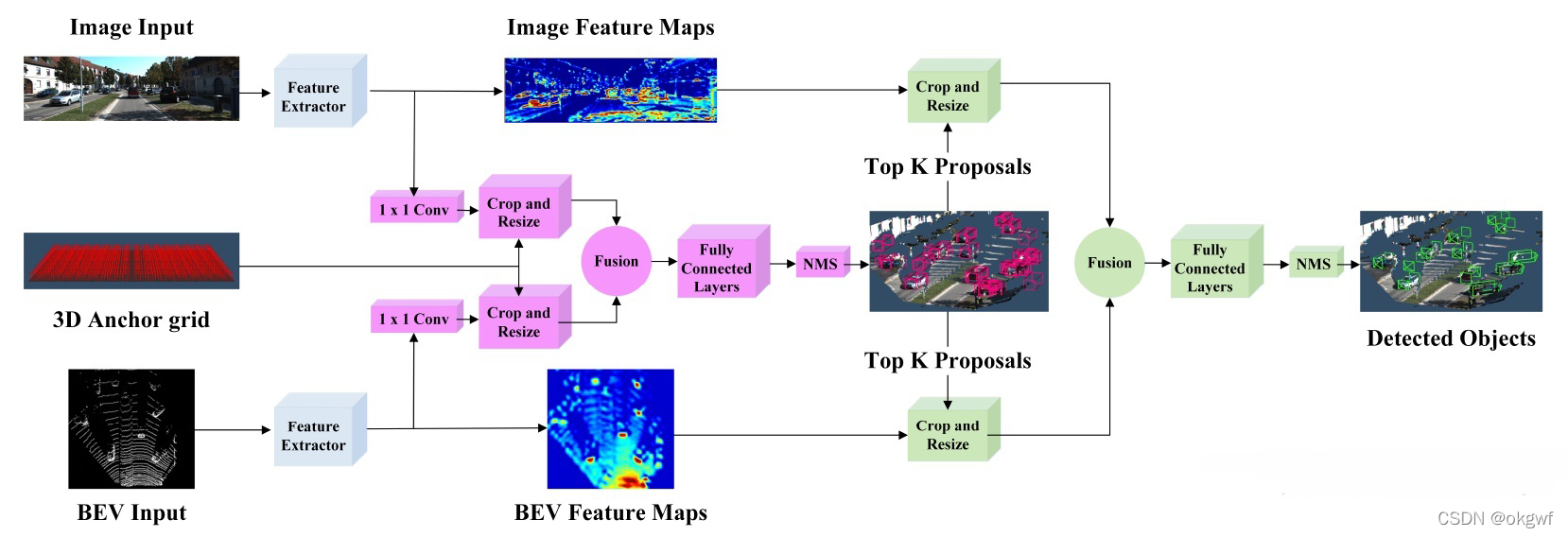
AOVD的两阶体现在两个方面: 目标框检测, 数据级和特征级两步融合. 基本过程如下
:
一.
AVOD对RGB图像和点云BEV分两路使用FPN网络(关于FPN的细节不再阐述)进行特征提取,获取两种输入的全分辨率特征映射: 图像特征映射和BEV特征映射(高度图和密度图).
二.
对于两种特征映射,为了对它们进行融合,需要调整到一致的尺寸, 分别对它们进行1×1卷积,进一步提取特征,然后调整同样尺寸后, 进行融合. 这是第一融合,相对于第二次融合,该次融合相当于数据级融合.
三.
经第一次融合后的特征,送入一个类似Faster RCNN的RPN网路,经全连接层和NMS后,经第一次分类和3DBBox回归后, 生成一些列区域建议框(候选框),
四.
生成的建议框分别和第一步生成的两路特征映射一起,经调整尺寸后,进行第二次融合(区域建议框融合).
五.
融合后的特征,经全连接层第二次分类和3DBBox回归运算后,经NMS后期处理,最终生成目标检测框.
点云鸟瞰图(BEV)的获取方式:
在AVOD中,算法采用两种方式来表达BEV数据: 高度图 和 密度图
-
高度图
: 从BEV视角区域,划分为一定尺寸的网格,比如: MxN. 在每一个网忘格里,在从高度方向将0-2.5高的垂直空间划分为K层,这样就把BEV视角的点云空间划分为M x N x K的立体格(Voxel), 同时找出每个立体格内的最大高度H_max。这样,有这M x N x K个H_max就构成了高度图。 -
密度图
: 基于上一步的M x N x K的立体格(Voxel), 计算每个立体格的点云点密度,计算公式为
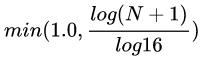
,由此M x N x K个密度值构成密度图。
创新性的3维边界框的向量表示形式:
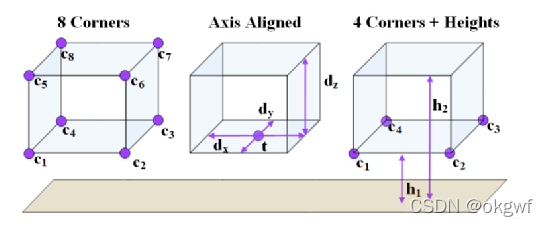
一般的做法是: 对于2维检测框,采用4×2(x,y)共8个值,或中心点+尺寸表示法: 1(长)+1(宽)+2(x,y)共4个值. 而对于3维检测框,采用8×3(x,y,z)共24个值.
AVOD创新性的采用了底面边框+上下面离地高度形式,即; 4×2(x,y) + 2x高的形式,共10个值. 详细见下图, 图中左侧为MV3D的24值表示法,右侧为AVOD的10值表示法: