清华中文分词工具thulac使用记录
1 安装
由于用到了分词,需要给已经处理成每行内容只含汉字的txt文本进行分词,所以想到用thulac试一下。环境是anaconda+pycharm+python 3.6.
使用pip安装:
pip install thulac
2 使用
pycharm中新建python文件,导入thulac包,然后输入命令:
import thulac
thu1 = thulac.thulac(seg_only=True) #只进行分词,不进行词性标注
thu1.cut_f("input.txt", "output.txt") #对input.txt文件内容进行分词,输出到output.txt
2.1 遇到的问题解决
执行上面命令时提示编码问题:

在查看文本文档确实都是UTF-8编码格式后,点击thulac包下的那个__init__文件,在提示的189行上面,188,187行看到文件读写没有指定编码格式,所以添加指定格式如下:
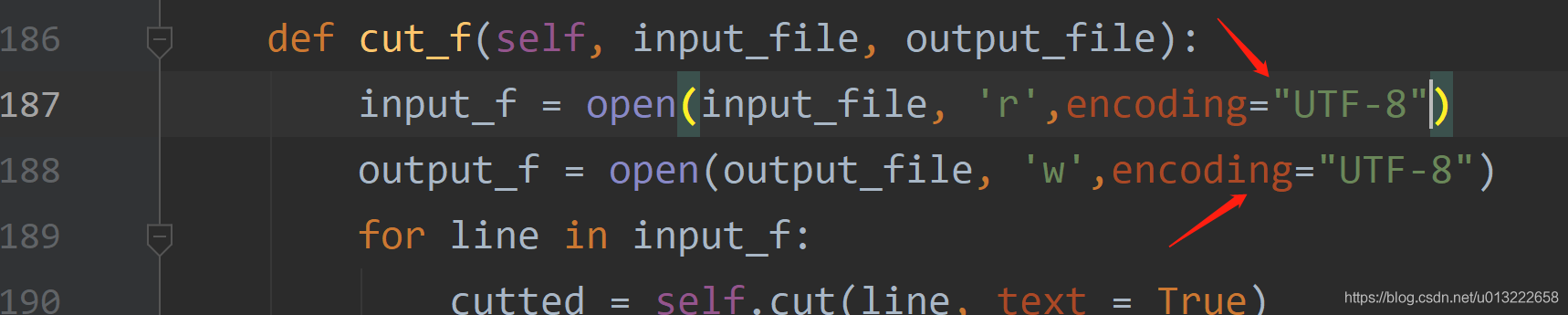
然后就能成功运行了。
2.2 使用分词和词性标注
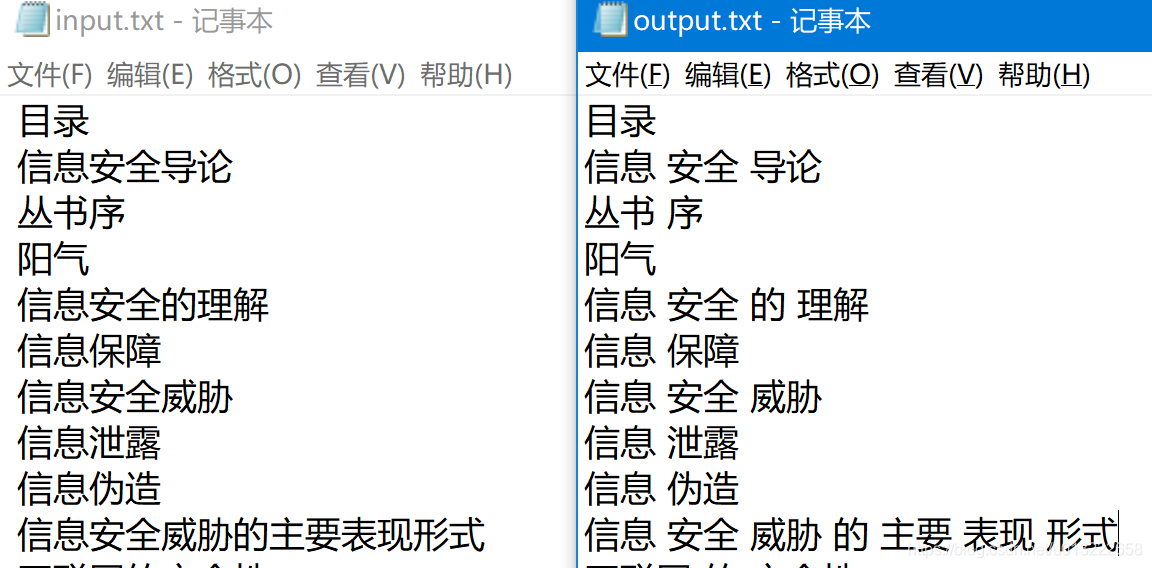
在同目录下生成output.txt文件,分词成功;
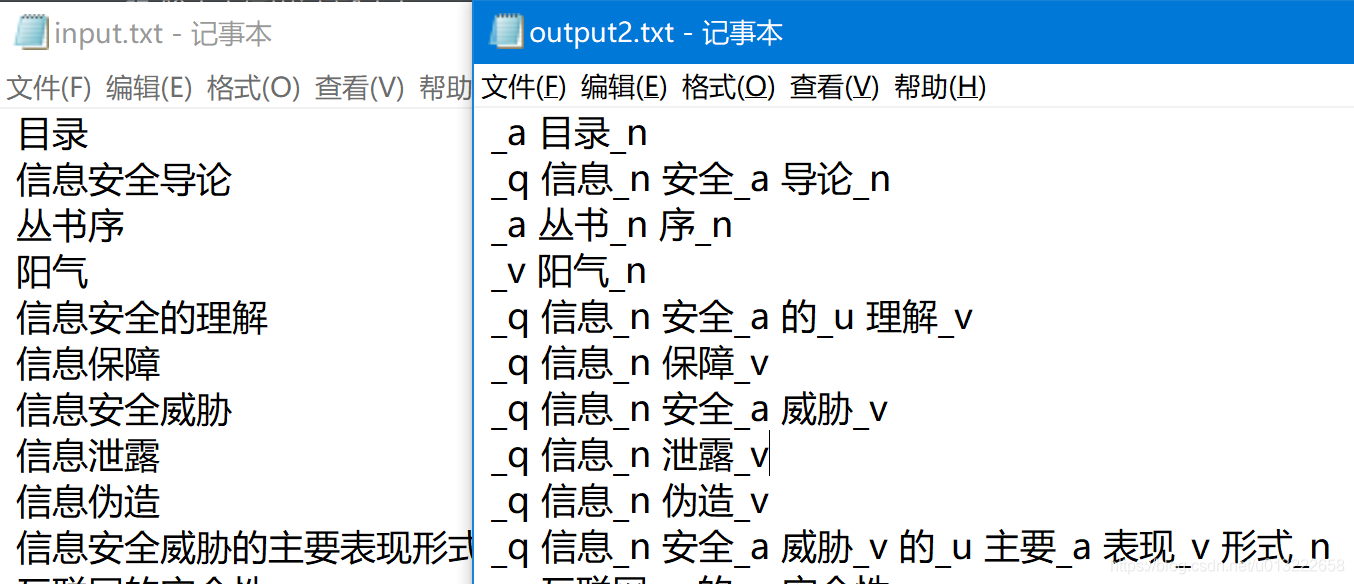
使用默认模式,词性标注加分词,再看下结果:
import thulac
thu1 = thulac.thulac() #默认模式,进行词性标注
thu1.cut_f("input.txt", "output2.txt") #对input.txt文件内容进行分词,输出到output.txt
这个会使用时间长,结果对比如下:
2.3 清除文本中的空行
"""
读取存在空行的文件,删除其中的空行,并将其保存到新的文件中
"""
with open('input.txt','r',encoding = 'utf-8') as fr,open('new.txt','w',encoding = 'utf-8') as fd:
for text in fr.readlines():
if text.split():#split()默认使用空格进行分割,中间无论多少空格都切掉。
fd.write(text)
print('输出成功....')
这样文本中所有的空行清除了。
3 thulac使用方式
3.1 使用示例
python版
代码示例1
import thulac
thu1 = thulac.thulac() #默认模式
text = thu1.cut(“我爱北京天安门”, text=True) #进行一句话分词
print(text)
代码示例2
thu1 = thulac.thulac(seg_only=True) #只进行分词,不进行词性标注
thu1.cut_f(“input.txt”, “output.txt”) #对input.txt文件内容进行分词,输出到output.txt
3.2 接口参数
-
thulac(user_dict=None, model_path=None, T2S=False, seg_only=False, filt=False, deli=’_’) 初始化程序,进行自定义设置
user_dict 设置用户词典,用户词典中的词会被打上uw标签。词典中每一个词一行,UTF8编码 T2S 默认False, 是否将句子从繁体转化为简体 seg_only 默认False, 时候只进行分词,不进行词性标注 filt 默认False, 是否使用过滤器去除一些没有意义的词语,例如“可以”。 model_path 设置模型文件所在文件夹,默认为models/ deli 默认为‘_’, 设置词与词性之间的分隔符 -
rm_space 默认为False, 是否去掉原文本中的空格后再进行分词
-
cut(文本, text=False) 对一句话进行分词
text 默认为False, 是否返回文本,不返回文本则返回一个二维数组([[word, tag]..]),seg_only模式下tag为空字符。 -
cut_f(输入文件, 输出文件) 对文件进行分词
-
run() 命令行交互式分词(屏幕输入、屏幕输出)
3.3 guihub 地址