上一节一起学习了几个解码器,用于解决TCP协议网络传输过程中粘包和拆包的问题,用过Netty的人总会说一句话“用Netty一定要了解一下它的底层原理,这样才敢用”,其实很有感悟,Netty in action 这本书中也有一个章节分析了codec,也定义了几个自定义的译码器,但是它自定义的几个译码器全部是继承与ByteToMessageDecoder的,我们上文中的几个解码器例如DelimiterBasedFrameDecoder,FixedLengthFrameDecoder,LineBasedFrameDecoder这几个全部继承于ByteToMessageDecoder
LineBasedFrameDecoder.java

FixedLengthFrameDecoder.java
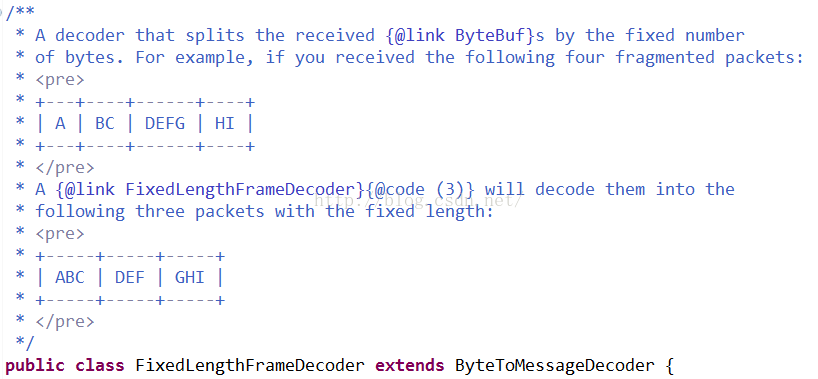
DelimiterBasedFrameDecoder.java
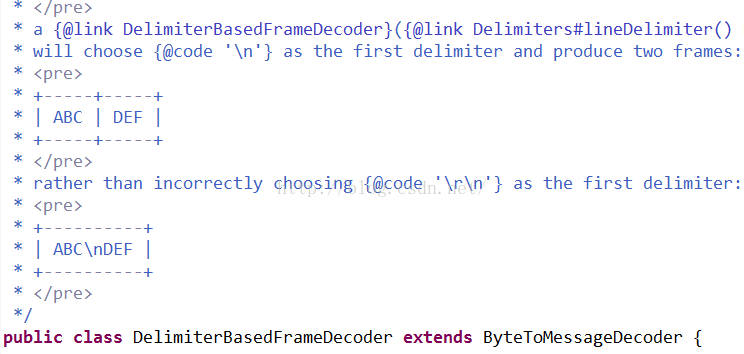
可以看出常用的一些解码器都是继承于ByteToMessageDecoder,说明了这个decoder的重要性
今天我们就分析一下ByteToMessageDecoder这个类,我们并不是分析源码,至少现在还不是分析源码的时候,我个人觉得框架技术啥的,至少先会用,会用之后看源码事半功倍
首先,我们先看下ByteToMessageDecoder的完整声明:

简单的分析一下:
1)继承了我们使用频率最高的ChannelInboundHandlerAdapter,的确,它必须是一个handler,这样才可以被添加到channelPipeline中处理信息流,既然继承与ChannelInboundHandlerAdapter,我们要看的就是channelRead这个方法
2)这是一个抽象类,抽象类和接口的区别就是它应该有抽象方法没有实现,如下:
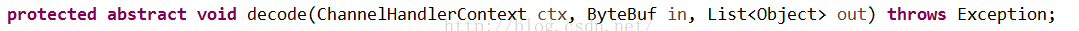
这个decode方法就是一个抽象方法,也就是DelimiterBasedFrameDecoder,FixedLengthFrameDecoder这些子类,具体的实现类需要实现了
简单的看下,我们就知道我们主要看的是就是这两个方法了
首先我们先看channelRead方法:
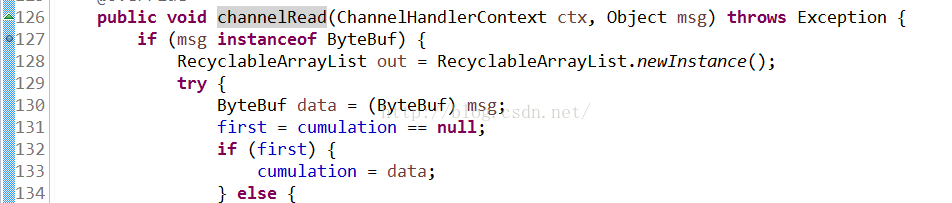
这是channelRead的源代码,我们可以看出,代码一开始就判断msg是不是ByteBuf,也就是为什么我们一般把解码器放在Channelhandler链的第一个的原因了,这样做的好处就是msg一般就是ByteBuf,不会被其他的业务逻辑影响,至少这时msg的很“纯洁”的。而且这个msg极有可能是directByteBuf,也就是说这是堆外内存的,因为我们ByteBuf在传输的时候堆外内存传输的时候可以少一次复制,之前的章节提及过
然后如果是第一次接收的情况下,直接接data放入到cumulation中,这个cumulation是一个全局变量:

这样做的好处就是cumulation相当于一个容器,在上层代码多次调用channelRead的时候,也就是当发送端的信息可能被接收端分多次接收的时候,这个容器存储信息
解析来我们接着看:
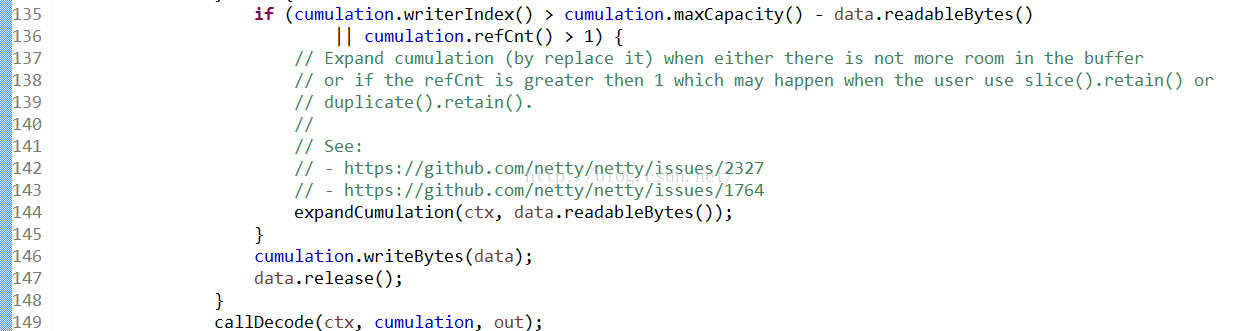
第135行主要判断cumulation的可写下标+当前的读取的data的可读容量之和是不是大于cumulation的最大容量,这样做的就是防止cumulation的ByteBuf容量溢出,如果大于了,则说明cumulation需要扩容了

扩容的代码如图展示,需要注意的就是需要将老的oldCumulation释放掉
扩容之后,代码146行将新添加的data加入到cumulation中,147行再释放data所占用的内存空间,在149行就开始进行decode了,这个callDecode方法其实是对入参out进行了编辑

之所以out中的值是多个,是因为calldecode方法内部有一个循环,输入的类型是ByteBuf的in变量,只要它的isReadable方法返回true,说明该ByteBuf中还有可读的byte,可以按照用户自定的decode方法去切分分割,将按照用户方法切割的信息放入入参out中就可以了
我们刚刚也说明了,decode是一个抽象方法,需要每一个具体的类去实现,给出具体的分割转化的业务逻辑
接下来我觉得也是最最值得我学习的,就是finally这段代码:
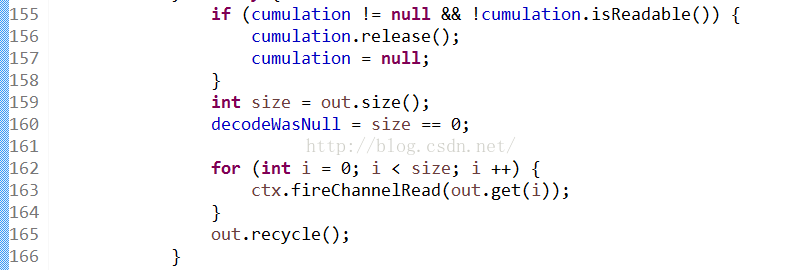
不是代码写的多么精辟,只是我从来没有在finally里面写过业务代码,最多关关资源之类的动作在里面写过,也就是说即使后面的数据处理发生异常或者怎么怎样,只要out这个list中有值,则会调用后续的fireChannelRead的方法
没有去对ByteToMessageDecoder这个方法进行深入的解析,只是了解它的基本原理~