我用C、C++和Java语言重写了一遍,
代码更加简洁,没有明显的bug
。完整代码已放到我的博客小程序 互联网实用指南 欢迎查看。
你可复制小程序链到文件传输助手然后直接点击就能直达 :
#小程序://互联网实用指南/Q9kSMpvBRex304C
你也可以扫描下方的小程序码,在首页搜索文章 文学研究助手,也可进入文章并获取完整代码。

目录
文学研究助手【C语言实现】->数据结构实验
数据结构实验:文学研究助手【C语言实现】
实验内容
文学研究人员需要统计某篇英语小说中某些特定单词的出现次数和位置。设计一个实现此目标的文字统计系统。
英文小说存放于一文本文件中,待统计的词汇集合要一次输入完毕,程序的输出结果是每个词的出现次数和出现位置所在行的行号,格式自行设计。
实验要求
约定小说的词汇一律不跨行。这样,每读入一行,就统计每个词在这行中的出现次数。
出现位置所在行的行号可以用链表存储。若某行中出现了不只一次,不必存多个相同的行号
测试数据
以自己的 C 源程序模拟英文小说,C 语言的保留字作为待统计的词汇集。
关键代码
文件读取与输出函数
char *FileRead(char ch[]) {
FILE *fp;
char *c = (char *)malloc(20000*sizeof(char));
char str[20000];
if( (fp=fopen(ch,"rt")) == NULL ) {
puts("文件打开失败或文件路径错误!!!");
exit(0);
}
/*拷贝文件中的字符串到数组str,并打印str*/
while(fgets(str, 20000, fp) != NULL) {
printf("%s", str);
}
fclose(fp);
return c;
}
统计文本文件中给定单词的数量
/*统计文本文件中给定单词的数量*/
int count(char * word) {
FILE * fp;
char ch,w[20];
int j = 0,num = 0;
//打开文件
if((fp = fopen(file_path,"r")) == NULL) {
printf("无法打开文件或文件路径错误!!!\n");
return 0;
}
//只要文件不结束,就一直判断
while(!feof(fp)) {
//取文件中的每个单词
ch = fgetc(fp);
j = 0;
//只要不是空格或转行或() {} [] , ; 等,其所遇到的字母都隶属于一个单词
while(ch != ' ' && ch != '\n' &&ch != '(' && ch !=')' &&ch != '{' && ch !='}' &&ch != '[' && ch !=']' && ch !=',' && ch != ';'&& !feof(fp)) { //ch != '(' && ch !=')' &&ch != '{' && ch !='}' &&ch != '[' && ch !=']' &&ch != '"' && ch !='\''
w[j++] = ch;
ch = fgetc(fp);
}
//给单词的最后添加结束符,防止各个单词的长度不同,导致从数组读取单词时多读的现象发生
w[j] = '\0';
//判断每个单词是否与给定单词相同,若相同,则计数变量num +1
if(strcmp(w,word) == 0) {
num++;
}
}
//最终返回计数变量 num 的值
return num;
}
检索并输出给定单词所在行号、在该行中出现的次数以及各自的具体位置
/*检索并输出给定单词所在行号、在该行中出现的次数以及各自的具体位置*/
void search(char * word) {
FILE * fp;
char ch,w[20];
int j = 0,num = 0,row = 1,col[200],i = 0,k;
//尝试打开文本文件
if((fp = fopen(file_path,"r")) == NULL) {
printf("cannot open file\n");
return;
}
//遍历文本文件中的每个单词
while(!feof(fp)) {
ch = fgetc(fp);
j = 0, i++;
while(ch != ' ' && ch != '\n' &&ch != '(' && ch !=')' &&ch != '{' && ch !='}' &&ch != '[' && ch !=']' && ch !=',' && ch != ';'&& !feof(fp)) {
w[j++] = ch;
ch = fgetc(fp);
i++;
}
w[j]='\0';
//判断每个单词与给定单词是否相等
if(strcmp(w,word) == 0) {
//如果相同,记录该单词在该行中的位置,同时计数变量 num+1
col[num] = i-j,
num++;
}
//如果遇到转行或者文件结束,则输出该行中单词的数量以及相应位置
if(ch == '\n' || feof(fp)) {
if(num) {
printf("第%d行出现了%d次,位置分别是:[ ",row,num);
for(k = 0 ; k < num; k++) {
printf(" %d",col[k]);
if (k != num-1) printf(",");
}
printf("]\n");
}
//转行,row +1,同时 i 和 num 都清零
row ++;
i = 0;
num = 0;
}
}
}
备注
备注:运行程序之前,我已经提前将2个txt文本文件放入D盘根目录。也可以放入其他目录,但是请注意文件路径为全英文路径,不能有中文等奇怪的,要不然会报一些无法预料的错误。
其中,我在c.txt中事先放入源代码(尽量不要出现中文注释),用于读入统计,当然你也可以拷贝一篇英语文章到c.txt。
我在d.txt里放了C语言的保留字用于统计这些保留字在源文件中出现的次数。每个保留字独占一行。如图

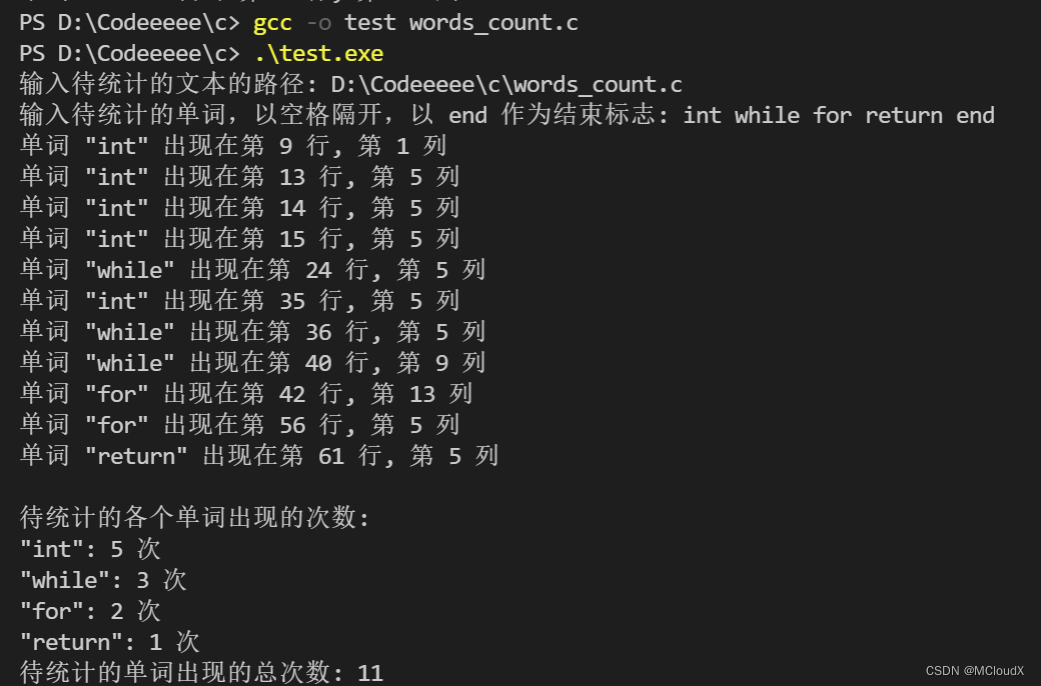
运行结果

其他补充说明
- 对于待统计的词汇集,可以让用户通过键盘输入多个待统计的词汇集,也可以读取待统计的词汇集单词来获取保留字并一一进行统计和位置查找。
- FileRead 函数设计时将文本文件中的字符串读入字符数组时,字符数组长度应尽量大一些。打印输出字符数组即源文件内容。
- count 函数中,取文件中的每个单词,除了考虑单词前的空格符换行符外,还应考虑单词前可能出现的逗号和(括号等等符号。 通过库函数 strcmp()来判断每个单词是否与给定单词相同,若相同,则计数变量 num +1
- search 函数遍历文本文件中的每个单词时,记录与给定单词相同的单词的所在行和列.
- 代码似乎挺low的,还请各位指教。
文学研究助手C语言源代码【完整可编译】
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//存储文件路径的数组
char file_path[20]; //源文本路径
char file_path_2[20]; //待统计词汇集文本路径
/*文件读取与输出函数*/
char *FileRead(char ch[]) {
FILE *fp;
char *c = (char *)malloc(20000*sizeof(char));
char str[20000];
if( (fp=fopen(ch,"rt")) == NULL ) {
puts("文件打开失败或文件路径错误!!!");
exit(0);
}
/*拷贝文件中的字符串到数组str,并打印str*/
while(fgets(str, 20000, fp) != NULL) {
printf("%s", str);
}
fclose(fp);
return c;
}
/*统计文本文件中给定单词的数量*/
int count(char * word) {
FILE * fp;
char ch,w[20];
int j = 0,num = 0;
//打开文件
if((fp = fopen(file_path,"r")) == NULL) {
printf("无法打开文件或文件路径错误!!!\n");
return 0;
}
//只要文件不结束,就一直判断
while(!feof(fp)) {
//取文件中的每个单词
ch = fgetc(fp);
j = 0;
//只要不是空格或转行或() {} [] , ; 等,其所遇到的字母都隶属于一个单词
while(ch != ' ' && ch != '\n' &&ch != '(' && ch !=')' &&ch != '{' && ch !='}' &&ch != '[' && ch !=']' && ch !=',' && ch != ';'&& !feof(fp)) { //ch != '(' && ch !=')' &&ch != '{' && ch !='}' &&ch != '[' && ch !=']' &&ch != '"' && ch !='\''
w[j++] = ch;
ch = fgetc(fp);
}
//给单词的最后添加结束符,防止各个单词的长度不同,导致从数组读取单词时多读的现象发生
w[j] = '\0';
//判断每个单词是否与给定单词相同,若相同,则计数变量num +1
if(strcmp(w,word) == 0) {
num++;
}
}
//最终返回计数变量 num 的值
return num;
}
/*检索并输出给定单词所在行号、在该行中出现的次数以及各自的具体位置*/
void search(char * word) {
FILE * fp;
char ch,w[20];
int j = 0,num = 0,row = 1,col[200],i = 0,k;
//尝试打开文本文件
if((fp = fopen(file_path,"r")) == NULL) {
printf("cannot open file\n");
return;
}
//遍历文本文件中的每个单词
while(!feof(fp)) {
ch = fgetc(fp);
j = 0, i++;
while(ch != ' ' && ch != '\n' &&ch != '(' && ch !=')' &&ch != '{' && ch !='}' &&ch != '[' && ch !=']' && ch !=',' && ch != ';'&& !feof(fp)) {
w[j++] = ch;
ch = fgetc(fp);
i++;
}
w[j]='\0';
//判断每个单词与给定单词是否相等
if(strcmp(w,word) == 0) {
//如果相同,记录该单词在该行中的位置,同时计数变量 num+1
col[num] = i-j,
num++;
}
//如果遇到转行或者文件结束,则输出该行中单词的数量以及相应位置
if(ch == '\n' || feof(fp)) {
if(num) {
printf("第%d行出现了%d次,位置分别是:[ ",row,num);
for(k = 0 ; k < num; k++) {
printf(" %d",col[k]);
if (k != num-1) printf(",");
}
printf("]\n");
}
//转行,row +1,同时 i 和 num 都清零
row ++;
i = 0;
num = 0;
}
}
}
/*显示菜单函数*/
void showMenu() {
printf("\t\t******************* 文 学 研 究 助 手 *******************\n");
printf("\t\t*\t0.安全退出程序\t\t\t\t\t*\n");
printf("\t\t*\t1.原文本文件(英文小说或源代码文件)读入并输出\t*\n");
printf("\t\t*\t2.输入待统计的词汇集\t\t\t\t*\n");
printf("\t\t*\t3.导入待统计的词汇集\t\t\t\t*\n");
printf("\t\t*********************************************************\n");
printf("\t\t————————4202465_刘磊_数据结构实验三———————\n");
}
int main () {
char *ch,*ch_2;
int choice =-1,N;
char index[300] = {0};
showMenu();
while (choice != 0) {
printf("\n请输入你的选择(0 或 1 或 2 或 3):");
fflush(stdin);
scanf("%d",&choice);
switch (choice) {
case 0:
printf("\n已安全退出文学研究助手\n");
exit(0);
break;
case 1:
printf("请输入要读入的小说(或源代码文件)的文本的路径:");
scanf("%s",file_path);
printf("源文件内容为:\n");
ch = FileRead(file_path);
break;
case 2:
printf("请输入待统计的词汇集:\n");
scanf("%s",index);
printf("\n【%s】在源文件中总共出现了%d次\n",index,count(index));
//检索 index单词 在文本中的相对位置
search(index);
break;
case 3:
printf("请输入需要导入的待统计的词汇集的文本的路径:");
scanf("%s",file_path_2);
FILE *fp_2=fopen(file_path_2,"r");
while(fgets(index, 300, fp_2) != NULL) {
int i=strlen(index);
if(index[i-1]=='\n') { //因为最后一行没有回车符
index[i-1]='\0';
}
N = count(index);
if (N != 0) printf("\n————————————————————————————————\n");
printf("【%s】出现了%d次",index,N);
if (N != 0) printf(":\n");
else printf(",");
//检索 index单词 在文本中的相对位置
search(index);
}
break;
default:
printf("请输入有效选择!\n");
break;
}
}
system("pause");
return 0;
}
上述代码有个较大的问题,另一个用了goto语句的,有点小问题,影响不大。【尽量用纯C编译器】
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//存储文件路径的数组
char file_path[20]; //源文本路径
char file_path_2[20]; //待统计词汇集文本路径
/*文件读取与输出函数*/
char *FileRead(char ch[]) {
FILE *fp;
char *c = (char *)malloc(20000*sizeof(char));
char str[20000];
if( (fp=fopen(ch,"rt")) == NULL ) {
puts("文件打开失败或文件路径错误!!!");
exit(0);
}
/*拷贝文件中的字符串到数组str,并打印str*/
while(fgets(str, 20000, fp) != NULL) {
printf("%s", str);
}
fclose(fp);
return c;
}
/*统计文本文件中给定单词的数量*/
int count(char * word) {
FILE * fp;
char ch,w[20];
int j = 0,num = 0;
//打开文件
if((fp = fopen(file_path,"r")) == NULL) {
printf("无法打开文件或文件路径错误!!!\n");
return 0;
}
//只要文件不结束,就一直判断
while(!feof(fp)) {
//取文件中的每个单词
ch = fgetc(fp);
j = 0;
//只要不是空格或转行或() {} [] , ; 等,其所遇到的字母都隶属于一个单词
while(ch != ' ' && ch != '\n' &&ch != '(' && ch !=')' &&ch != '{' && ch !='}' &&ch != '[' && ch !=']' && ch !=',' && ch != ';'&& !feof(fp)) { //ch != '(' && ch !=')' &&ch != '{' && ch !='}' &&ch != '[' && ch !=']' &&ch != '"' && ch !='\''
w[j++] = ch;
ch = fgetc(fp);
}
//给单词的最后添加结束符,防止各个单词的长度不同,导致从数组读取单词时多读的现象发生
w[j] = '\0';
//判断每个单词是否与给定单词相同,若相同,则计数变量num +1
if(strcmp(w,word) == 0) {
num++;
}
}
//最终返回计数变量 num 的值
return num;
}
/*检索并输出给定单词所在行号、在该行中出现的次数以及各自的具体位置*/
void search(char * word) {
FILE * fp;
char ch,w[20];
int j = 0,num = 0,row = 1,col[200],i = 0,k;
//尝试打开文本文件
if((fp = fopen(file_path,"r")) == NULL) {
printf("cannot open file\n");
return;
}
//遍历文本文件中的每个单词
while(!feof(fp)) {
ch = fgetc(fp);
j = 0, i++;
while(ch != ' ' && ch != '\n' &&ch != '(' && ch !=')' &&ch != '{' && ch !='}' &&ch != '[' && ch !=']' && ch !=',' && ch != ';'&& !feof(fp)) {
w[j++] = ch;
ch = fgetc(fp);
i++;
}
w[j]='\0';
//判断每个单词与给定单词是否相等
if(strcmp(w,word) == 0) {
//如果相同,记录该单词在该行中的位置,同时计数变量 num+1
col[num] = i-j,
num++;
}
//如果遇到转行或者文件结束,则输出该行中单词的数量以及相应位置
if(ch == '\n' || feof(fp)) {
if(num) {
printf("第%d行出现了%d次,位置分别是:[ ",row,num);
for(k = 0 ; k < num; k++) {
printf(" %d",col[k]);
if (k != num-1) printf(",");
}
printf("]\n");
}
//转行,row +1,同时 i 和 num 都清零
row ++;
i = 0;
num = 0;
}
}
}
/*显示菜单函数*/
void showMenu() {
printf("\t\t******************* 文 学 研 究 助 手 *******************\n");
printf("\t\t*\t0.安全退出程序\t\t\t\t\t*\n");
printf("\t\t*\t1.原文本文件(英文小说或源代码文件)读入并输出\t*\n");
printf("\t\t*\t2.输入待统计的词汇集\t\t\t\t*\n");
printf("\t\t*\t3.导入待统计的词汇集\t\t\t\t*\n");
printf("\t\t*********************************************************\n");
printf("\t\t————————4202465_刘磊_数据结构实验三———————\n");
}
int main () {
char *ch,*ch_2;
int choice =-1,N;
char index[300] = {0};
showMenu();
while (choice != 0) {
pos_1:
printf("\n请输入你的选择(0 或 1 或 2 或 3):");
scanf("%d",&choice);
switch (choice) {
case 0:
printf("\n已安全退出文学研究助手\n");
exit(0);
break;
case 1:
printf("请输入要读入的小说(或源代码文件)的文本的路径:");
scanf("%s",file_path);
printf("源文件内容为:\n");
ch = FileRead(file_path);
break;
case 2:
printf("请输入待统计的词汇集:\n");
scanf("%s",index);
printf("\n【%s】在源文件中总共出现了%d次\n",index,count(index));
//检索 index单词 在文本中的相对位置
search(index);
break;
case 3:
printf("请输入需要导入的待统计的词汇集的文本的路径:");
scanf("%s",file_path_2);
FILE *fp_2=fopen(file_path_2,"r");
while(fgets(index, 300, fp_2) != NULL) {
int i=strlen(index);
if(index[i-1]=='\n') { //因为最后一行没有回车符
index[i-1]='\0';
}
N = count(index);
if (N != 0) printf("\n————————————————————————————————\n");
printf("【%s】出现了%d次",index,N);
if (N != 0) printf(":\n");
else printf(",");
//检索 index单词 在文本中的相对位置
search(index);
}
break;
default:
printf("请输入有效选择!\n");
goto pos_1; //若默认情况输入了错误的choice,跳转到 pos_1继续执行
break;
}
}
system("pause");
return 0;
}