关于编码方式还不太了解的,请戳
这里
。
C#中
string是一个unicode字符串
char字符是unicode字符。
每个char字符都是占2个字节。
这里的unicode其实应该是ucs-2。
The .NET
Char and String types
are themselves Unicode
下面一个例子验证string是一个unicode字符串:
static void Main()
{
string u16s = "你好abc";
Console.WriteLine("original char value");
// string是char的数组
foreach (char c in u16s)
{
Console.Write(((int)c).ToString("X2") + "-");
}
Console.WriteLine();
// 每个char都是2个byte 2个字节
Encoding utf16 = Encoding.Unicode;
byte[] u16bytes = utf16.GetBytes(u16s);
Console.WriteLine("Encoding unicode");
foreach (byte c in u16bytes)
{
Console.Write(((int)c).ToString("X2") + " ");
}
Console.WriteLine();
}
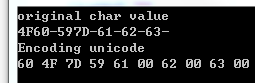
可以看到,对比C#中原始存为char的值 以及 把字符串直接转成unicode以后的码值 是一致的。
下面介绍2个函数:GetBytes 和 ToBase64String
目录
1.获取对应encode编码方式的字节码函数——encode.GetBytes
例子:获取 字符的码点 函数(字符对应unicode编码的字节码):
2.对字节码进行进行base64——System.Convert.ToBase64String
1.获取对应encode编码方式的字节码,接口函数为——
encode
.GetBytes
编码方式具体有:Unicode(
encode=
Encoding.Unicode),utf8(
encode=
Encoding.UTF8)等
下面两个例子都是用了unicode编码也相当于是utf16
Encoding.Unicode.
GetBytes(string)
第二个还用了utf8:
Encoding.UTF8.
GetBytes(string)
例子:获取 字符的码点 函数(字符对应unicode编码的字节码):
码点是特指Unicode码的码值。
使用的UTF16的编码来获取
某个字符
的码点。
private static string GetCodePoint(char ch)
{
string retVal = "u+";
byte[] bytes = Encoding.Unicode.GetBytes(ch.ToString());
// 因为Unicode指的是小端序的utf16,所以是颠倒顺序的,需要先读最后一个字节
for (int ctr = bytes.Length - 1; ctr >= 0; ctr--)
// 如果默认的ToString() 就是该字节的十进制值。这里加上参数X2 返回十六进制
retVal += bytes[ctr].ToString("X2");
return retVal;
}
public static void Main()
{
Console.WriteLine("{0,0:X2}", GetCodePoint('你'));
}可以看到 汉字“你” 的码点就是 U+4F60
![]()
例子:获取 字符串对应编码方式的字节码:
字节码:按具体的编码方式 字符与数字的对应关系,得到字符对应的数字,以字节为单位。
private static string GetEncodingBytes(string str, Encoding encode)
{
string retVal = "";
byte[] bytes = encode.GetBytes(str);
for (int ctr = 0; ctr < bytes.Length; ctr++)
{
retVal += bytes[ctr].ToString("X2");
}
return retVal;
}
public static void Main()
{
Console.WriteLine(GetEncodingBytes("你",Encoding.UTF8));
Console.WriteLine(GetEncodingBytes("你", Encoding.Unicode));
}
![]()
2.对字节码进行进行base64——System.Convert.ToBase64String
函数的输入是 字节码,输出是base64过的string。
对输入的字节码进行重新编码
有个base64编码表,可以理解成密码表了,具体怎么base64看下面:
例子:
下面这个例子先使用UTF8编码获取字节码
然后对字节码(byte[] 数组类型)进行base64函数:
public static string GetBase64Str(string src)
{
return System.Convert.ToBase64String(System.Text.Encoding.UTF8.GetBytes(src));
}
public static void Main()
{
Console.WriteLine(GetBase64Str("a"));
}
解释:
base64就是基于64
64是2的6次方=2^6
就是用6个bit对应一个字符
将原来的字节数组,依次取6个bit,6个bit进行编码成新的字符。
base64会确保经过base64以后的字符串设计为是4的倍数,也就是说会对于原始的字节数组不够长度的进行补齐。
对字节码进行base64的大概过程是:
1.
取字节数组的长度除以3
。看是否整除,整除就正好了。不整除进行第2步。
为什么除以3?
因为3个字节正好24bit
,可以编码成
4个6bit的
base64字符。
2.如果不整除
余1,那么
补齐4个bit的0后,将其转成
2个base64字符
以后,
再补2个“=”
;
如果不整除
余2,那么
补齐2个bit的0后,将其转成
3个base64字符
以后,
再补1个“=”
1)余1,即多出1个字节。1个字节8个bit,先补4个bit的0,相当于可以解析成2个6bit的base64字符,最后再加2个“=”。组成最后一组4个字符的base64字符串。
2)余2,即多出2个字节。2个字节16个bit,先补2个bit的0,相当于可以解析成3个6bit的base64字符,最后再加1个“=”。组成最后一组4个字符的base64字符串。
字符“a” 的
UTF8编码
是一个字节 0x61。
因为只有一个字节,要补2个=。
0x61 = 0110 0001,对这一个字节
进行6个bit的划分
,
011000 01
,
补4个0
。6个bit 一组,
对应base64编码表
,分别为Y(24)Q(16),最后补2个等号字符,所以最终输出为:
![]()
base64 返回的string的长度一定是4个倍数
介绍一种字符串加密方法:
先字符串转成字节码
对字节码进行base64
得到一个4的倍数的
base64字符串
再这个字符串再进行编码为字节码,对字节进行混淆顺序,
再对这个字节码解码为字符串。
字节码是默认有个编码方式的,同一个字符,选用不同的编码方式其字节码是不同的。本例子中均用utf8编码。
public static string GetEncryptionStr(string ext)
{
string extParams = GetBase64Str(ext);
byte[] byteArray = System.Text.Encoding.UTF8.GetBytes(extParams);
// MessOrderE function: Mess up the order of the array of bytes.
MessOrderE(byteArray, byteArray.Length);
extParams = System.Text.Encoding.UTF8.GetString(byteArray);
return extParams;
}
ps: 对于
数值类型,想要转成字节形式
使用的 BitConverter 类:
即把十进制转16进制显示(不是数字字符的ascii码)
public static string GetBytesInt32(Int32 num)
{
byte[] byte4 = BitConverter.GetBytes(num);
string str = BitConverter.ToString(byte4).Replace("-", "");
return str;
}
public static void Main()
{
Console.WriteLine(GetBytesInt32(1111111111));
}1111111111 的 16进制值为 423A35C7 ,而上述函数返回为如下:为小端序
![]()