Hadoop 的组成
- Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统
- Hadoop MapReduce:一个分布式的离线并行计算框架
- Hadoop Yarn:作业调度系统与集群管理框架
-
Hdoop Common:支持其他模块的工具模块。
下面我们首先来阐述环境搭建之后开始逐一的回顾上述模块的知识。
Hadoop 的环境搭建
- 将虚拟机的网络模式切换到NAT
- 克隆多台虚拟机
-
修改虚拟机静态ip
1、在终端命令窗口输入下面代码:
vim /etc/udev/rules.d/70-persistent-net.rules
2、进入如下页面操作如下图:

3、修改ip地址:命令为:
vim /etc/sysconfig/network-scripts/ifcfg-eth0
需要修改的内容有五个:
IPADDR=192.168.1.101
GATEWAY=192.168.1.2
ONBOOT=yes
BOOTPROTO=static
DNS1=192.168.1.2
修改前:

修改后:

- 执行 service network restart 如果报错,那就重启虚拟机
- 修改主机名称:vim /etc/sysconfig/network,之后在vim /etc/hosts 进行ip和主机名称映射
- 关闭防火墙:
-
查看防火墙状态:chkconfig iptables –list
-
关闭防火墙:chkconfig iptables off
7、安装hadoop: -
解压hadoop: tar -zxf hadoop-2.7.2.tar.gz -C /opt/module/
-
在/opt/module/hadoop-2.7.2/etc/hadoop 路径下配置 hadoop-env.sh(添加jdk路径)
-
将hadoop添加到环境变量:vim /etc/profile 文件添加如下:
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=
PA
T
H
:
PATH:
P
A
T
H
:
HADOOP_HOME/bin
export PATH=
PA
T
H
:
PATH:
P
A
T
H
:
HADOOP_HOME/sbin
8、让修改生效: source /etc/profile,如果不管有就重启
至此hadoop安装完成。
hadoop的运行模式
1、本地模式:不需要启动单独进程,直接运行,测试和开发时候使用
2、伪分布式模式:等同于完全分布式,但是只有一个节点。
3、完全分布式,多个节点
主要回忆一下完全分布式环境的部署:
hadoop完全分布式部署
1、准备 3 台客户机(关闭防火墙、静态 ip、主机名称)
2、用scp命令从第一台虚拟机中拉取hadoop程序包
-
scp命令有三种方式举例:
假设我们的数据在hadoop102上面
a、推,假设我们现在在hadoop101上:scp -r /opt/software/ root@hadoop102:/opt ,-r为递归拉取(拉取文件夹),root为用哪么用户权限拉,hadoop102为地址:/后边为从哪个目录拉取
b、拉,假设我们在hadoop102上,要将101上的数据同步到102上,拉的时候即此时我在scp -r root@hadoop101:/etc/profile /etc/profile
c、我们假设现在在hadoop102上,我们要将103的数据拷贝到104中那么如下:
scp -r root@hadoop103:/opt/test root@hadoop104:/opt/
我们可以看出,数据在那第一个地址就填那个,如果数据不再本机上那么就要加上用户和ip如果在直接写带复制文件路径即可。
3、设置ssh无密登录
-
进入home目录:cd ~/.ssh
-
生成公钥和私钥:
ssh -keygen -t rsa -
将公钥拷贝到免密登录的目标机器上
ssh-copy-id hadoop103
ssh-copy-id hadoop104
其大概过程如下图:

-
.ssh 文件夹下的文件功能解释
a、~/.ssh/known_hosts :记录ssh访问过的公钥
b、id_rsa:私钥
c、id_rsa.pub:公钥
d、authorized_keys:存放授权过的无密登录的公钥
4、同步节点一的配置编写了一个xsync其是根据rsync编写的,rsync和scp的不同之处在于其可以避免复制相同的内容。
在构建之前我们大概来设计一下hadoop的节点分配:
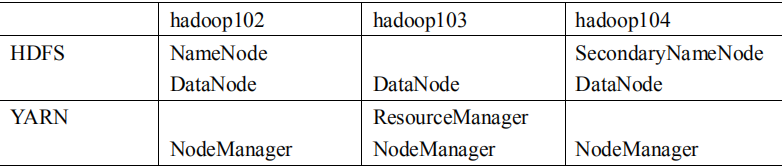
因为namenode、resourceManager、和secondarynamenode都是比较耗费资源的所以最好将他们分开在不同的节点放置。
5、配置文件:
- 首先配置hadoop-env.sh配置jdk环境变量上面提到过
- 其次配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
</configuration>
- yarn-env.sh,也是配置jdk
- yarn-site.sh:
<configuration>
<!-- reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 YARN 的 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
</configuration>
- MapReduce配置,MapReduce的env也是配置jdk
- MapReduce的site:
<configuration>
<!-- 指定 mr 运行在 yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 配置core-site.xml:
<!-- 指定 HDFS 中 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property
-
在hadoop文件夹下创建slaves文件编辑如下:vi slaves
hadoop102
hadoop103
hadoop104
回车分开,就是存放节点ip的
上述只是在一个节点上完成了配置,我们用方才说的xsync进行集群同步这些配置
-
集群启动和测试:
a、如果是第一次启动,那么我们需要格式化namenode:bin/hdfs namenode -format
b、启动hdfs,sbin/start-dfs.sh
c、启动yarn:sbin/start-yarn.sh
注意:Namenode 和 ResourceManger 如果不是同一台机器,不能在 NameNode 上启
动 yarn,应该在 ResouceManager 所在的机器上启动 yarn。
Hadoop 启动停止方式
1)各个服务组件逐一启动
(1)分别启动 hdfs 组件
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
(2)启动 yarn
yarn-daemon.sh start|stop resourcemanager|nodemanager
2)各个模块分开启动(配置 ssh 是前提)常用
(1)整体启动/停止 hdfs
start-dfs.sh
stop-dfs.sh
(2)整体启动/停止 yarn
start-yarn.sh
stop-yarn.sh
3)全部启动(不建议使用)
start-all.sh
stop-all.sh
下面我们开始逐一开始解刨他的组件:
HDFS
HDFS的概念:
HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布
式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS 的设计适合
一次写入,多次读出的场景
,且不支持文件的修改。适合用来做数据
分析,并不适合用来做网盘应用。
HDFS的优缺点
-
优点:
1、高容错性,因为有副本。
2、可存储大量数据,数据规模可达GB、TB甚至PB级别的数据。
3、能保证数据一致性 -
缺点
1、不适合低延迟的数据访问。
2、无法高效的对小文件进行存储
3、一个文件同时只能允许一个线程写入,不允许有多个线程
4、只能对数据进行追加而不能随机修改。
HDFS架构

HDFS 主要由HDFS client,namenode,datenode,secondary namenode组成,我们接下来逐一对其进行回顾:
Client
定于:就是客户端。其主要作用:
- 文件切分,文件上传到hdfs的时候,client将文件切分为一个一个的block,然后在进行存储。
- 与nadenode进行交互获取文件存储位置。
- 与datenode进行交互读取或写入数据
- client还提供了一些参数可以来操作hdfs
HDFS的文件块大小
HDFS中的文件在物理上是分块的,块大小可以通过参数来配置(dfs.blocksize),默认大小为hadoop2.x大小为128m,老版本为64m。
HDFS的块比磁盘大,其目的就是为了最小化寻址开销,如果一个块足够大那么他的传输时间就会明显大于寻址时间,因此传输一个由多个块组成的文件其时间就会取决于磁盘的传输速率而不是寻址开销。
我们假设寻址时间约为10ms,而传输的速率为100m/s,那么我们要让寻址时间为传输时间的1%,那么就是要求传输时间为1s即传输数据量为100m。所以我们才会让block的大小为128m。
hdfs命令
| 命令 | 含义 | 举例 |
|---|---|---|
| sbin/start-dfs.sh | 启动dfs | null |
| sbin/start-yarn.sh | 启动yarn | null |
| hadoop fs -ls / | 查看目录文件 | null |
| hadoop fs -mkdir | 创建目录 | hadoop fs -mkdir -p /user/atguigu/test |
| -moveFromLocal | 将本地文件剪切到hdfs | hadoop fs -moveFromLocal ./jinlian.txt /user/atguigu/test |
| –appendToFile | 追加一个文件到已经存在的文件末尾 | hadoop fs -appendToFile ximen.txt /user/atguigu/test/jinlian.txt |
| -cat | 显示文件内容 | hadoop -fs cat /text |
| -tail | 显示文件的末尾 | hadoop fs -tail /user/atguigu/test/jinlian.txt |
| -chmod | 改变读写权限 | hadoop fs -chmod 666 /user/atguigu/test/jinlian.txt |
| -chown | 改变文件拥有者 | hadoop fs -chown atguigu:atguigu /user/atguigu/test/jinlian.txt |
| -copyFromLocal | 从本地拷贝到hdfs | hadoop fs -copyFromLocal README.txt /user/atguigu/test |
| -copyToLocal | 从hdfs拷贝到本地 | hadoop fs -copyToLocal /user/atguigu/test/jinlian.txt ./jinlian.txt |
| -cp | 从hdfs的一个位置拷贝到hdfs的另一个地方 | hadoop fs -cp /user/atguigu/test/jinlian.txt /jinlian2.txt |
| -mv | 从hdfs的一个地方一地方到另一个地方 | hadoop fs -mv /jinlian2.txt /user/atguigu/test/ |
| -get | 作用等同于copytolocal | hadoop fs -get /user/atguigu/test/jinlian2.txt ./ |
| put | 等同于copyFromLocal | hadoop fs -put ./zaiyiqi.txt /user/atguigu/test/ |
| -rm | 删除文件或文件夹 | hadoop fs -rm /user/atguigu/test/jinlian2.txt |
| -rmdir | 删除空目录 | hadoop fs -rmdir /test |
| -df | 统计文件系统的可用空间信息 | hadoop fs -df -h / |
| -du | 统计文件夹大小 | hadoop fs -du -s -h /user/atguigu/test |
| -setrep | 设置文件副本数 | hadoop fs -setrep 2 /user/atguigu/test/jinlian.txt |
HDFS写数据流程

- 客户端通过distributedFileSystem请求namenode上传数据,namenode检查上传的路径是否存在,上传的文件是否存在。
- namenode返回是否可以上传
- client请求上传第一个block,请返回datenode节点
- namenode返回dn1,dn2,dn3节点
- client通过FSDateoutputstream请求dn1建立连接通道,dn1请求dn2,dn2请求dn3
- dn1,dn2,dn3逐级应答
- 传输数据,客户端向dn1传输第一个block,以packet为单位,dn1收到数据后会传给dn2,dn2会传给dn3
- 当一个block传输完成后,客户端再次请求namenode上传第二个block并重复3-7.
HDFS读数据流程

- client通过distributedFileSystem请求namenode读取数据
-
namenode返回
最近
的数据存放节点 - client通过FsDateInputStream请求datenode1读数据
- 与datenode1读取数据到client
- 重复以上过程
机架感知
上面提到了最近一次那么自hadoop中是怎么感知最近的呢?
网络拓扑概念
在本地网络中我们用两个节点之间的带宽来衡量远近,节点距离:两个节点到达最近共同祖先的距离之和。
例如,假设有数据中心 d1 机架 r1 中的节点 n1。该节点可以表示为/d1/r1/n1。利用这种
标记,这里给出四种距离描述

如图
-
d1/r1/n0上面的进程同d1/r1/n0的进程之间叫做同一节点上的进程
-
d1/r1/n0上的进程同d1/r1/n2上的节点进程叫做同一机架上不同的节点
-
d1/r1/n0上的进程同d1/r2/n0叫做同一集群不同机架的节点
-
d1/r1/n0上的进程同d2/r4/n0叫做不同集群之间的节点
以上距离卓见增加
算一算每两个节点之间的距离。

例如节点9和节点7之间的距离就是到达他们共同的祖先8的距离和,为2
机架感知
低版本的Hadoop副节点的选择为右上角:
- 第一个副本在client节点上,如果client在集群外那么就随机选取一个
- 第二个副本选择同第一个副本在同一集群不同机架上的节点
-
选择在第二个副本相同的机架下的不同节点
如图:

新版本的hadoop选择如下
1、第一个副本选择与client同一节点,如果client在集群外那么随机选取
2、选择同第一个节点同一机架不同节点上的位置
3、第三个副本选择同第一个第二个在不同机架上的节点

之所以有上面的变化是因为我们的计算机越来越可靠了。
HDFS 满足客户端访问副本数据的最近原则。即客户端距离哪个副本数据最近,HDFS
就让哪个节点把数据给客户端。
NameNode工作机制

- 当namenode第一次格式化后执行,创建edits和fsimage,如果不是就在内存中加载这两个文件
- 当客户端请求对hdfs增删改查的时候,先在日志中记载然后在在内存中真正进行操作
- secondary namenode求情namenode是否需要检查点,直接带回namenode是否需要检查点结果
- namenode回滚正在记录的日志文件
- secondary namenode 拷贝日志和镜像
- secondary namenode在内存中合并两个文件,并生成新的fsimage.checkpoint
- 将生成的新的fsimage.checkpoint拷贝到namenode并去掉后缀
镜像文件和编辑日志文件
namenode被格式化后会在/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current目录下有下面文件:
- edits_0000000000000000000
- fsimage_0000000000000000000.md5
- seen_txid
-
VERSION
1、Fsimage 文件:HDFS 文件系统元数据的一个永久性的检查点,其中包含 HDFS
文件系统的所有目录和文件 idnode 的序列化信息。
2、Edits 文件:存放 HDFS 文件系统的所有更新操作的路径,文件系统客户端执行
的所有写操作首先会被记录到 edits 文件中
3、seen_txid 文件保存的是一个数字,就是最后一个 edits_的数字
4、每次 Namenode 启动的时候都会将 fsimage 文件读入内存,并从 00001 开始
到 seen_txid 中记录的数字依次执行每个 edits 里面的更新操作,保证内存中的元数据信息
是最新的、同步的,可以看成 Namenode 启动的时候就将 fsimage 和 edits 文件进行了合
并
web 端访问 SecondaryNameNode 端口号
浏览器中输入:http://hadoop104:
50090
/status.html
chkpoint 检查时间参数设置
(1)通常情况下,SecondaryNameNode 每隔一小时执行一次。
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
(2)一分钟检查一次操作次数,当操作次数达到 1 百万时,SecondaryNameNode 执行
一次也可以用如上配置
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1 分钟检查一次操作次数</description>
</property>
SecondaryNameNode 目录结构
Secondary NameNode 用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS元数据的快照。在 /opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/current 这 个 目 录 中 查 看
SecondaryNameNode 目录结构。
- edits_0000000000000000001-0000000000000000002
- fsimage_0000000000000000002
- fsimage_0000000000000000002.md5
-
VERSION
SecondaryNameNode 的 namesecondary/current 目录和主 namenode 的 current 目录的布局
相同。
好 处 : 在 主 namenode 发 生 故 障 时 ( 假 设 没 有 及 时 备 份 数 据 ) , 可 以 从
SecondaryNameNode 恢复数据
NameNode故障处理方法
Namenode 故障后,可以采用如下两种方法恢复数据。
方法一:将 SecondaryNameNode 中数据拷贝到 namenode 存储数据的目录;
方 法 二 : 使 用 -importCheckpoint 选 项 启 动 namenode 守 护 进 程 , 从 而 将
SecondaryNameNode 中数据拷贝到 namenode 目录中。
集群安全模式操作
当我们的NamoNode启动的时候,首先会加载镜像文件到内存,当加载完成后创建了文件系统的元数据映像后会创建一个新的fsimage和edits日志,但此时,namenode对于客户端是只读的,因为其运行在安全模式下。之所以有这个过程是因为我们的数据块存放位置不在namenode中而是存储在datenode中,运行时候只是在namenode中维护了一个块位置的映射信息,那么对于刚启动的namenode来说没有这一映射,所以此时datenode要主动向namenode传送最新的块信息列表,当namenode了解了足够多的块信息后(如果满足了副本条件一般启动后的30s就会退出安全模式,所谓的最小副本条件就是当集群中99.9%的块满足了最小副本数后)就会退出安全模式。不过如果启动了一个刚格式化后的hdfs就没有安全模式了,因为没数据。
查看安全模式的一些命令
- 获取安全模式状态:bin/hdfs dfsadmin -safemode get
- 进入安全模式:bin/hdfs dfsadmin -safemode entry
- 离开安全模式Lbin/hdfs dfsadmin -safemode leave
- 等待结束安全模式:bin/hdfs dfsadmin -safemode wait
DataNode 工作机制

1)一个数据块在 datanode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode 启动后向 namenode 注册,通过后,周期性(1 小时)的向 namenode 上报所有的块信息。
3)心跳是每 3 秒一次,心跳返回结果带有 namenode 给该 datanode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个 datanode 的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器
数据完整性
- 当DateNode读取block时候会进行checksum
- 如果校验和和block创建时候不一致那么就判定此block损坏
- 那就读取其他节点上的block
- DateNode会周期的验证checkPoint
动态节点上下线
服役新节点
1、需求:
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。
2、服役新节点具体步骤
a、将新机器的hadoop配置同其他节点相同
b、在namenode节点上的hadoop根目录下创建dfs.hosts文件并在其中写上原节点和新节点的ip
c、在hdfs-site.xml中添加dfs.hosts文件配置:
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
e、将namenodes的slaves文件中添加新的ip
f、刷新namenode
bin/hdfs dfsadmin -refreshNodes
g、刷新resourceManage节点
bin/yarn rmadmin -refreshNodes
h、在新的节点上用单节点启动的方式启动namenode、和nodeManager
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start nodemanager
如果数据不均衡,可以用命令实现集群的再平衡
退役旧数据节点
a、在 namenode 的/opt/module/hadoop-2.7.2/etc/hadoop 目录下创建 dfs.hosts.exclude 文件,在里面添加要删除的节点
b、在 namenode 的 hdfs-site.xml 配置文件中增加 dfs.hosts.exclude 属性
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value>
</property>
c、刷新 namenode、刷新 resourcemanager
hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes
d、检查 web 浏览器,退役节点的状态为 decommission in progress(退役中),说明数据节点正在复制块到其他节点。
e、等待退役节点状态为 decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是 3,服役的节点小于等于 3,是不能退役成功的,需要修改副本数后才能退役。
sbin/hadoop-daemon.sh stop datanode
sbin/yarn-daemon.sh stop nodemanager
f、从 include 文件中删除退役节点,再运行刷新节点的命令。从 namenode 的 dfs.hosts 文件中删除退役节点 ,刷新 namenode,刷新 resourcemanager
g、从 namenode 的 slave 文件中删除退役节点
h、如果数据不均衡,可以用命令实现集群的再平衡
sbin/start-balancer.sh
HDFS-HA 自动故障转移工作机制
HA 的自动故障转移依赖于ZooKeeper 的以下功能:
1、故障检测,每一个Namenode都在zookeeper中维护了一个持久会话,如果机器崩溃了那么会话就终止了,zookeeper就会通知其他的namenode进行故障转移。
2、现役namenode选择,zookeeper提供了一个简单的机制维护选择唯一一个节点为active。如果目前的namenode崩溃了,另一个节点可能从zookeeper中获取一个排它锁,以表明它应该是现役namenode
ZKFC 是自动故障转移中的另一个新组件,是 ZooKeeper 的客户端,也监视和管理NameNode 的状态。每个运行 NameNode 的主机也运行了一个 ZKFC 进程,ZKFC 负责:
1、健康监测:zkfc会使用一个健康检查命令周期性的ping本机的namenode,如果本机的namenode可以及时的恢复那么就认为他是健康的,当没有及时回复则认定其为不健康的节点。
2、zookeeper会话管理:zkfc在zookeeper中保持了一个会话,如果本机的namenode是active的那么他会有个znode锁,如果会话终止,则锁节点自动删除。
3、基于zookeeper的选择:如果本机的namenode是健康的,且没有一个节点持有znode锁,那么本节点就会试图去获取锁,如果获取成功那么就会变为active,并由这个节点进行故障转移。

MapReduce组件和yarn组件下篇介绍。