通常情况下,缓存是加速系统响应的一种途径,通常情况下只有系统的部分数据。当请求了缓存中没有的数据时,这时候就会回源到DB里面。此时如果黑客故意对上面数据发起大量请求,则DB有可能会挂掉,这就是缓存击穿。当然缓存挂掉的话,正常的用户请求也有可能造成缓存击穿的效果。
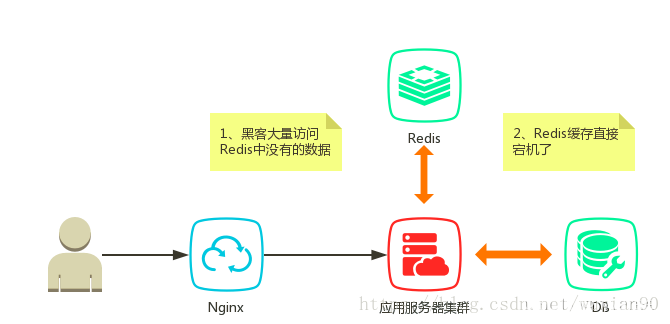
缓存中无值(未宕机)
互斥锁
我们最先想到的应该是加锁获取缓存。也就是当获取的value值为空时(
这里的空表示缓存过期
),先加锁,然后从数据库加载并放入缓存,最后释放锁。如果其他线程获取锁失败,则睡眠一段时间后重试。下面使用Redis的setnx来实现分布式锁,如下所示:
String get(String key) {
String value = redis.get(key);
if (value == null) {
if (redis.setnx(key_mutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(key_mutex, 3 * 60)
value = db.get(key);
redis.set(key, value);
redis.delete(key_mutex);
} else {
//其他线程休息50毫秒后重试
Thread.sleep(50);
get(key);
}
}
}
缓存永不过期
缓存永不过期的意思是:真正的缓存过期时间不有Redis控制,而是由程序代码控制。当获取数据时发现数据超时时,就需要发起一个异步请求去加载数据。这种策略的有点就是不会产生死锁等现象,但是有可能会造成缓存不一致的现象,但是笔者看来一般情况下都是可以适用的。
String get(final String key) {
V v = redis.get(key);
String value = v.getValue();
long timeout = v.getTimeout();
if (v.timeout <= System.currentTimeMillis()) {
// 异步更新后台异常执行
threadPool.execute(new Runnable() {
public void run() {
String keyMutex = "mutex:" + key;
if (redis.setnx(keyMutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(keyMutex, 3 * 60);
String dbValue = db.get(key);
redis.set(key, dbValue);
redis.delete(keyMutex);
}
}
});
}
return value;
}
缓存宕机
上面说到的场景是缓存依旧有效的,当Redis挂掉时,这个时候如何来应对大量的回源请求呢?先来说一种简单的方式:白名单。
白名单
白名单顾名思义就是:在缓存宕机之前的一段时间里,会将请求的数据在系统中的有无,记录在一个Map中。当缓存宕机后,首先在Map中判断是否含有数据,有则回源DB,没有的话就直接返回结果。
这种方式实现起来比较简单(Demo就不提供了),但是占用的内存空间比较庞大。如一个value是10字节,那么要存储大小为1亿的Map时,其所需的内存大小大约是:10 * 2 * 10e8 = 2G(假设Map的利用率为50%)。由此可见其对于一种类型的数据判断就需要一个 2G 的Map去操作,这种方式就不可行了。
布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为:O(n), O(log n), O(n/k)。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。

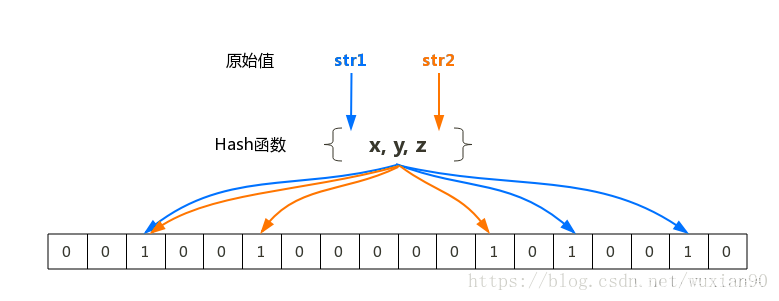
代码实现
在实际应用当中,我们不需要自己去实现BloomFilter。可以使用Guava提供的相关类库即可。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>
判断一个元素是否在集合中
public class Test1 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
long startTime = System.nanoTime(); // 获取开始时间
//判断这一百万个数中是否包含29999这个数
if (bloomFilter.mightContain(29999)) {
System.out.println("命中了");
}
long endTime = System.nanoTime(); // 获取结束时间
System.out.println("程序运行时间: " + (endTime - startTime) + "纳秒");
}
}
运行结果如下:
命中了
程序运行时间: 441616纳秒
自定义错误率
public class Test3 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.01);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
// 故意取10000个不在过滤器里的值,看看有多少个会被认为在过滤器里
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
}
运行结果如下:
误判的数量:94
对于缓存宕机的场景,使用
白名单或者布隆过滤器都有可能会造成一定程度的误判
。原因是除了Bloom Filter 本身有误判率,宕机之前的缓存不一定能
覆盖到所有DB中的数据
,当宕机后用户请求了一个以前从未请求的数据,这个时候就会产生误判。当然,缓存宕机时使用白名单/布隆过滤器作为应急的方式,这种情况应该也是可以忍受的。