1. 字典特征抽取
代码
from sklearn.feature_extraction import DictVectorizer
def dictvec():
#字典数据抽取
#实例化
dict=DictVectorizer(sparse=False)
#调用fit_transform,字典储存在列表中
data=dict.fit_transform([{'city': '北京','temperature': 100}
, {'city': '上海','temperature':60}, {'city': '深圳','temperature': 30}])
print(dict.get_feature_names())
print(dict.inverse_transform(data))
print(data)
if __name__=="__main__":
dictvec()
结果

2、文本特征抽取
代码
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
def countvec():
#对文本进行特征值化
CV=CountVectorizer()
data=CV.fit_transform(["life is short,i like python","life is too long,i dislike python"])
print(CV.get_feature_names()) #统计所有文章当中所有的词,重复的只看做一次 词的列表
print(data.toarray()) #对每篇文章,在词的列表里面进行统计每个词出现的次数
if __name__=="__main__":
countvec()
结果

3、中文文本特征抽取
代码
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cutword():
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。")
con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")
con3 = jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。")
#转换成列表
content1=list(con1)
content2=list(con2)
content3=list(con3)
#把列表换换成字符串
c1=" ".join(content1)
c2 = " ".join(content2)
c3 = " ".join(content3)
return c1, c2, c3
def hanzi():
#中文特征值化
c1,c2,c3=cutword()
print(c1,c2,c3)
CV = CountVectorizer()
data = CV.fit_transform([c1,c2,c3]) # 需要对中文进行分词处理
print(CV.get_feature_names()) # 统计所有文章当中所有的词,重复的只看做一次 词的列表
print(data.toarray()) # 对每篇文章,在词的列表里面进行统计每个词出现的次数
if __name__=="__main__":
hanzi()
结果

显示为矩阵结果:data.toarray()
4、tfidf实例
代码
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
import jieba
def tfidfvec():
#中文特征值化
c1,c2,c3=cutword()
print(c1,c2,c3)
tf = TfidfVectorizer()
data = tf.fit_transform([c1,c2,c3]) # 需要对中文进行分词处理
print(tf.get_feature_names()) # 统计所有文章当中所有的词,重复的只看做一次 词的列表
print(data.toarray()) # 对每篇文章,在词的列表里面进行统计每个词出现的次数
if __name__=="__main__":
tfidfvec()
结果

5、二维数组的归一化
代码
from sklearn.preprocessing import MinMaxScaler
def mm():
#归一化处理
mm=MinMaxScaler(feature_range=(2,3))
data=mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])
print(data)
return None
if __name__=="__main__":
mm()
结果

6、标准化实例
代码
from sklearn.preprocessing import MinMaxScaler,StandardScaler
def stand():
#标准化缩放
std=StandardScaler()
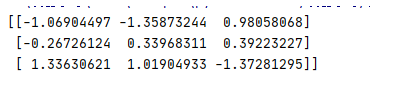
data=std.fit_transform([[1.,-1.,3.],[2.,4.,2.],[4.,6.,-1.]])
print(data)
if __name__=="__main__":
stand()
结果
7、缺失值填补实例
代码
from sklearn.impute import SimpleImputer
import numpy as np
def im():
#缺失值
im=SimpleImputer(missing_values=np.nan, strategy=“mean”)
data=im.fit_transform([[1,2],[np.nan,3],[7,6]])
print(data)
if
name
==“
main
”:
im()
结果

8、过滤式特征选择
代码
from sklearn.feature_selection import VarianceThreshold
def var():
#特征选择
var=VarianceThreshold(threshold=1.0) #取值根据实际的需求
data=var.fit_transform([[0,2,0,3],[0,1,4,3],[0,1,1,3]])
print(data)
if __name__=="__main__":
var()
结果

9、pca实例
代码
from sklearn.decomposition import PCA
def pca():
#主成分分析进行特征降维
pca=PCA(n_components=0.9)
data=pca.fit_transform([[2,8,4,5],[6,3,0,8],[5,4,9,1]])
print(data)
if __name__=="__main__":
pca()
结果:四个特征变成两个,减少至0.9

10、降维案例01
代码
import pandas as pd
from sklearn.decomposition import PCA
#读取4张表
prior=pd.read_csv("./data/instacart/order_products_prior.csv")
products=pd.read_csv("./data/instacart/")
orders=pd.read_csv("./data/instacart/")
aisles=pd.read_csv("./data/instacart/")
#合并四张表到一张表当中 (用户-物品类别)
_mg=pd.merge(prior,products,on=["product_id","product_id"])
_mg=pd.merge(_mg, orders,on=["order_id","order_id"])
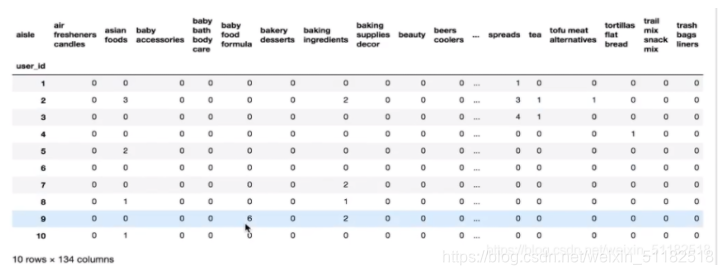
mt=pd.merge(_mg,aisles,on=["aisle_id","aisle_id"])
print(mt.head(10))
#建立行和列
# 交叉表 特殊的分组工具
cross=pd.crosstab(mt["user_id"],mt["aisle"])
#进行主成分分析
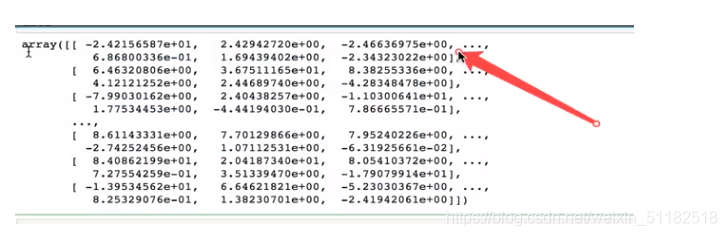
pca=PCA(n_components=0.9)
data=pca.fit_transform(cross)
print(data)
1、合并表找到order_id 和 aisle_id的关系
2、用交叉表转换
结果
交叉表
主成分分析后的结果
11、数据集划分 获取鸢尾花数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
li=load_iris()
# print("获取特征值")
# print(li.data)
# print("获取目标值")
# print(li.target)
# print(li.DESCR)
#注意返回值,训练集 train x_train y_train 测试集 test x_test y_test
x_train,x_test,y_train, y_test=train_test_split(li.data,li.target,test_size=0.25)
print("训练集特征值和目标值:",x_train,y_train)
print("测试集特征值和目标值:",x_test,y_test)
12、回归数据集 波士顿房价数据集
代码
from sklearn.datasets import fetch_20newsgroups,load_boston
# news=fetch_20newsgroups(subset="all")
# print(news.data)
# print(news.target)
lb=load_boston()
print("获取特征值")
print(lb.data)
print("获取目标值")
print(lb.target)
print(lb.DESCR)
结果

13 k-近邻算法实例
代码
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
def knn():
#k-近邻预测用户签到位置
#读取数据
data=pd.read_csv("./facebookdata/train.csv")
#print(data.head(10)) #打印data数据前十行
#处理数据
#1、缩小数据.查询数据筛选
data=data.query("x > 1.0 & x < 1.25 & y>2.5 & y<2.75")
#2、处理时间的数据
time_value=pd.to_datetime(data["time"],unit="s")
print(time_value)
#把日期格式转换成字典
time_value=pd.DatetimeIndex(time_value)
#3、 构造一些特征
data["second"]=time_value.day
data["hour"]=time_value.hour
data["weekday"]=time_value.weekday
# 4、 把时间戳特征删除
data=data.drop(["time"], axis=1) #pandas里列是1
data=data.drop(["row_id"],axis=1)
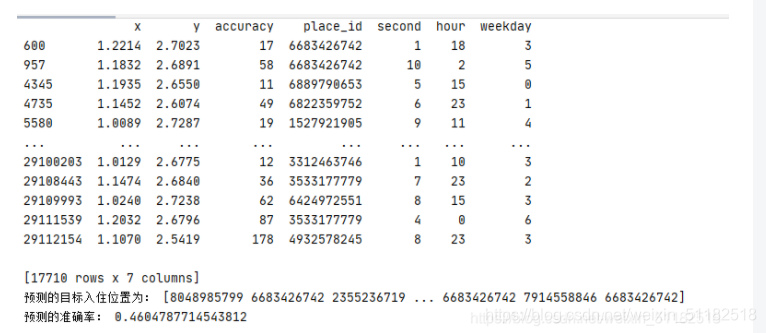
print(data)
# 5、将签到数量小于n个的目标位置删除
place_count=data.groupby("place_id").count()
tf=place_count.reset_index()
data=data[data["place_id"].isin(tf.place_id)]
#6、取出数据当中的特征值和目标值
y=data["place_id"]
x=data.drop(["place_id"],axis=1)
# 7、进行数据的分割训练集测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
#特征工程(标准化)目标值不需要标准化 对测试集和训练集的特征值进行标准化
std=StandardScaler()
x_train=std.fit_transform(x_train)
x_test=std.transform(x_test)
#进行算法流程
knn=KNeighborsClassifier(n_neighbors=5)
#fit,predict,score
knn.fit(x_train,y_train) #传入训练集
#得出运算结果
y_predict= knn.predict(x_test)
print("预测的目标入住位置为:",y_predict)
# 得出准确率 y_test 和y_predict
print("预测的准确率:",knn.score(x_test,y_test))
if __name__=="__main__":
knn()
结果
14、对20类新闻稿进行朴素贝叶斯算法的分类和预测
代码
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import fetch_20newsgroups,load_boston
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
def naviebayes():
#朴素贝叶斯进行文本分类
news=fetch_20newsgroups(subset="all")
#进行时飓风厄
x_train,x_test,y_train,y_test=train_test_split(news.data,news.target,test_size=0.25)
#对数据集进行特征抽取
tf=TfidfVectorizer()
#以训练集当中的词的列表进行每篇文章重要性统计["a","b","c","d"]
x_train=tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test=tf.transform(x_test)
#进行朴素贝叶斯算法的预测
mlt=MultinomialNB(alpha=1.0)
print(x_train.toarray())
mlt.fit(x_train,y_train)
y_predict=mlt.predict(x_test)
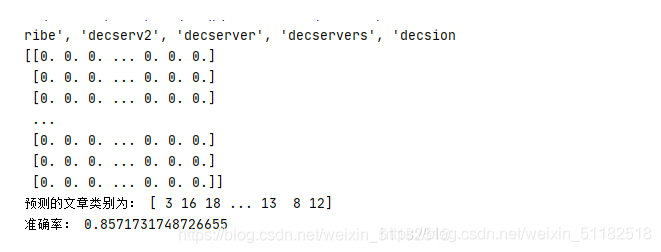
print("预测的文章类别为:",y_predict)
#得出准确率
print("准确率:",mlt.score(x_test,y_test))
if __name__=="__main__":
naviebayes()
结果
15、 对于facebook-ins上酒店入住位置进行超参数网格搜索,确定最好的k值
代码
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
def knn():
#k-近邻预测用户签到位置
#读取数据
data=pd.read_csv("./facebookdata/train.csv")
#print(data.head(10)) #打印data数据前十行
#处理数据
#1、缩小数据.查询数据筛选
data=data.query("x > 1.0 & x < 1.25 & y>2.5 & y<2.75")
#2、处理时间的数据
time_value=pd.to_datetime(data["time"],unit="s")
print(time_value)
#把日期格式转换成字典
time_value=pd.DatetimeIndex(time_value)
#3、 构造一些特征
data["second"]=time_value.day
data["hour"]=time_value.hour
data["weekday"]=time_value.weekday
# 4、 把时间戳特征删除
data=data.drop(["time"], axis=1) #pandas里列是1
data=data.drop(["row_id"],axis=1)
print(data)
# 5、将签到数量小于n个的目标位置删除
place_count=data.groupby("place_id").count()
tf=place_count.reset_index()
data=data[data["place_id"].isin(tf.place_id)]
#6、取出数据当中的特征值和目标值
y=data["place_id"]
x=data.drop(["place_id"],axis=1)
# 7、进行数据的分割训练集测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
#特征工程(标准化)目标值不需要标准化 对测试集和训练集的特征值进行标准化
std=StandardScaler()
x_train=std.fit_transform(x_train)
x_test=std.transform(x_test)
#进行算法流程
knn=KNeighborsClassifier()
#构造一些参数的值
param={"n_neighbors":[3,5,10]}
#进行网格搜索
gd=GridSearchCV(knn,param_grid=param,cv=2)
gd.fit(x_train,y_train)
#预测准确率
print("测试继中的准确率吧:",gd.score(x_test,y_test))
print("在交叉验证中最好的结果:",gd.best_score_)
print("在交叉验证中最好的模型:",gd.best_estimator_)
print("每个超参数每次交叉验证的结果:",gd.cv_results_)
if __name__=="__main__":
knn()
结果

实例 16、决策树:泰坦尼克号乘客生存分类模型
代码
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier,export_graphviz
def decision():
#决策树对泰坦尼克号进行预测生死
#获取数据
titan=pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
#处理数据,找出特征值和目标值
x=titan[["pclass","age","sex"]]
y=titan["survived"]
#缺失值处理
x["age"].fillna(x["age"].mean(),inplace=True)
#分割数据集的训练及和测试继
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
#进行处理(特征工程)特征-类别-one_hot编码
dict=DictVectorizer(sparse=False)
x_train=dict.fit_transform(x_train.to_dict(orient="records")) #按行转换为字典
x_test=dict.fit_transform(x_test.to_dict(orient="records"))
#用决策树进行预测
dc=DecisionTreeClassifier(max_depth=5)
dc.fit(x_train,y_train)
print("预测的准确率:", dc.score(x_test,y_test))
#导出决策树的结构
export_graphviz(dc,out_file="./tree.dot",feature_names=["年龄","pclass=1st","pclass=2nd","pclass=3rd","女性","男性"])
if __name__=="__main__":
decision()
实例 17、随机森林:泰坦尼克号乘客生存分类模型调优
代码
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier,export_graphviz
from sklearn.ensemble import RandomForestClassifier
def decision():
#决策树对泰坦尼克号进行预测生死
#获取数据
titan=pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
#处理数据,找出特征值和目标值
x=titan[["pclass","age","sex"]]
y=titan["survived"]
#缺失值处理
x["age"].fillna(x["age"].mean(),inplace=True)
#分割数据集的训练及和测试继
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
#进行处理(特征工程)特征-类别-one_hot编码
dict=DictVectorizer(sparse=False)
x_train=dict.fit_transform(x_train.to_dict(orient="records")) #按行转换为字典
x_test=dict.fit_transform(x_test.to_dict(orient="records"))
#随机森林进行预测 (超参数调优)
rf=RandomForestClassifier()
#网格搜索与交叉验证
param={"n_estimators":[120,200,300,500,800,1200],"max_depth":[5,8,15,25,30]} #共有30次组合
gc=GridSearchCV(rf,param_grid=param,cv=2)
gc.fit(x_train,y_train)
print("准确率为:",gc.score(x_test,y_test))
print("查看选择的参数模型", gc.best_params_) #随机森林不能导出决策树结构
if __name__=="__main__":
decision()
18、线性回归模型算法预测波士顿房价数据集(正规方程和梯度下降)
代码
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np
def mylinear():
#线性回归直接预测房子价格
#获取数据
lb=load_boston()
#分割数据集到训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(lb.data,lb.target,test_size=0.25)
#进行标准化处理 目标值也需要标准化处理
std_x=StandardScaler()
x_train=std_x.fit_transform(x_train)
x_test=std_x.fit_transform(x_test)
std_y=StandardScaler()
y_train=std_y.fit_transform(y_train.reshape(-1,1))
y_test=std_y.fit_transform(y_test.reshape(-1,1))
#特征值和目标值是都必须标准化处理,要分开标准化处理,实例化两个标准api
#estimator预测
#正规方程求解方式预测结果
lr=LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_) #预测没有准确率这个说法
# 预测测试集房子价格
y_predict=std_y.inverse_transform(lr.predict(x_test)) #将标准化的结果返回数据化特征
print("测试继里面每个房子的预测价格:",y_predict.transpose())
#梯度下降去进行房价预测
sgd=SGDRegressor()
sgd.fit(x_train,y_train)
print(sgd.coef_) #预测没有准确率这个说法
# 预测测试集房子价格
y_sgd_predict=std_y.inverse_transform(sgd.predict(x_test)) #将标准化的结果返回数据化特征
print("测试继里面每个房子的预测价格:",y_sgd_predict)
if __name__=="__main__":
mylinear()
结果

加入均方误差的代码
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np
from sklearn.metrics import mean_squared_error
def mylinear():
#线性回归直接预测房子价格
#获取数据
lb=load_boston()
#分割数据集到训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(lb.data,lb.target,test_size=0.25)
#进行标准化处理 目标值也需要标准化处理
std_x=StandardScaler()
x_train=std_x.fit_transform(x_train)
x_test=std_x.fit_transform(x_test)
std_y=StandardScaler()
y_train=std_y.fit_transform(y_train.reshape(-1,1))
y_test=std_y.fit_transform(y_test.reshape(-1,1))
#特征值和目标值是都必须标准化处理,要分开标准化处理,实例化两个标准api
#estimator预测
#正规方程求解方式预测结果
lr=LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_) #预测没有准确率这个说法
# 预测测试集房子价格
y_predict=std_y.inverse_transform(lr.predict(x_test)) #将标准化的结果返回数据化特征
print("测试继里面每个房子的预测价格:",y_predict.transpose())
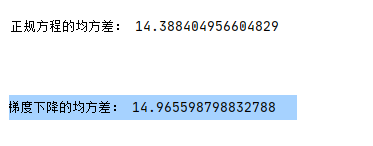
print("正规方程的均方差:",mean_squared_error(std_y.inverse_transform(y_test),y_predict))
#梯度下降去进行房价预测
sgd=SGDRegressor()
sgd.fit(x_train,y_train)
print(sgd.coef_) #预测没有准确率这个说法
# 预测测试集房子价格
y_sgd_predict=std_y.inverse_transform(sgd.predict(x_test)) #将标准化的结果返回数据化特征
print("测试继里面每个房子的预测价格:",y_sgd_predict)
print("梯度下降的均方差:", mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))
if __name__=="__main__":
mylinear()
结果
19、岭回归算法:波士顿房价预测
代码
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor,Ridge
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np
from sklearn.metrics import mean_squared_error
def mylinear():
#线性回归直接预测房子价格
#获取数据
lb=load_boston()
#分割数据集到训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(lb.data,lb.target,test_size=0.25)
#进行标准化处理 目标值也需要标准化处理
std_x=StandardScaler()
x_train=std_x.fit_transform(x_train)
x_test=std_x.fit_transform(x_test)
std_y=StandardScaler()
y_train=std_y.fit_transform(y_train.reshape(-1,1))
y_test=std_y.fit_transform(y_test.reshape(-1,1))
#特征值和目标值是都必须标准化处理,要分开标准化处理,实例化两个标准api
#estimator预测
#正规方程求解方式预测结果
lr=LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_) #预测没有准确率这个说法
# 预测测试集房子价格
y_predict=std_y.inverse_transform(lr.predict(x_test)) #将标准化的结果返回数据化特征
print("测试继里面每个房子的预测价格:",y_predict.transpose())
print("正规方程的均方差:",mean_squared_error(std_y.inverse_transform(y_test),y_predict))
#梯度下降去进行房价预测
sgd=SGDRegressor()
sgd.fit(x_train,y_train)
print(sgd.coef_) #预测没有准确率这个说法
# 预测测试集房子价格
y_sgd_predict=std_y.inverse_transform(sgd.predict(x_test)) #将标准化的结果返回数据化特征
print("测试继里面每个房子的预测价格:",y_sgd_predict)
print("梯度下降的均方差:", mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))
#岭回归去进行房价预测
rd=Ridge(alpha=1.0)
rd.fit(x_train,y_train)
print(rd.coef_) #预测没有准确率这个说法
# 预测测试集房子价格
y_rd_predict=std_y.inverse_transform(rd.predict(x_test)) #将标准化的结果返回数据化特征
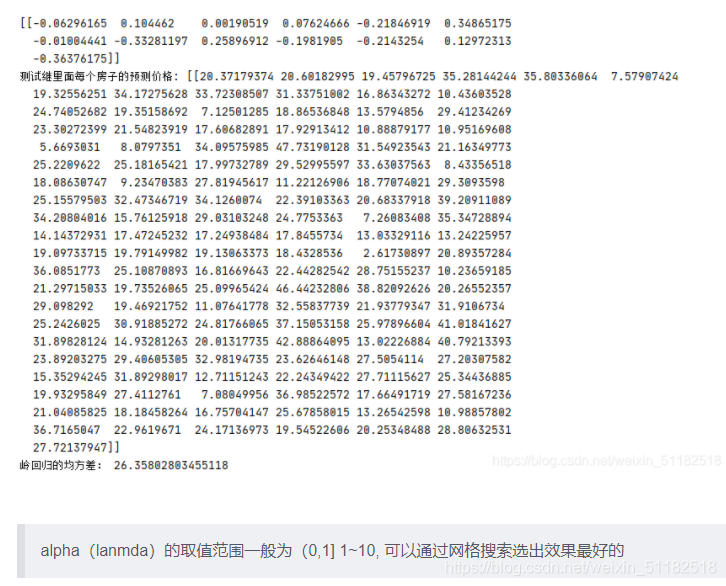
print("测试继里面每个房子的预测价格:",y_rd_predict.transpose())
print("岭回归的均方差:", mean_squared_error(std_y.inverse_transform(y_test), y_rd_predict))
if __name__=="__main__":
mylinear()
结果
20、用逻辑回归对癌症实例进行预测
代码
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor,Ridge,LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
import numpy as np
import joblib
import pandas as pd
def logistic():
'''
逻辑回归做二分类进行癌症预测(根据细胞的属性特征)
'''
#构造列标签
column=["sample code number","clump thickness","uniformtity of cell size","uniformity of cell shape","marginal adhesion",
"single epithelial cell size","bare nuclei","bland chromatin","normal nucleoli","mitoses","class"]
#读取数据
data=pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",names=column)
print(data)
#缺失值进行数据处理
data=data.replace(to_replace="?",value=np.nan)
#将np.nan删除
data=data.dropna()
#进行数据分割,特征值为第2列到10列,目标值为第11列
x_train, x_test, y_train, y_test = train_test_split(data[column[1:10]], data[column[10]], test_size=0.25)
#进行标准化处理, 目标值不需要标准化 预测属于4的概率(癌症发生的概率)
std=StandardScaler()
x_train=std.fit_transform(x_train)
x_test=std.fit_transform(x_test)
#逻辑回归预测
lg=LogisticRegression(C=1.0)
lg.fit(x_train,y_train)
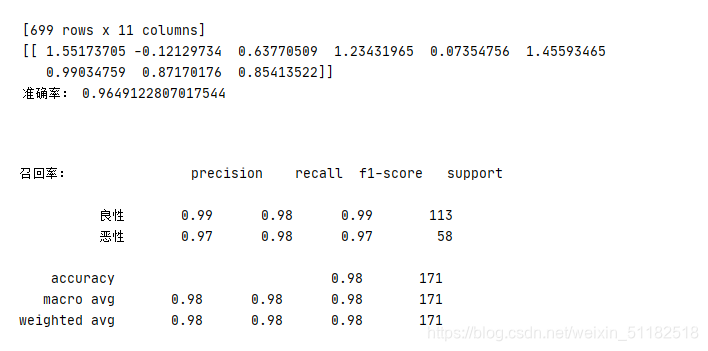
print(lg.coef_)
y_predict=lg.predict(x_test)
print("准确率:",lg.score(x_test,y_test))
#考虑召回率
print("召回率:",classification_report(y_test, y_predict, labels=[2,4],target_names=["良性","恶性"]))
if __name__=="__main__":
logistic()
结果
21、对instacart market进行k-means聚类
代码
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
#读取4张表
prior=pd.read_csv("./data/order_products__prior.csv")
products=pd.read_csv("./data/products.csv")
orders=pd.read_csv("./data/orders.csv")
aisles=pd.read_csv("./data/aisles.csv")
pd.set_option('display.max_columns', None)
#合并四张表到一张表当中 (用户-物品类别)
_mg=pd.merge(prior,products,on=["product_id","product_id"])
_mg=pd.merge(_mg, orders,on=["order_id","order_id"])
mt=pd.merge(_mg,aisles,on=["aisle_id","aisle_id"])
print(mt.head(10))
#建立行和列
# 交叉表 特殊的分组工具
cross=pd.crosstab(mt["user_id"],mt["aisle"])
#进行主成分分析
pca=PCA(n_components=0.9)
data=pca.fit_transform(cross)
#假设用户一共分为四个类别
#把样本数量减少
x=data[:500]
#聚类
km=KMeans(n_clusters=4)
km.fit(x)
predict=km.predict(x)
#显示聚类的结果
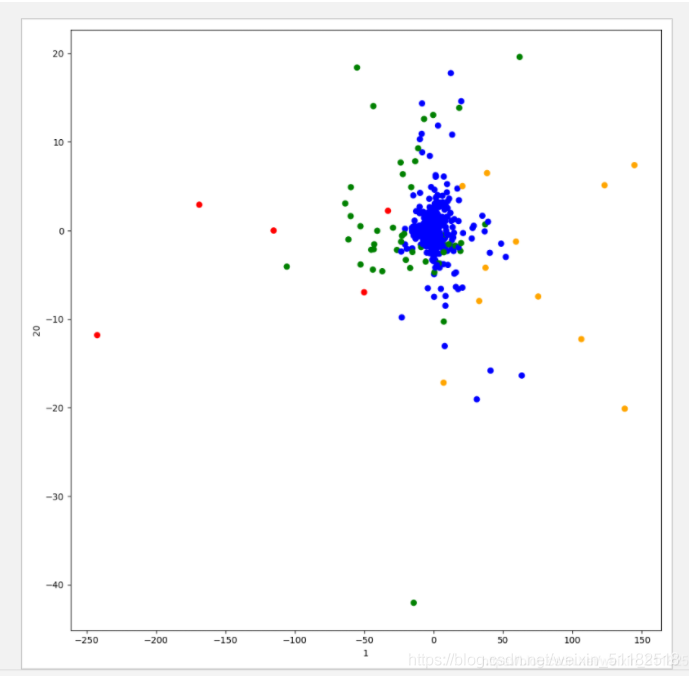
plt.figure(figsize=(10,10))
#建立四个颜色的列表
color=["red","blue","green","orange"]
color=[color[i] for i in predict]
plt.scatter(x[:,1],x[:,20],color=color)
plt.xlabel("1")
plt.ylabel("20")
plt.show()
结果
版权声明:本文为weixin_51182518原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。