文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 了解Spark的MLlib概念;
⚪ 掌握Spark的MLlib基本数据模型;
⚪ 掌握Spark的MLlib统计量基础;
一、Spark MLlib介绍
1. 概述
MLlib是Apache Spark的可迭代机器学习库。
2. 易于使用
适用于Java、Scala、Python和R语言。
MLlib适用于Spark的API,并与Python中的NumPy(从Spark 0.9开始)和R库(从Spark 1.5开始)互操作。 您可以使用任何Hadoop数据源(例如HDFS,HBase或本地文件),从而轻松插入Hadoop工作流程。
案例:
// 通过Python调用MLib
data = spark.read.format(“libsvm”).load(“hdfs://…”)
model = KMeans(k=10).fit(data)
3. 执行高效
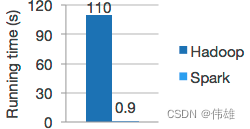
高质量的算法,比 MapReduce 快100倍。
Spark擅长迭代计算,使MLlib能够快速运行。 同时,我们关注算法性能:MLlib包含利用迭代的高质量算法,并且可以产生比MapReduce上有时使用的一次通过近似更好的结果。Hadoop 和 Spark的数据模型,如下图所示。
4. 易于部署
Spark运行在Hadoop,Apache Mesos,Kubernetes,standalone或云端,针对不同的数据源。
您可以使用其独立群集模式,EC2,Hadoop YARN,Mesos或Kubernetes运行Spark。 访问HDFS,Apache Cassandra,Apache HBase,Apache Hive和数百个其他数据源中的数据。
5. 算法
MLlib包含许多算法和实用程序。
ML算法包括:
1. 分类:逻辑回归,朴素贝叶斯,……。
2. 回归:广义线性回归,生存回归,……。
3. 决策树,随机森林和梯度提升树。
4. 建议:交替最小二乘法(ALS)。
5. 聚类:K均值,高斯混合(GMM),……。
6. 主题建模:潜在Dirichlet分配(LDA)。
7. 频繁项目集,关联规则和顺序模式挖掘。
ML工作流程工具包括:
1. 特征转换:标准化,规范化,散列,……。
2. ML Pipeline construction。
3. 模型评估和超级参数调整。
4. ML持久性:保存和加载模型和Pipelines。
其他工具包括:
分布式线性代数:SVD,PCA,……。
统计:汇总统计,假设检验,……。
6. 总结
MLlib是一个构建在Spark上的、专门针对大数据处理的并发式高速机器学习库,其特点是采用较为先进的迭代式、内存存储的分析计算,使得数据的计算处理速度大大高于普通的数据处理引擎。
MLlib机器学习库还在不停地更新中,Apache的相关研究人员仍在不停地为其中添加更多的机器学习算法。目前MLlib中已经有通用的学习算法和工具类,包括统计、分类、回归、聚类、降维等。
MLlib采用Scala语言编写,Scala语言是运行在JVM上的一种函数式编程语言,特点就是可移植性强,“一次编写,到处运行”是其最重要的特点。借助于RDD数据统一输入格式,让用户可以在不同的IDE上编写数据处理程序,通过本地化测试后可以在略微修改运行参数后直接在集群上运行。对结果的获取更为可视化和直观,不会因为运行系统底层的不同而造成结果的差异与改变。
二、MLlib基本数据模型
1. 概述
RDD是MLlib专用的数据格式,它参考了Scala函数式编程思想,并大胆引入统计分析概念,将存储数据转化成向量和矩阵的形式进行存储和计算,这样将数据定量化表示,能更准确地整理和分析结果。
多种数据类型
MLlib先天就支持较多的数据格式,从最基本的Spark数据集RDD到部署在集群中的向量和矩阵。同样,MLlib还支持部署在本地计算机中的本地化格式。
下表给出了MLlib支持的数据类型。
|
|
|
|
Local vector |
本地向量集。主要向Spark提供一组可进行操作的数据集合 |
|
Labeled point |
向量标签。让用户能够分类不同的数据集合 |
|
Local matrix |
本地矩阵。将数据结合以矩阵形式存储在本地计算机中 |
|
Distributed matrix |
分布式矩阵。将矩阵集合以矩阵形式存储在分布式计算机中 |
以上就是MLlib支持的数据类型,其中分布式矩阵根据不同的作用和应用场景,又分为四种不同的类型。
2. 本地向量
MLlib使用的本地化存储类型是向量,这里的向量主要由两类构成:
稀疏型数据集(spares)和密集型数据集(dense)
。例如一个向量数据(9,5,2,7),按密集型数据格式可以被设定成(9,5,2,7)进行存储,数据集被作为一个集合的形式整体存储。而对于稀疏型数据,可以按向量的大小存储为(4, Array(0,1,2,3), Array(9,5,2,7))。
案例一:
import org.apache.spark.{SparkConf,SparkContext}
def main(args:Array[String]):Unit={
//–建立密集型向量
//–dense可以将其理解为MLlib专用的一种集合形式,它与Array类似
val vd=Vectors.dense(2,0,6)//
println(vd)
//①参:size。spare方法是将给定的数据Array数据(9,5,2,7)分解成指定的size个部分进行处理,本例中是7个
//③参:输入数据。本例中是Array(9,5,2,7)
//②参:输入数据对应的下标,要求递增,并且最大值要小于等于size
val vs=Vectors.sparse(7,Array(0,1,3,6),Array(9,5,2,7))
println(vs(6))
}
}