一、 慢操作五大原因
如下图所示,主要分为与
操作系统
相关以及与
Redis集群实例之间与内部
相关两个方面
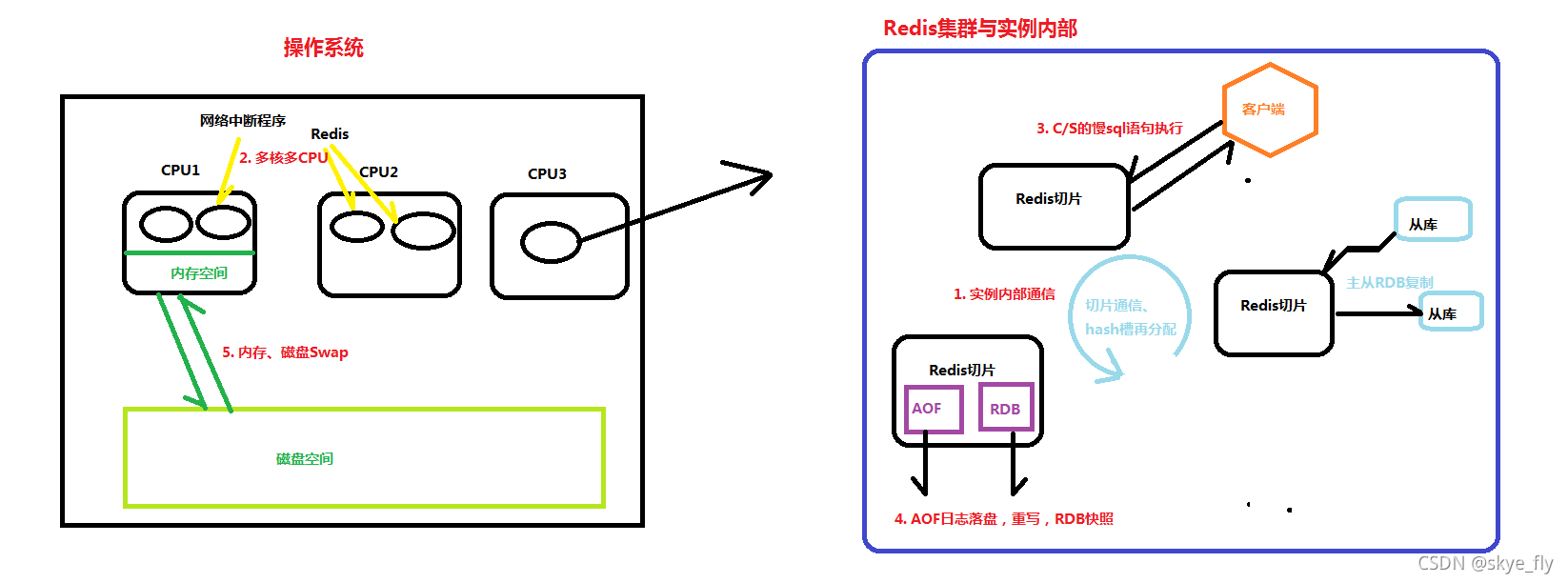
1. Redis实例之间以及内部数据传输阻塞(客户端、磁盘、主从通信、切片集群通信)
解决方法 — 主从集群时,限制主库RDB文件大小。
2. 多CPU多核架构(绑核,绑CPU)
解决方法—绑核绑CPU。
3. sql语句执行阻塞(慢查询、过期key)
解决方法—避免慢查询指令、客户端做聚合、对key设置不同的过期时间、使用异步线程删除bigkey。
4. AOF文件系统,RDB大内存页(AOF持久化阻塞、大内存页)
解决方法—AOF级别调整,使用高速硬盘、关闭大内存页机制。
5. 操作系统Swap操作(内存磁盘数据转换、内存清理)
解决方法—增加机器内存、使用Redis集群、调整内存清理机制触发参数。
二、实际中Redis变慢的可能情况
-
使用
复杂度过高
的命令或一次
查询全量数据
; -
操作
bigkey
; -
大量
key 集中过期
; -
Redis所用内存达到分配给Redis的
maxmemory
; -
客户端使用
短连接
和 Redis 相连; -
当
Redis 实例的数据量大
时,无论是生成 RDB,还是 AOF 重写,都会导致 fork 耗时严重; -
AOF 的写回策略为 always
,导致每个操作都要同步刷回磁盘; -
Redis 实例运行
机器的内存不足
,导致
swap
发生,Redis 需要到 swap 分区读取数据; -
进程
绑定CPU,绑核
不合理; -
Redis 实例运行机器上开启了透明
内存大页机制
; -
网卡压力过大。(
网络IO压力大
)。
三、慢操作排查方法
-
查看
慢查询日志
指令:
slowlog get
(会显示超过预先设定阈值的一些指令,慢日志底层是队列有大小限制,满了会删除队列中最早的记录); -
使用
–bigkeys -i 0.1
指令:
查找每种数据类型中最大的bigkey
,需要扫描全库,
会阻塞主线程
,所以最好放到从库统计,或者用-i指令不连续执行统计操作。
参考文章:
https://time.geekbang.org/column/article/292285
版权声明:本文为skye_fly原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。