给出一个字符串数组words组成的一本英语词典。从中找出最长的一个单词,该单词是由words词典中其他单词逐步添加一个字母组成。若其中有多个可行的答案,则返回答案中字典序最小的单词。
若无答案,则返回空字符串。
示例 1:
输入:
words = [“w”,“wo”,“wor”,“worl”, “world”]
输出: “world”
解释:
单词”world”可由”w”, “wo”, “wor”, 和 “worl”添加一个字母组成。
示例 2:
输入:
words = [“a”, “banana”, “app”, “appl”, “ap”, “apply”, “apple”]
输出: “apple”
解释:
“apply”和”apple”都能由词典中的单词组成。但是”apple”得字典序小于”apply”。
注意:
- 所有输入的字符串都只包含小写字母。
- words数组长度范围为[1,1000]。
- words[i]的长度范围为[1,30]。
代码实现:
Python:
第一种。排序
如果你在面试的时候遇到这个笔试题,建议用这个方法。
简单描述就是先对words进行排序,建议按照长度排序,这样可以减少不少计算量,如果按照ASCii字符排序.开销会比较大。
然后定义一个集合s和一个字符串对象res。
遍历排序后的words,对于每一个单词w,如果满足如下两个条件的就将其添加到s中:
- 长度是1;
-
w去掉最后一个字符后形成的子串在s中存在;
因为words中可能有重复的字符串,所以我们s定义为集合,就是为了去重。
如果w可以添加到s中,就说明w是有可能作为满足题目条件的字符串被返回的。具体哪个单词可以返回,我们可以根据下面两个条件来筛选:
如果w比上一个潜在字符串长(上一个潜在字符串存储在res中); - 如果w和res一样长,按照字符顺序比较两个字符串;
- 随着遍历结束,res中保存的一定是字母序列最小的最长单词。
这里注意一个小细节,可以大大影响程序性能,题目对words的限制条件是,每个字符串的长度都不超过30,但是words可能有1000个字符串。所以我们在遍历排序后的words,如果长度超过30,可以直接忽略掉,因为一定不满足条件。
C++:
bool m_RiseSort(string &a, string &b)
{
return a.length() < b.length();
}
class Solution {
public:
string longestWord(vector<string>& words) {
//对数组排序,再利用Set对字母存储,小的单词一定包含在后面大的单词里面。后面只需要取前缀相同的
//对字母排序后,第一个单词一定是共有的,后面只需在此基础上添加
sort(words.begin(), words.end(), m_RiseSort);
Set<String> set = new HashSet<>();
String res = "";
for (String s : words) {
//如果单词只有一个字母,那一定是共有的
if (s.length() == 1 || set.contains(s.substring(0, s.length() - 1))) {
res = s.length() > res.length() ? s : res;
set.add(s);
}
}
return res;
}
};
Python:
class Solution(object):
def longestWord(self, words):
"""
:type words: List[str]
:rtype: str
"""
wds = sorted(words, key=lambda x:len(x))
s = set()
res = ''
for w in wds:
if len(w) > 30:
break
if len(w)==1 or w[:-1] in s:
#if len(w)==len(wds[0]) or w[:-1] in s:
if len(w) > len(res) or w < res:
res = w
s.add(w)
return res
第二种、前缀树(Tire tree)
其实这道题是一个典型的关于前缀树的题。实现起来会有些复杂,不建议笔试的时候这样做。
对于树的节点Node,我们定义如下:

LeetCode基础算法题第137篇:找出字典中字母序列最小的最长单词
它包含一个char类型字符。存储分拆的字符;一个Node指针数组children,存储接下来的Node节点(如果存在的话),其长度是26,对于26个小写字母;另外还有一个字符串str,如果当前字符是单词w的最后一个字符,那么str会赋值为w。
Node形象化的描述,见后面的图示。
next指针以及AllocedNode会在后面描述。
我们可以定义一个空节点作为前缀树的根节点,然后对于words中的每一个单词字符串w,分拆成一个个字符,按顺序添加到前缀树中。
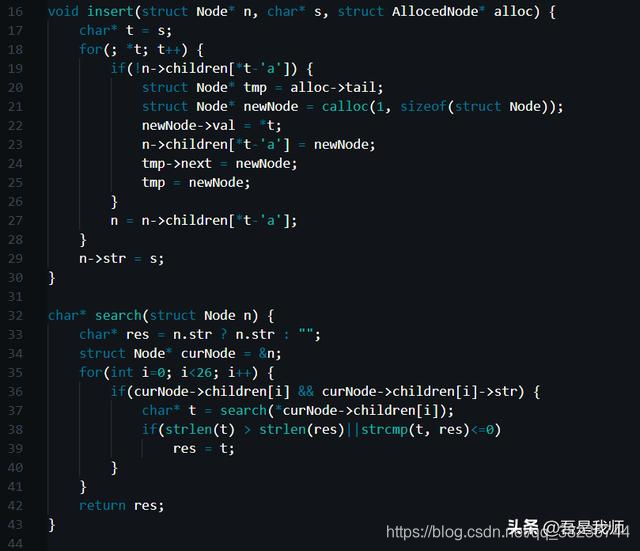
前缀树的插入和搜索函数定义如下:
LeetCode基础算法题第137篇:找出字典中字母序列最小的最长单词
在insert函数中,从前缀树的根节点开始,对单词s顺序遍历:
代码21~23行,如果,当前字符在树中的相遇位置节点为空,那么创建一个新的节点,完成赋值后添加到树中这个位置,同时,该新节点将作为一个新的起始位置开始遍历下一个字符;
代码27行,如果当前字符在树中的相应位置节点存在,那么该节点会作为新的起始位置开始遍历下一个字符;
代码29行,如果当前字符是单词的最后一个字符,或者说当前单词遍历结束,那么对赋值当前节点的str为当前单词,这个上面说过了。
我们会注意到,如果一个节点str是空的,说明在words中不存在以该节点作为结尾字符的单词,所以在查找的时候,遇到这样的节点,就没必要继续查找了。
插入的示图如下 (其中绿色表示新建Node节点,橙色表示对已有节点str值的更新):

LeetCode基础算法题第137篇:找出字典中字母序列最小的最长单词
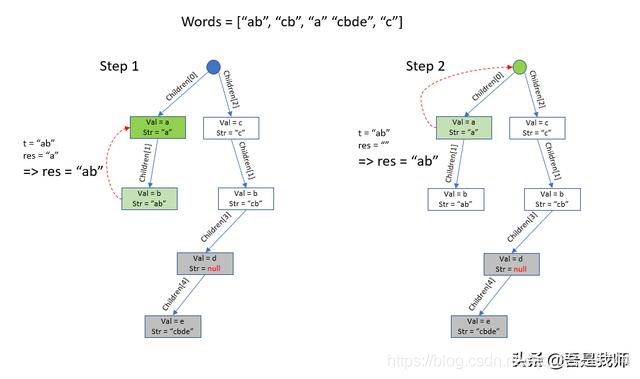
在search函数中,从树的节点n开始对其进行深度优先遍历,我们是用递归的方式来实现的。对于每一个节点,我们先定义一个变量res,初始为当前节点的str,如果str为空,则初始化为空字符串。
然后遍历它的所有的孩子数组children,如果某一个孩子是非空的且孩子的str也非空,那就递归调用search找到该孩子下面存储的最大的str,返回给t,然后比较t和res以确定哪个更应该作为返回的字符串。
如果你观察递归的回溯过程,你可能会觉得,t和res的比较好像有些多余,因为深度越大的元素,str往往比深度小的元素的str要长,但是其实比较是不可缺少的,因为在当前子树中它是最长的,不代表它在树的所有子树中都是最长的。
搜索的示图如下(红色虚线表示递归回溯的过程):

在给定的接口函数longestWord中:
代码48,49行,我们先定义一个前缀树节点,memset很重要。
代码51,52行,完成前缀树的构建。
代码54。从根节点开始,查找整个树,找到符合条件的字符串。