关键词提取























代码实现:
#encoding:utf-8
import jieba
import re
import os
import numpy as np
class MyTfIdf:
def __init__(self):
#语料库中所有文档的每个词的词频 的统计
'''
{文档id1:{'乔布斯':0.333,...},
文档id2 :{‘苹果’:0.666,...}}
'''
self.tfs= {}
#语料库的词典
self.termset = set()
# 语料库的词典的每个词放入tf-idf值
self.idfs ={ } #{'乔布斯':0.333,...}
#语料库中所有文档的每个词的tfidf的值
self.tfidfs = { }
def add(self, docid, content):
#1.分词
document =jieba.lcut(content)
#预料库词典
# 停用词过滤
#停用词过滤
#停用词词典,语料库的词典-停用词词典
self.termset.update(document)
#tf计算
tfDic =self.ca_tf(document)
self.tfs.update({docid:tfDic})
#单篇文档每个词的词频统计
def cal_tf(self,document):
#{'乔布斯':0.333,...}
tfDic ={ }
#计算公式:在该文档的出现的次数/该文档的总词数
total = len(document)
for term in document:
count = document.count(term)
tf =count/total
tfDic.update({term.tf})
return tfDic
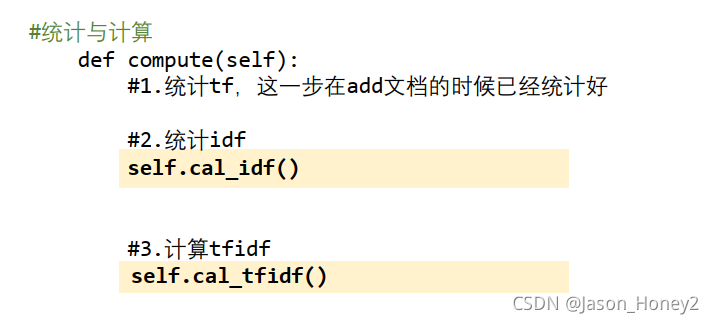
def compute(self):
#0.统计tf,这一步在add时已经实现 所以不再用统计
#1.统计idf
self.cal_idf()
#2.计算tf-idf
self.cal_tfidf()
#统计预料库词典的没一个词的倒文档频率
#公式:log(文档总数)/(包含该次数 +1)
def cal_idf(self):
#遍历词典中每个词进行统计
tfvalues =self.tfs.values()
#文档总数
total = len(tfvalues)
for term in self.termset:
count =1
for tfDic in tfvalues:
words = tfDic.key()#每篇文档的所有词
#判断当前的词是不是在文档中,如果在,次数+1
if term in words:
count += 1
idf = np.lpg(total/count)
# {'乔布斯':0.333,...}
self.idfs.update({term:idf})
#计算每篇文档的每个词的tf-idf
#公式:tf*idf
#tfidfs:文档id1:{'乔布斯':0.333,...},文档id2 :{‘苹果’:0.666,...}
def cal_tfidf(self):
for docid, tfDic in self.tfs.items():
#当前文档的所有词
terms = tfDic.keys()
#每篇文章的每个词的tf-idf
tfidfDic= {}
for term in terms:
tf = tfDic.get(term)
idf = self.idfs.get(term)
tfidf = tf*idf
tfidfDic.update({term:tfidf})
#将当前文档的计算结果添加进语料库的字典中
self.tfidfs.update({docid:tfidfDic})
#提取当前topN关键词
def getKeywordsOf(self, docid, topN):
#1该文档的tfidf获取出来
tfidfDic = self.tfidfs.get(docid)
#2.排序
tfidfDic_sorted =dict(sorted(tfidfDic.items(),key = lambda x:x[1],reverse =True))
#3.取前topN个关键词
keywords = tfidfDic_sorted.keys()[:topN]
return keywords
#文档向量化:使用前topN个关键词的tfidf表示
def genDocVect(self, topN):
#{文档id1:[..],文档id2:[]}
docVects = {}
docids = self.tfidfs.keys()
for docid in docids:
#获取前topN关键词
keywords =self.getKeywordsOf(docid,topN)
# 获取前topN个关键词的tfidf
docVect = [self.tfidfs.get(docid).get(term) for term in keywords]
docVects.update({docid:docVect})
return docVects
#加载文件
@staticmethod
def load_data(filepath):
with open(filepath, "r", encoding="gbk") as fin:
content = fin.read()
return re.sub(r'[\n]', '', content)
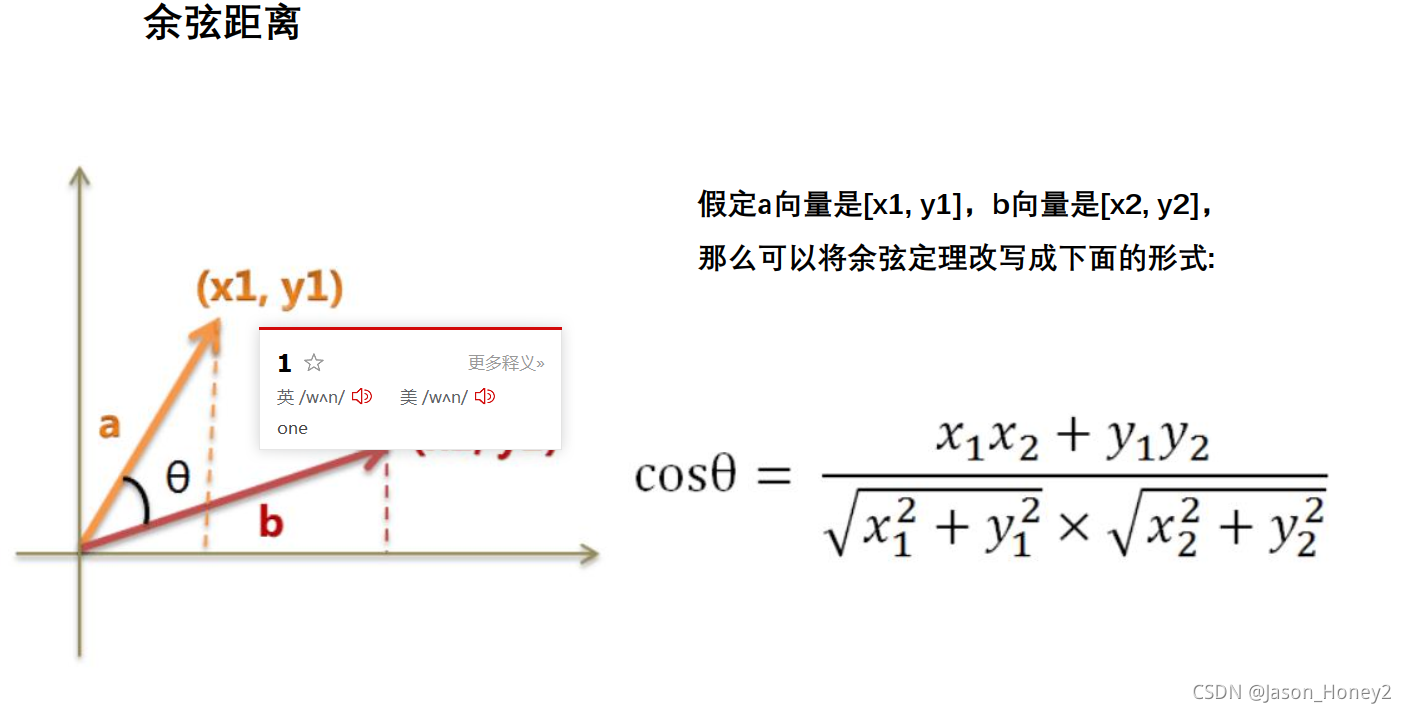
#余弦相似度计算
@staticmethod
def cosinsim(vect1,vect2):
vect1 = np.array(vect1)
vect2 = np.array(vect2)
#A*B/|A|*|B|
sim = np.dot(vect1,vect2)/(np.linalg.norm(vect1)*np.linalg)
return sim
if __name__ == '__main__':
dirName ='E:\\data'
counter = MyTfIdf()
for filename in os.listdir(dirName):
#文件名作为docid
docid = re.sub(r'\.txt','',filename)
print(docid)
# print(filename)
#文件路径
filepath = os.path.join(dirName,filename)
content = counter.load_data(filepath)
counter.add(docid,content)
#统计与计算:
counter.compute()
topN =10
docid ='3049012'
keywords = counter.getKeywordsOf(docid ,topN)
print(counter.idfs)
#文章相似度的应用
#获取语料库中所有文档的文本向量
documentVects =counter.genDocVect(topN)
docid1 ='30490132'
docid2 ='30490251'
vect1 =documentVects.get(docid1)
vect2 = documentVects.get(docid2)
#计算相似度
sim = counter.cosinsim(vect1,vect2)
print(sim)
#每个词作为特征
#使用预料库的词典为构建向量4000个词
#每个文章的维度:len(词典)=4000
#预料库的词典:[word1,word2,word3...]
#文章1:[doc1-word1-tfidf,doc1-word2-tfidf,word3...]
# 文章2:[doc1-word1-tfidf,doc1-word2-tfidf,word3...]
#方式二:关键词来向量化
#神经网络:提取词
# re.findall(r'(\d+)\.',filename[0])
# filename.split(".")[0]
# '30490114'
# counter.tfs.get('30490114')
# len(counter.idfs)
# 4630
#
# a = ['a':1,'b':2]
# a.keys()
# dict_keys(['a','b'])
#
# a = ['a':1,'b':2]
# a = ['b':1,'a':2]
# b=sorted(a.items(),key = lambda x:x[1],reverse =True) #forx in a.items()
# b
# [('a',2),('b',1)]
# dict(b)
# {'a':2,'b':1}
#
TF-IDF其他的三种方式的实现
第一种:
#python 实现TF-IDF
#-*- coding:utf-8 -*-
from collections import defaultdict
import math
import operator
"""
函数说明:创建数据样本
Returns:
dataset - 实验样本切分的词条
classVec - 类别标签向量
"""
def loadDataSet():
dataset = [ ['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], # 切分的词条
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid'] ]
classVec = [0,1,0,1,0,1] #类别标签向量,1代表好,0表示不好
return dataset,classVec
"""
函数说明:特征选择TF-IDF算法
Parameters:
list_words:词列表
Returns:
dict_feature_select:特征选择词字典
"""
#总词频统计
def feature_select(list_words):
doc_frequency = defaultdict(int)
for world_list in list_words:
for i in world_list:
doc_frequency[i]+=1
#计算每个词的TF值
word_tf={ } #存储每个词的tf值
for i in doc_frequency:
word_tf[i] = doc_frequency[i]/sum(doc_frequency.values())
#计算每个词的IDF值
doc_num =len(list_words)
word_idf={} #存储每个词的idf值
word_doc = defaultdict(int) #存储包含该词的文档数
for i in doc_frequency:
for j in list_words:
if i in j:
word_doc[i]+=1
for i in doc_frequency:
word_idf[i] = math.log(doc_num/(word_doc[i]+1))
#计算每个词的TF*IDF的值
word_tf_idf = {}
for i in doc_frequency:
word_tf_idf[i] = word_tf[i] * word_idf[i]
#对字典值按照从大到小的排序
dict_feature_select = sorted(word_tf_idf.items() ,key = operator.itemgetter(1),reverse =True)
return dict_feature_select
if __name__ =='__main__':
data_list,label_list = loadDataSet() #加载数据
features = feature_select(data_list)#所有词的TF-IDF值
print(features)
printt(len(features))
第二种实现方法–NLTK实现TF-IDF算法
#######d第二种实现方法--NLTK实现TF-IDF算法
from nltk.text import TextCollection
from nltk.tokenize import word_tokenize
#首先构建语料库corpus
sents = ['this is sentence one','this is sentence two','this is sentence three']
sents = [word_tokenize(sent) for sent in sents]#对每个句子进行分词
print(sents) #输出分词的结果
corpus = TextCollection(sents) #构建语料库
#计算语料库中“one”的tf值
tf = corpus.tf('one',corpus) #1/12
print(tf)
#计算语料库中”one"的idf的值
idf = corpus.idf('one') #log(3/1)
print(idf)
#计算语料库中“one"的tf-idf值
tf_idf = corpus.tf_idf('one',corpus)
print(tf_idf)
问题解决参考:https://blog.csdn.net/weixin_39712314/article/details/106173356
第三种方法:Sklearn实现TF-IDF算法
################Sklearn实现TF-IDF算法####################
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
x_train =['TF-IDF 主要 思想 是','算法 一个 重要 特点 可以 脱离 语料库 背景',
'如果 一个 网页 被 很多 其他 网页 链接 说明 网页 重要']
x_test = ['原始 文本 进行 标记','主要 思想']
#该类会将文本中的词语装换为词频矩阵,矩阵元素a[i][j]表示j词在i类文本下的词频
vectorizer = CountVectorizer(max_features =10)
#该类会统计每个词语的tf-idf权值
tf_idf_transformer =TfidfTransformer()
#将文本转换为词频矩阵并计算tf-idf
tf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train))
#将tf-idf的矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
x_train_weight = tf_idf.toarray()
#对测试集进行tf-idf权重计算
tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test))
x_test_weight = tf_idf.toarray() #测试集TF-IDF权重矩阵
print('输出x_train文本向量')
print(x_train_weight)
print('输出x_test文本向量:')
print(x_test_weight)
"""
输出x_train文本向量
[[0.70710678 0. 0.70710678 0. 0. 0.
0. 0. 0. 0. ]
[0. 0.3349067 0. 0.44036207 0. 0.44036207
0.44036207 0.44036207 0. 0.3349067 ]
[0. 0.22769009 0. 0. 0.89815533 0.
0. 0. 0.29938511 0.22769009]]
输出x_test文本向量:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]]
Process finished with exit code 0
第四种方法:Jieba实现TF-IDF算法
#######Jieba实现TF-IDF算法########
# import jieba.analyse
# text='关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作'
#
# keywords = jieba.analyse.extract_tags(text,topK= 5,withWeight = False ,allowPOS=())
# print(keywords)
'''
['文档', '文本', '关键词', '挖掘', '文本检索']
'''
版权声明:本文为Jason_Honey2原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。