小编在这里使用的是ANSYS Fluent 16.0,各个版本相差不大,希望可以对读者大大们有所帮助。
我们启动Fluent时,会率先出现启动界面,如下:
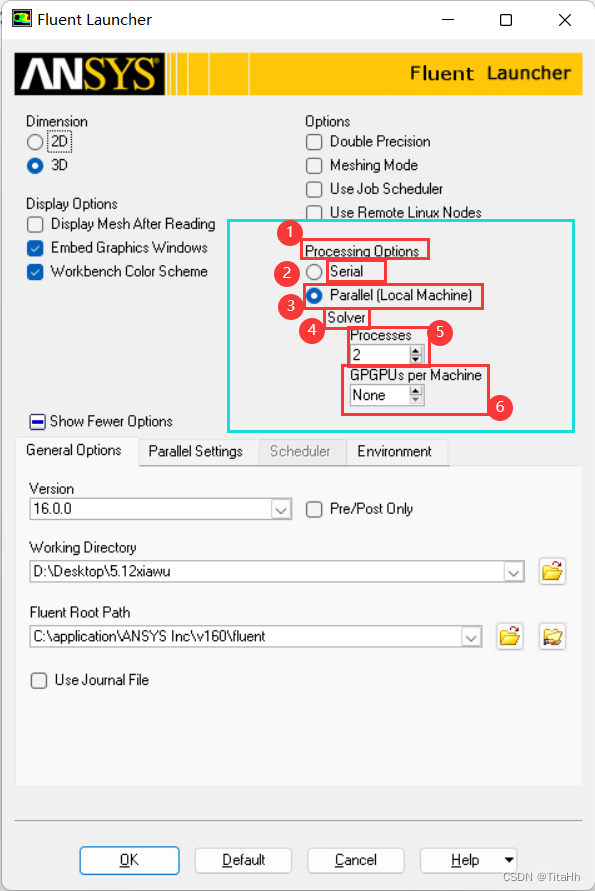
1.处理选项 2.串行
3.并行(本地机器) 4.解算器
5.进程 6.每台机器的GPU
按照小编的理解,选择串行之后就不用再做其他的设置,但是计算速度会有所减慢,选择并行能够提升计算速度,相应的就会进行以下设置:
1.Processes——代表线程
这个是代表你所用的电脑CPU的线程数,而不是电脑CPU的核数,就比如intel i7 12700是12核20线程的CPU,我们要采用的就是20,但是可能你电脑上的Fluent不能识别所有的线程,所以这就需要我们找到Fluent能够识别的线程数。
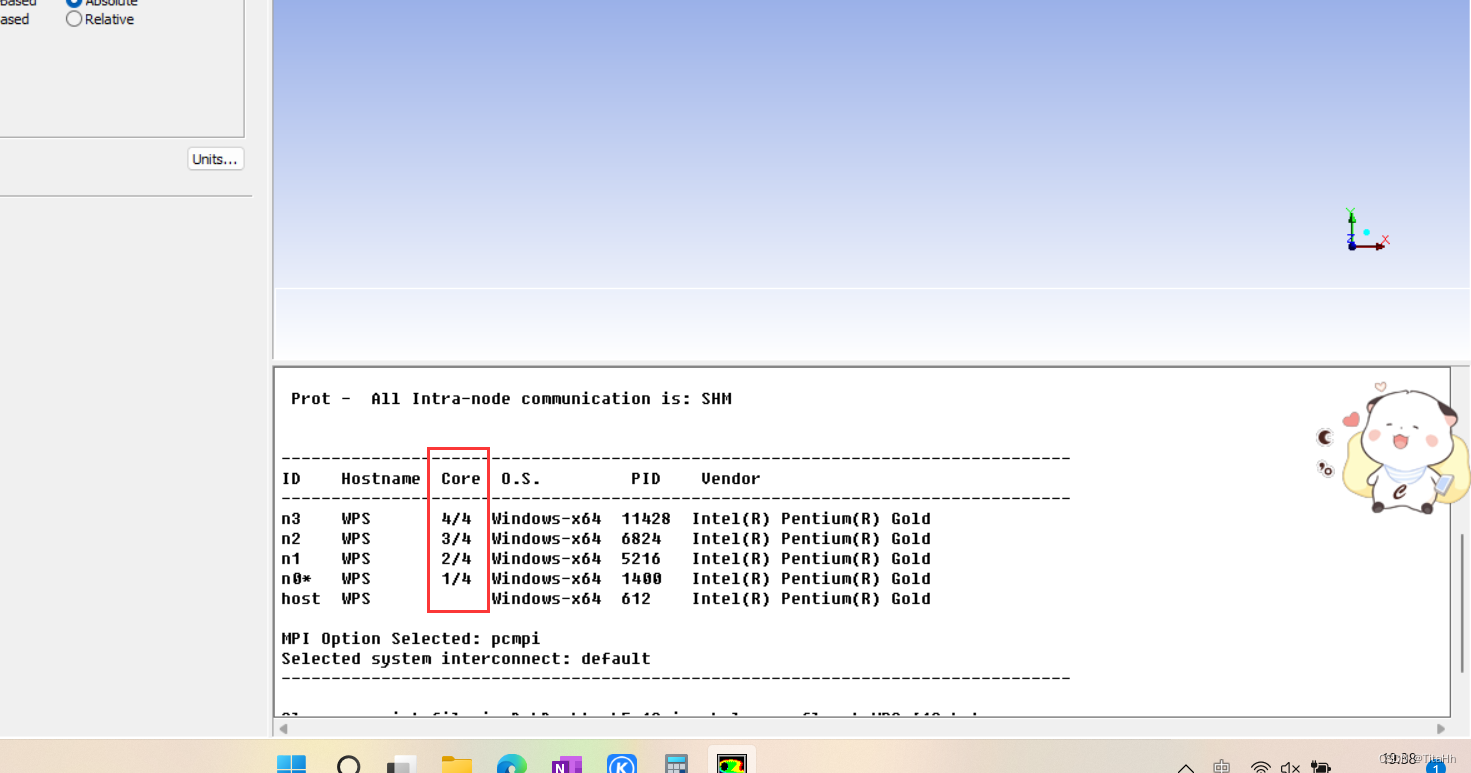
找线程数的方法也很简单,打开Fluent之后,等Fluent初始化完成,在现房的代码栏中就会找到1/n、2/n、3/n、4/n等的字样,如图,这其中的n就代表Fluent在你电脑上能识别的线程数,也是在Fluent启动界面Process输入框中所能输入的最大数。
2.GPUPUS per machine——代表GPU加速
Fluent在GPU上运行最高能将运行速度提高3.7倍,可以大幅度缩短计算时间。但是要使用GPU加速就需要使用专门的计算卡,比如NVIDA的Quuadro/Tesla系列显卡。
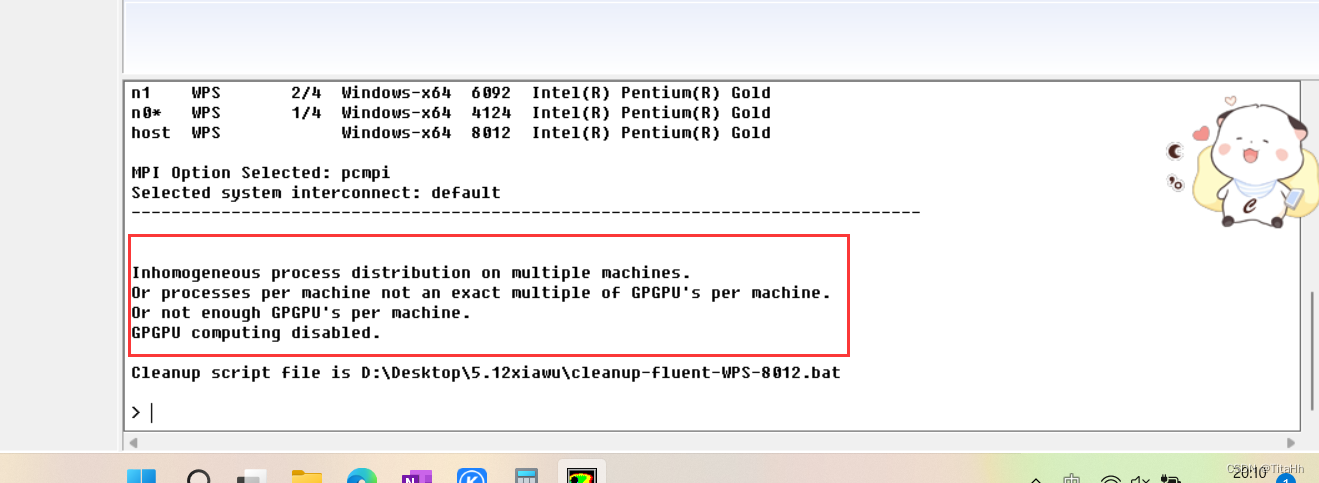
如果你使用了GPU加速,在初始化完成后出现这一系列错误,则说明你的GPU并不能用来加速。
启用 GPU 加速功能后,可以使用该功能执行有关线性系统(最多含有 5 个耦合方程)的 AMG 计算,而且计算需求随着域中的单元格数量增加而增长。
如果问题包含的单元格少于数百万个,则由于与 CPU 双向传递矩阵会产生通信开销,GPU 并不能加速求解此类问题。
但是,对于包含数千万和数亿个单元格的网格,由于通信开销与 AMG 求解器中的计算时间相比较小,加速效果会很显著。
耦合求解器从 GPU 中受益最多。在仅限流动的问题中,耦合求解器通常花费大约 60% 到 70% 的时间使用 AMG 来求解线性系统,因此选用 GPU 很合适。
分离式求解器仅花费 30% 到 40% 的时间来执行 AMG 计算,这样一来,GPU 可能会因显存传输开销的缘故而显不出优势。
默认情况下,GPU 加速自动应用到耦合系统而不应用到标量系统,原因是标量系统的计算开销通常没有耦合系统那么高。但是,如果需要,您可以使用以下文本命令为耦合系统和标量系统启用/禁用 AMG 求解器的 GPGPU 加速功能,以及列出支持的每种方程类型(允许您启用/禁用 GPGPU 加速、在 AMG 和 FGMRES 求解器之间选择和指定不同的求解器选项)。
/solve/set/amg-options/amg-gpgpu-options/
另外,在以下情况下将不会使用 GPU 加速:
- 群体平衡模型处于活动状态。
- 欧拉多相模型处于活动状态。
- 系统含有超过 5 个的耦合方程。