特征词提取常见算法
———-无监督———-
1.TF-IDF
重要性=每个单词的词频TF * 逆文档频率IDF。
思想:如果单词或短语在一篇文章中出现频率更高(TF值高)而在其他文章中出现少(DF值低,IDF值高),则认为该词或短语可以很好地代表文章,并可以用于分类。
2.TextRank
基于PageRank,该算法认为,如果在Page B中有指向Page A的链接,则Page B会投票给Page A,为了计算Page A的PageRank值,我们需要知道哪些page会投票给Page A。同时,PageRank值也会被投票page的质量影响。当一些高质量的页面投票给Page A,A的PR值就会上升,反之下降。
候选词的重要性根据它和其他候选词的关系来确定。将文本划分为几个组成单元(单词,短语,句子),并通过组成单元之间的相邻关系(共现关系)构建图模型。 节点的入口节点集代表其投票支持者的数量。 选民越多,权重越高,被投票节点的权重就越高。
可以结合位置加权等
3.基于LDA的关键词提取
LDA的训练,可以的得到一篇文章的主题分布p(z|di),和文章中词的主题分布p(z|wi),可以通过余弦相似度或者KL散度来计算这两个分布的相似性。如果文章的某一主题z的概率很大,而该文章中某个词对于该主题z也拥有更大的概率,那么该词就会有非常大的概率成为关键词。在gensim里,使用的方法是:候选的关键词与抽取的主题计算相似度并进行排序,得到最终的关键词。
————————-
4.Word2vec
候选词对应的词向量,对词向量进行聚类,距离聚类中心点最近的向量为关键词。
5.基于语义的关键词提取(SKE)
得分由三部分组成:1、居间度密度Vd;2、词性pos(名词、动词……), 位置loc(标题,段首,段尾),词长;3、TF-IDF值;对1、2、3加权得到最后的词语关键度得分。居间度密度为这篇论文提出的特征。
6.TPR
LDA + TextRank
TPR的思想是每个主题单独运行各自的带偏好的TextRank,每个主题的TextRank都会偏好与主题有较大相关度的词,这个偏好就是设置随机跳转的概率来得到的。
资料补充:
https://zhuanlan.zhihu.com/p/61666342
论文1:融合主题词嵌入和网络结构分析的主题关键词提取方法
主要方法:利用LDA主题模型进行初步提取,利用Word2Vec训练词向量,利用词向量相似度传播构建关键词网络,利用网络结构分析方法对主题词进行二次提取。
论文2:基于改进TF-PDF算法的地震微博热门主题词提取研究
主要方法:分词——>依据权值对候选主题词进行排序(主题特征项的权值由发布微博的博主影响力以及微博的关注度确定)——>获得地震信息的热门主题词
传统的TF-PDF算法侧重于计算微博信息中的热点词语,仅是对词语出现频率进行分析,对于发布微博的博主、每条微博的转发数等未加以考虑。
即该方法
添加了微博影响力的计算
。
论文3:基于TF
PDF的热点关键短语提取
在TF
PDF的基础上,
添加了位置权值
(在标题的词语权值更大),通过计算脉冲值过滤列表中的噪声(一些词汇长期在新闻报道中频繁出现且分布不会发生变化)
论文4:基于LDA耦合空间模型的作文跑题检测方法
LDA主题词提取

论文5:Automatic Keyword Extraction Using TextRank
结合了基于TextRank的启发式方法和嵌入式单词表示法
,此外,还
考虑了提取关键词的句子的重要性
。句子重要度分数最初是根据句子级别的TextRank算法得出。单词级加权TextRank模型中的初始边缘权重将通过其相应的句子分数进一步调整。
在该图中,所提出的算法包括:A)句子分数计算; B)关键字分数计算。 第一阶段在句子级别应用TextRank算法,得出每个句子的重要性得分。 在第二阶段中,在单词级别上实现了TextRank算法的一种变体,并将其与嵌入式单词表示形式相结合。 在计算第二个短语中的单词分数时,会考虑第一个短语的句子分数。 最后,将与最高分相关的单词作为提取的关键字进行检索。
论文6:Automatic query-based keyword and keyphrase extraction
基于用户查询——通过应用文档相似度度量,用向量空间模型算出每个文档和查询之间的相似度得分,选k个得分最高的k个文档——用RAKE提取每个文档的关键词和关键短语——重新计算分数(会结合文档分数)
论文7:Keyword Extraction Method for Complex Nodes Based on TextRank Algorithm
结合TextRank和TF-IDF
步骤:文本预处理——过滤候选词——提取关键词
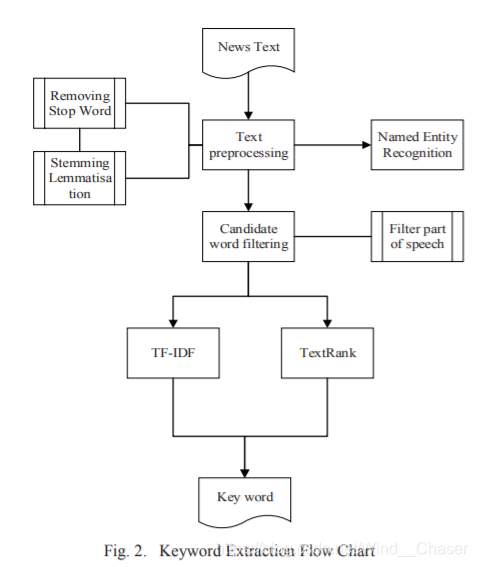
分别从新闻标题和文本提取。
论文8:Research on News Keyword Extraction Technology Based on TF-IDF and TextRank
—————–待补充—————–