本文首发于馆主君晓的博客,
在注意力空间下扰动的多样性生成
背景介绍
这是发布在
ICIP(International Conference Image Processing) 2022
会议上的一篇文章,作者是韩国科学技术研究院,论文原文:https://arxiv.org/abs/2208.05650。
我们知道在
2D
对抗攻击的领域,目前还能够做的就是提升
对抗攻击的迁移性
,也就是在
源模型中生成的对抗样本
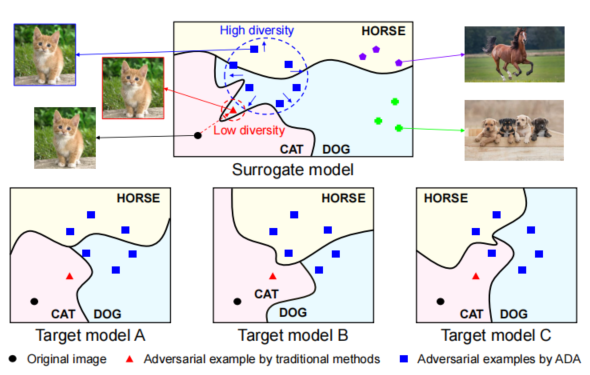
,对于其它模型而言同样具有攻击性,也就是能够让其它模型判断失误。但是目前的问题是,生成的对抗样本对于源模型而言,攻击成功率100%,但是对于黑盒模型而言,其攻击成功率就大打折扣。原因就是我们使用白盒模型生成的对抗样本过拟合了,就是生成的对抗样本过于拟合当前的模型,从而不具有较高的迁移性。作者在原文画了一幅图,我觉得形容的十分恰当。我们可以看到下面这张图,其中红色的部分是使用传统的对抗攻击方法生成的对抗样本。我们可以看到,对抗样本所处的位置在源模型上是能够使其给出错误的输出。但是在下面的
Target A
,
Target B
,
Target C
上,就能够被正确的分类。这张图,充分说明目前生成的对抗样本的缺点,对源模型过拟合。
在这篇文章当中,作者说之前的攻击大部分是基于梯度的攻击方式,这些攻击以一种确定的方式来生成对抗样本。在每一步的迭代过程中,他们以一种单一明确的方向来生成扰动,这样缺乏随机性,无法充分地搜寻整个空间。为了解决这个问题,作者提出了一种*ADA(Attentive Diversity Attack)*注意力多样性攻击的方法。也就是在特征空间上对模型显著关注的地方进行扰动,而且这种扰动是多样性的,之后我们会解释。
作者的Contributions
- 是第一个在特征层将随机性引入并且提高对抗攻击迁移性的。
-
提出了一种
ADA
对抗攻击方法,该方法能够能够以一种多样性的方式去扰动模型
attention
图像的部分,并且区别于以前基于梯度的那种确定的方式。 -
大量的实验证明,他们的方法比现有的
SOTA
方法好。
ADA方法介绍
首先简单介绍一下对抗攻击的目的,其实就是对输入图像做简单的修改,这样的修改对于人眼来说是微小的,不可见的,但是输入到模型中就能够让模型给出错误的输出。那么生成对抗样本就相当于优化下面的公式,最大化损失函数,取梯度上升的方向对输入进行修改。
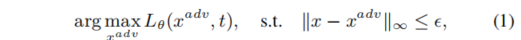
上面所说的这种方式容易对源模型过拟合,从而对抗样本的迁移性变低了,黑盒攻击的成功率上不去。现在我们来介绍作者的
ADA
方法。下面先给出一张概览图,之后的介绍会详细说明这个图。

Attack Generator
与传统的基于梯度方式的对抗攻击方法不同的是,对于扰动的生成,这里作者是专门训练了一个网络,来生成扰动的噪声。网络的输入就是
latent code
与我们源模型最后一层卷积输出的特征。生成对抗样本的公式如公式
2
所示。
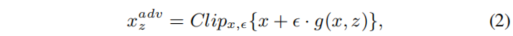
注意力空间上的扰动
我们都知道注意力机制,注意力其实就是一个权重,对于一个分类网络而言,其注意力就像上面的热力图一样,表示模型对某个部分比较关注,而正式由于模型对这个部分比较关注,最终才会有相应的预测结果。那换言之,如果我们使得模型关注的点不是正常的部分,那么就能够让模型输出错误。之所以在特征空间上去做扰动是因为我们的模型依赖于特征去做分类,那么在特征上去做扰动会更容易迁移到别的模型去。那么对于注意力的定义,作者给出了公式
3
。对于输入为
x
,实际目标为
t
的图像,其注意力
A
就等于权重
α
t
\alpha_{t}
α
t
乘以特征
F
。这里的特征,我们通常取最后一个卷积层的输出。而权重
α
t
\alpha_{t}
α
t
,则是通过
y
t
y_{t}
y
t
来求特征图的梯度,然后使用全局平均池化(每一个channel求平均值)求得的(假设求得的梯度是BxCxHxW,那么在全局平均池化之后就变成了BXC),为了防止全局平均池化后,有的值极小,有的值极大,这里对
channel
的结果做了归一化,使得生成器能够破坏每个不同的
feature map
。然后优化公式4即可,只需要最大化对抗样本的注意力空间与原始注意力空间的距离即可。
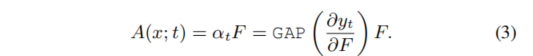
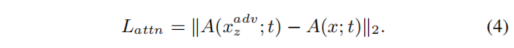
特征多样化
我们在上文中提到过,正是由于对抗样本对于源模型过拟合,所以才造成了对抗样本的迁移性不高。作者就想如果我们能够随机地去搜寻整个空间,那么我们生成的对抗样本的迁移性就会增加(其实这句话作者没说,我是根据作者文中的意思理解的)。那么这里作者在生成对抗噪声的网络的输入加入了
latent code
,隐码。为什么要加入这个呢?我们知道模型一旦训练好了,参数就是固定的,那么相同的输入得到相同的输出。因此如果我们想要有不同的输出,那么需要用到不同的输入,这里经过高斯分布采样的
latent code
是一个不错的选择。那么现在我们可以看公式5了,公式5就是想让给定两个不同
latent code
所形成的对抗样本之间的距离尽可能远。
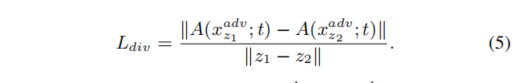
整体的损失函数
那么这样整体的损失函数就有了,一个是分类本身的损失,另外一个是注意力的损失,再一个是特征多样性损失。三个损失加在一起,我们生成噪声的目的就是最大化这个损失。其中注意力损失的权重系数是10,特征多样性损失的权重系数是1000,分类损失的权重系数是1。
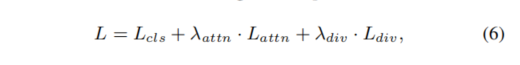
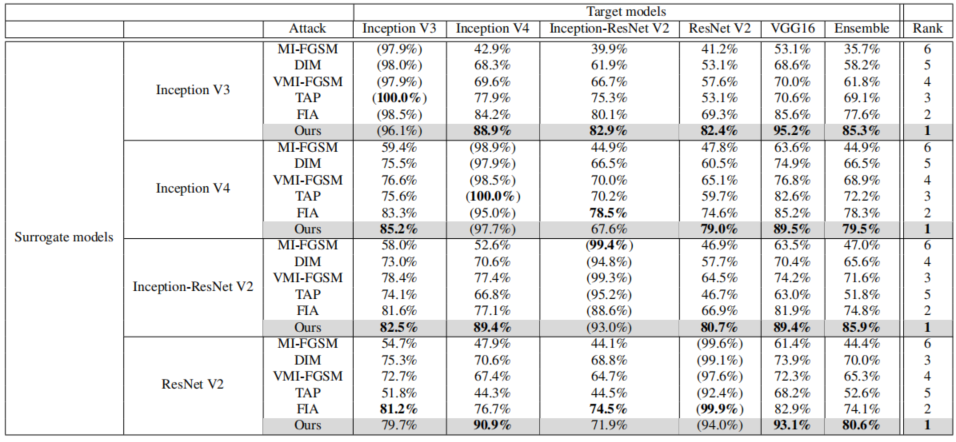
实验结果
下图中我们可以看到,作者提出的方法虽然在白盒攻击没有达到100%(主要是人家主攻迁移性,生成的对抗样本不过拟合白盒模型)。该方法虽然不说碾压其它的对抗攻击,但也很强了,与
FIA
做对比也丝毫不慌。关于
FIA
方法的介绍,在我之前的博客中有写,大家可以移步观看
基于特征感知的对抗攻击
。
代码
作者目前还没放出代码,但是作者说会在会议举行之前把代码给发布。关于实验的详细内容大家可以去看看原文,这里就不过多介绍了。总而言之感觉这篇论文的思路不错,效果也有。