一、问题描述

二、算法分析
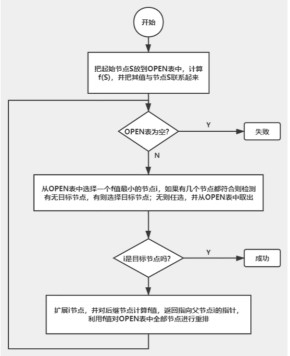
在搜索的每一步都利用估价函数 f(n)= g(n)+h(n)对 Open 表中的节点进行排序表中的节点进行排序, 找出一个最有希望的节点作为下一次扩展的节点。且满足条 件:h(n)≤h*(n)。其中 g(n) 是在状态空间中从初始状态到状态 n 的实际代价, h(n) 是从状态 n 到目标状态的最佳路径的估计代价。
算法过程如下:
读入初始状态和目标状态,并计算初始状态评价函数值 f;
初始化两个 open 表和 closed 表,将初始状态放入 open 表中
如果 open 表为空,则查找失败;
否则:
①在 open 表中找到评价值最小的节点,作为当前结点,并放入 closed 表中;
② 判断当前结点状态和目标状态是否一致,若一致,跳出循环;否则跳转到③;
③ 对当前结点,分别按照上、下、左、右方向移动空格位置来扩展新的状态结 点,并计算新扩展结点的评价值 f 并记录其父节点;
④ 对于新扩展的状态结点,进行如下操作: A.新节点既不在 open 表中,也不在 closed 表中,则添加进 OPEN 表; B.新节点在 open 表中,则计算评价函数的值,取最小的。 C.新节点在 closed 表中,则计算评价函数的值,取最小的。
⑤ 把当前结点从 open 表中移除;
三.深度优先算法:
(1)从图中某顶点 v 出发,访问顶点 v;
(2)依次从 v 的未被访问的邻接点出发,对图进行深度优先遍历;直至图中 和 v 有路径相通的顶点都被访问;
(3)若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行 深度优先遍历,直到图中所有顶点均被访问过为止。
A*算法
#-*-coding:utf-8-*-
import heapq
import copy
import time
import math
import argparse
# 初始状态
# S0 = [[11, 9, 4, 15],
# [1, 3, 0, 12],
# [7, 5, 8, 6],
# [13, 2, 10, 14]]
S0 = [[5, 1, 2, 4],
[9, 6, 3, 8],
[13, 15, 10, 11],
[0, 14, 7, 12]]
# 目标状态
SG = [[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 0]]
# 上下左右四个方向移动
MOVE = {'up': [1, 0],
'down': [-1, 0],
'left': [0, -1],
'right': [0, 1]}
# OPEN表
OPEN = []
# 节点的总数
SUM_NODE_NUM = 0
# 状态节点
class State(object):
def __init__(self, deepth=0, rest_dis=0.0, state=None, hash_value=None, father_node=None):
'''
初始化
:参数 deepth: 从初始节点到目前节点所经过的步数
:参数 rest_dis: 启发距离
:参数 state: 节点存储的状态 4*4的列表
:参数 hash_value: 哈希值,用于判重
:参数 father_node: 父节点指针
'''
self.deepth = deepth
self.rest_dis = rest_dis
self.fn = self.deepth + self.rest_dis
self.child = [] # 孩子节点
self.father_node = father_node # 父节点
self.state = state # 局面状态
self.hash_value = hash_value # 哈希值
def __lt__(self, other): # 用于堆的比较,返回距离最小的
return self.fn < other.fn
def __eq__(self, other): # 相等的判断
return self.hash_value == other.hash_value
def __ne__(self, other): # 不等的判断
return not self.__eq__(other)
def cal_M_distence(cur_state):
'''
计算曼哈顿距离
:参数 state: 当前状态,4*4的列表, State.state
:返回: M_cost 每一个节点计算后的曼哈顿距离总和
'''
M_cost = 0
for i in range(4):
for j in range(4):
if cur_state[i][j] == SG[i][j]:
continue
num = cur_state[i][j]
if num == 0:
x, y = 3, 3
else:
x = num / 4 # 理论横坐标
y = num - 4 * x - 1 # 理论的纵坐标
M_cost += (abs(x - i) + abs(y - j))
return M_cost
def cal_E_distence(cur_state):
'''
计算曼哈顿距离
:参数 state: 当前状态,4*4的列表, State.state
:返回: M_cost 每一个节点计算后的曼哈顿距离总和
'''
E_cost = 0
for i in range(4):
for j in range(4):
if cur_state[i][j] == SG[i][j]:
continue
num = cur_state[i][j]
if num == 0:
x, y = 3, 3
else:
x = num / 4 # 理论横坐标
y = num - 4 * x - 1 # 理论的纵坐标
E_cost += math.sqrt((x - i)*(x - i) + (y - j)*(y - j))
return E_cost
def generate_child(sn_node, sg_node, hash_set, open_table, cal_distence):
'''
生成子节点函数
:参数 sn_node: 当前节点
:参数 sg_node: 最终状态节点
:参数 hash_set: 哈希表,用于判重
:参数 open_table: OPEN表
:参数 cal_distence: 距离函数
:返回: None
'''
if sn_node == sg_node:
heapq.heappush(open_table, sg_node)
print('已找到终止状态!')
return
for i in range(0, 4):
for j in range(0, 4):
if sn_node.state[i][j] != 0:
continue
for d in ['up', 'down', 'left', 'right']: # 四个偏移方向
x = i + MOVE[d][0]
y = j + MOVE[d][1]
if x < 0 or x >= 4 or y < 0 or y >= 4: # 越界了
continue
state = copy.deepcopy(sn_node.state) # 复制父节点的状态
state[i][j], state[x][y] = state[x][y], state[i][j] # 交换位置
h = hash(str(state)) # 哈希时要先转换成字符串
if h in hash_set: # 重复了
continue
hash_set.add(h) # 加入哈希表
# 记录扩展节点的个数
global SUM_NODE_NUM
SUM_NODE_NUM += 1
deepth = sn_node.deepth + 1 # 已经走的距离函数
rest_dis = cal_distence(state) # 启发的距离函数
node = State(deepth, rest_dis, state, h, sn_node) # 新建节点
sn_node.child.append(node) # 加入到孩子队列
heapq.heappush(open_table, node) # 加入到堆中
# show_block(state, deepth) # 打印每一步的搜索过程
def show_block(block, step):
print("------", step, "--------")
for b in block:
print(b)
def print_path(node):
'''
输出路径
:参数 node: 最终的节点
:返回: None
'''
print("最终搜索路径为:")
steps = node.deepth
stack = [] # 模拟栈
while node.father_node is not None:
stack.append(node.state)
node = node.father_node
stack.append(node.state)
step = 0
while len(stack) != 0:
t = stack.pop()
show_block(t, step)
step += 1
return steps
def A_start(start, end, distance_fn, generate_child_fn):
'''
A*算法
:参数 start: 起始状态
:参数 end: 终止状态
:参数 distance_fn: 距离函数,可以使用自定义的
:参数 generate_child_fn: 产生孩子节点的函数
:返回: 最优路径长度
'''
root = State(0, 0, start, hash(str(S0)), None) # 根节点
end_state = State(0, 0, end, hash(str(SG)), None) # 最后的节点
if root == end_state:
print("start == end !")
OPEN.append(root)
heapq.heapify(OPEN)
node_hash_set = set() # 存储节点的哈希值
node_hash_set.add(root.hash_value)
while len(OPEN) != 0:
top = heapq.heappop(OPEN)
if top == end_state: # 结束后直接输出路径
return print_path(top)
# 产生孩子节点,孩子节点加入OPEN表
generate_child_fn(sn_node=top, sg_node=end_state, hash_set=node_hash_set,
open_table=OPEN, cal_distence=distance_fn)
print("无搜索路径!") # 没有路径
return -1
if __name__ == '__main__':
# 可配置式运行文件
parser = argparse.ArgumentParser(description='选择距离计算方法')
parser.add_argument('--method', '-m', help='method 选择距离计算方法(cal_E_distence or cal_M_distence)', default = 'cal_M_distence')
args = parser.parse_args()
method = args.method
time1 = time.time()
if method == 'cal_E_distence':
length = A_start(S0, SG, cal_E_distence, generate_child)
else:
length = A_start(S0, SG, cal_M_distence, generate_child)
time2 = time.time()
if length != -1:
if method == 'cal_E_distence':
print("采用欧式距离计算启发函数")
else:
print("采用曼哈顿距离计算启发函数")
print("搜索最优路径长度为", length)
print("搜索时长为", (time2 - time1), "s")
print("共检测节点数为", SUM_NODE_NUM)
深度优先:
#-*-coding:utf-8-*-
import copy
import time
# 初始状态
# S0 = [[11, 9, 4, 15],
# [1, 3, 0, 12],
# [7, 5, 8, 6],
# [13, 2, 10, 14]]
S0 = [[5, 1, 2, 4],
[9, 6, 3, 8],
[13, 15, 10, 11],
[0, 14, 7, 12]]
# 目标状态
SG = [[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 0]]
# 上下左右四个方向移动
MOVE = {'up': [1, 0],
'down': [-1, 0],
'left': [0, -1],
'right': [0, 1]}
# OPEN表
OPEN = []
# 节点的总数
SUM_NODE_NUM = 0
# 状态节点
class State(object):
def __init__(self, deepth=0, state=None, hash_value=None, father_node=None):
'''
初始化
:参数 deepth: gn是初始化到现在的距离
:参数 state: 节点存储的状态
:参数 hash_value: 哈希值,用于判重
:参数 father_node: 父节点指针
'''
self.deepth = deepth
self.child = [] # 孩子节点
self.father_node = father_node # 父节点
self.state = state # 局面状态
self.hash_value = hash_value # 哈希值
def __eq__(self, other): # 相等的判断
return self.hash_value == other.hash_value
def __ne__(self, other): # 不等的判断
return not self.__eq__(other)
def generate_child(sn_node, sg_node, hash_set):
'''
生成子节点函数
:参数 sn_node: 当前节点
:参数 sg_node: 最终状态节点
:参数 hash_set: 哈希表,用于判重
:参数 open_table: OPEN表
:返回: None
'''
for i in range(0, 4):
for j in range(0, 4):
if sn_node.state[i][j] != 0:
continue
for d in ['up', 'down', 'left', 'right']: # 四个偏移方向
x = i + MOVE[d][0]
y = j + MOVE[d][1]
if x < 0 or x >= 4 or y < 0 or y >= 4: # 越界了
continue
state = copy.deepcopy(sn_node.state) # 复制父节点的状态
state[i][j], state[x][y] = state[x][y], state[i][j] # 交换位置
h = hash(str(state)) # 哈希时要先转换成字符串
if h in hash_set: # 重复了
continue
hash_set.add(h) # 加入哈希表
# 记录扩展节点的个数
global SUM_NODE_NUM
SUM_NODE_NUM += 1
deepth = sn_node.deepth + 1 # 已经走的距离函数
node = State(deepth, state, h, sn_node) # 新建节点
sn_node.child.append(node) # 加入到孩子队列
OPEN.insert(0, node)
# show_block(state, deepth)
def show_block(block, step):
print("------", step, "--------")
for b in block:
print(b)
def print_path(node):
'''
输出路径
:参数 node: 最终的节点
:返回: None
'''
print("最终搜索路径为:")
steps = node.deepth
stack = [] # 模拟栈
while node.father_node is not None:
stack.append(node.state)
node = node.father_node
stack.append(node.state)
step = 0
while len(stack) != 0:
t = stack.pop()
show_block(t, step)
step += 1
return steps
def DFS_max_deepth(start, end, generate_child_fn, max_deepth):
'''
A*算法
:参数 start: 起始状态
:参数 end: 终止状态
:参数 generate_child_fn: 产生孩子节点的函数
:参数 max_deepth: 最深搜索深度
:返回: None
'''
root = State(0, start, hash(str(S0)), None) # 根节点
end_state = State(0, end, hash(str(SG)), None) # 最后的节点
if root == end_state:
print("start == end !")
OPEN.append(root)
node_hash_set = set() # 存储节点的哈希值
node_hash_set.add(root.hash_value)
while len(OPEN) != 0:
top = OPEN.pop(0)
if top == end_state: # 结束后直接输出路径
return print_path(top)
if top.deepth >= max_deepth:
continue
# 产生孩子节点,孩子节点加入OPEN表
generate_child_fn(sn_node=top, sg_node=end_state, hash_set=node_hash_set)
print("设置最深深度不合适,无搜索路径!") # 没有路径
return -1
if __name__ == '__main__':
time1 = time.time()
length = DFS_max_deepth(S0, SG, generate_child, 25)
time2 = time.time()
if length != -1:
print("搜索最优路径长度为", length)
print("搜索时长为", (time2 - time1), "s")
print("共检测节点数为", SUM_NODE_NUM)
广度优先
:
#-*-coding:utf-8-*-
import heapq
import copy
import time
# 初始状态
# S0 = [[11, 9, 4, 15],
# [1, 3, 0, 12],
# [7, 5, 8, 6],
# [13, 2, 10, 14]]
S0 = [[5, 1, 2, 4],
[9, 6, 3, 8],
[13, 15, 10, 11],
[0, 14, 7, 12]]
# 目标状态
SG = [[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 0]]
# 上下左右四个方向移动
MOVE = {'up': [1, 0],
'down': [-1, 0],
'left': [0, -1],
'right': [0, 1]}
# OPEN表
OPEN = []
# 节点的总数
SUM_NODE_NUM = 0
# 状态节点
class State(object):
def __init__(self, deepth=0, state=None, hash_value=None, father_node=None):
'''
初始化
:参数 deepth: 从初始节点到目前节点所经过的步数
:参数 state: 节点存储的状态 4*4的列表
:参数 hash_value: 哈希值,用于判重
:参数 father_node: 父节点指针
'''
self.deepth = deepth
self.child = [] # 孩子节点
self.father_node = father_node # 父节点
self.state = state # 局面状态
self.hash_value = hash_value # 哈希值
def __lt__(self, other): # 用于堆的比较,返回距离最小的
return self.deepth < other.deepth
def __eq__(self, other): # 相等的判断
return self.hash_value == other.hash_value
def __ne__(self, other): # 不等的判断
return not self.__eq__(other)
def generate_child(sn_node, sg_node, hash_set, open_table):
'''
生成子节点函数
:参数 sn_node: 当前节点
:参数 sg_node: 最终状态节点
:参数 hash_set: 哈希表,用于判重
:参数 open_table: OPEN表
:返回: None
'''
if sn_node == sg_node:
heapq.heappush(open_table, sg_node)
print('已找到终止状态!')
return
for i in range(0, 4):
for j in range(0, 4):
if sn_node.state[i][j] != 0:
continue
for d in ['up', 'down', 'left', 'right']: # 四个偏移方向
x = i + MOVE[d][0]
y = j + MOVE[d][1]
if x < 0 or x >= 4 or y < 0 or y >= 4: # 越界了
continue
state = copy.deepcopy(sn_node.state) # 复制父节点的状态
state[i][j], state[x][y] = state[x][y], state[i][j] # 交换位置
h = hash(str(state)) # 哈希时要先转换成字符串
if h in hash_set: # 重复了
continue
hash_set.add(h) # 加入哈希表
# 记录扩展节点的个数
global SUM_NODE_NUM
SUM_NODE_NUM += 1
deepth = sn_node.deepth + 1 # 已经走的距离函数
node = State(deepth, state, h, sn_node) # 新建节点
sn_node.child.append(node) # 加入到孩子队列
heapq.heappush(open_table, node) # 加入到堆中
# show_block(state, deepth) # 打印每一步的搜索过程
def show_block(block, step):
print("------", step, "--------")
for b in block:
print(b)
def print_path(node):
'''
输出路径
:参数 node: 最终的节点
:返回: None
'''
print("最终搜索路径为:")
steps = node.deepth
stack = [] # 模拟栈
while node.father_node is not None:
stack.append(node.state)
node = node.father_node
stack.append(node.state)
step = 0
while len(stack) != 0:
t = stack.pop()
show_block(t, step)
step += 1
return steps
def A_start(start, end, generate_child_fn):
'''
A*算法
:参数 start: 起始状态
:参数 end: 终止状态
:参数 generate_child_fn: 产生孩子节点的函数
:返回: 最优路径长度
'''
root = State(0, start, hash(str(S0)), None) # 根节点
end_state = State(0, end, hash(str(SG)), None) # 最后的节点
if root == end_state:
print("start == end !")
OPEN.append(root)
heapq.heapify(OPEN)
node_hash_set = set() # 存储节点的哈希值
node_hash_set.add(root.hash_value)
while len(OPEN) != 0:
top = heapq.heappop(OPEN)
if top == end_state: # 结束后直接输出路径
return print_path(top)
# 产生孩子节点,孩子节点加入OPEN表
generate_child_fn(sn_node=top, sg_node=end_state, hash_set=node_hash_set,
open_table=OPEN)
print("无搜索路径!") # 没有路径
return -1
if __name__ == '__main__':
time1 = time.time()
length = A_start(S0, SG, generate_child)
time2 = time.time()
if length != -1:
print("搜索最优路径长度为", length)
print("搜索时长为", (time2 - time1), "s")
print("共检测节点数为", SUM_NODE_NUM)
四.运行截图
五.总结
通过对比分析,可以发现,A 星算法的搜索时长和检测节点数明显小于深度优先方法,可见 启发式信息对于搜索过程的重要性;另外,有界深度优先算法的算法性能差异较大,设置不 同的最深深度得到的结果有一定的差异,一般设置较大会造成内存爆炸的现象,所以通过该 方法进行搜索较为困难,对于任务较为复杂的情况,很难快速求解。
另外,广度优先算法, 针对较为简单问题,基本可以以最短路径给出答案,但同时搜索时间和搜索节点数一定会比 启发式搜索多一些,针对复杂问题,很难给出答案,每扩展一层,都会以指数的形式增加待 扩展节点的数量,很难得出答案。
综上所述,与深度优先算法相比,启发式搜索算法有很强的优越性,一般情况下要尽可能去 寻找启发函数,添加到代码中辅助进行算法的训练,尽可能缩短程序运行时间,提高程序效 率。