本文记录一下从0入门Transformer的过程
https://zhuanlan.zhihu.com/p/31547842
Transformer之前
说到Transformer,就离不开NLP,就离不开Seq2Seq,毕竟transformer一开始也是和Seq2Seq结合用的。
RNN & NLP
这里先放两个RNN在NLP中的应用,了解一下RNN
RNN收到一个字母,输出更新的隐藏状态和预测的国家分类,到了最后一个字母之后,把国家分类拿出来得到最终的预测。这就是Sequence到一个类的任务。
RNN收到一个字母,输出更新的隐藏状态和预测下一个字母。直到输出终止符,将之前的所有字母合起来,就是最终生成的名字。这是一个状态到Sequence的任务
Seq2Seq
文章:
Sequence to Sequence Learning with Neural Networks
其实有了上面两个任务的基础,就理解Seq2Seq是怎么做的了。对输入Seq进行编码,把其中每个单词或者每个字母按顺序输入到RNN中,最终可以得到一个隐藏状态,这个RNN就叫Encoder。然后用这个隐藏状态输入到Decoder中,按照生成名字的方法依次输出预测的单词或者字母,生成输出的Seq。
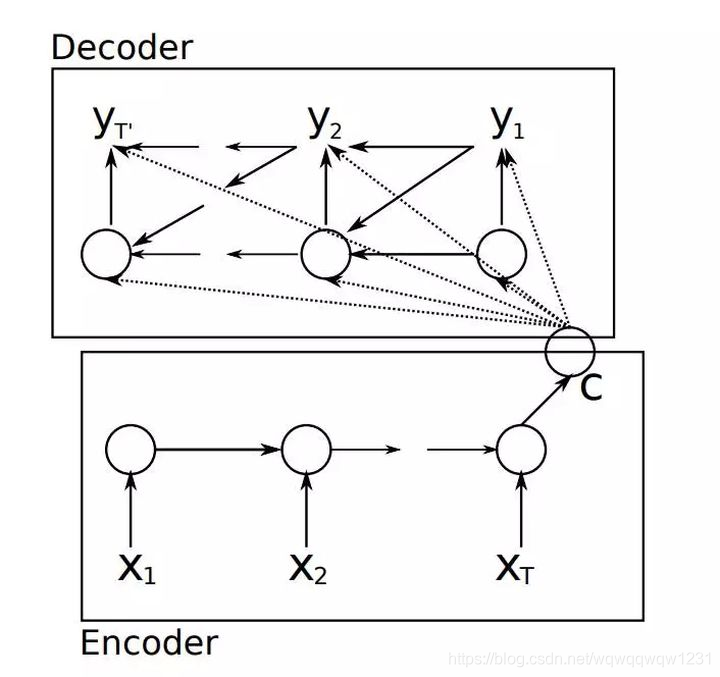
那么这就有个问题:从第一个词到最后一个词,走了这么久,隐藏状态到底能不能记得住这么多东西呢?能不能有效的找到输出Seq中第j个词到底和输入Seq中的哪个词关系比较大呢?
这就引出了Attention,目的就是学习输出Seq和输入Seq之间的关系,输出Seq不同位置的词是与输入Seq的某些词有关的,只需要关注这些词即可。
Seq2Seq + Attention
仍然是从代码入手,推荐
Pytorch的教程
。
先看Encoder:

这里说一下embedding,pytorch目前有nn.Embedding,可以把一个单词转为一个向量。GRU是一个标准结构,也有pytorch也有nn.GRU支持。
再看没有Attention的Decoder:

这基本就是Seq2Seq的网络。
加上Attention的Decoder
:

input是上一个词,prev_hidden是预测完上一个词的隐状态,然后用这两个计算一个attention的weight。encoder_outputs包含了encoder对输入的Seq的每个词的输出。用atten_weights乘上去之后得到对应输入Seq每个词的attention,然后与输入做结合,送入GRU。
Transformer
这里推荐一个
博客
,细细地把这个博客看了,Transformer就也算大致懂了。
先放个Transformer的总体框架图,那么Transformer就是有一堆Encoder和Decoder构成的:

Encoder

本文就按照计算顺序来讲。
1、word embedding
:有了word,需要产生一个vector进行描述,这个vector可以被叫做word embedding,再文章中使用512长度的vector
2、Position encoding
:每个词有不同的位置,那么就对这个位置编码,如下,对每个位置产生一个512长度的vector进行表示:

第一行就是位置1的编码,第二行就是位置2的编码。有了位置编码之后,可以相加或者concatenate到word embedding中去。
至此,就有了Encoder的输入
3、Self-Attention
:self-attention有很多博客都在讲,这里就给出一张图:
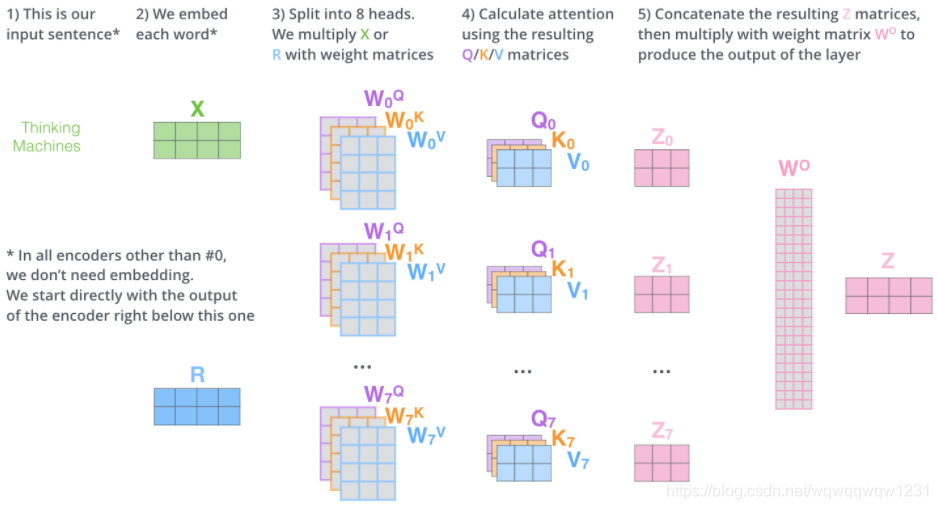
输入的语句包含两个词,经过步骤1和2可以对应的生成两个vector,我们把这两个vector并起来,就得到了X。然后经过multi-head self-attention,也就是其中的W,Q,Z,然后将multi-head得到的输出Z0-Z7再用一个矩阵合并起来,得到这个Self-Attention模块输出的Z。
4、feed forward neural network
:就是普通的前馈神经网络,MLP
Decoder
懂了Encoder,那Decoder其实也比较好懂
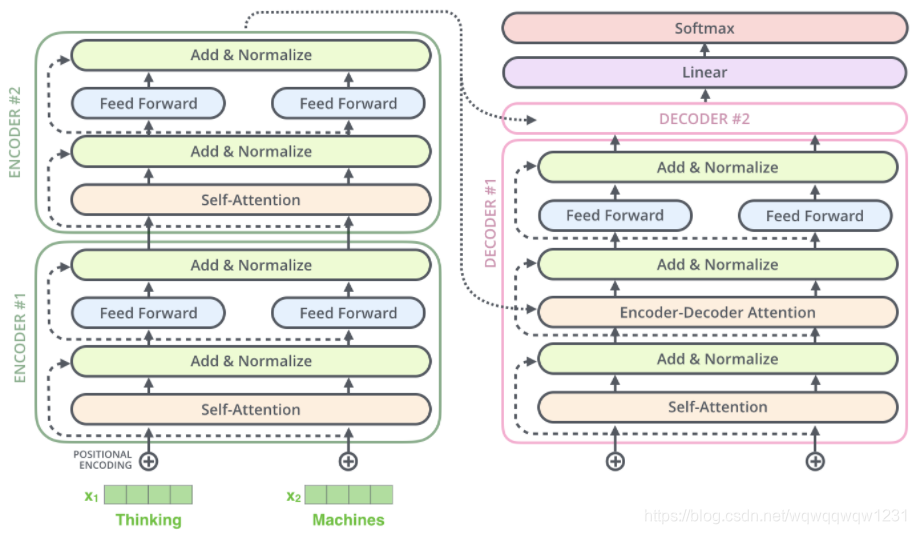
1、word embedding和position encoding
:上图中没有画出来,这部分的理解其实是和Seq2Seq是一样的,每一次循环预测出一个单词。第i次用Decoder,那Decoder的输入就是前i-1次预测的全部词,那么就需要对i-1个词做word embedding和position encoding得到输入向量
2、self-Attention
:就如同Encoder中的一样
3、Add & Normalize
:这个在之前没说,其实这个是把Encoder和Decoder内部做成了残差结构。Add就是单纯的相加,Normalize是做了Layer Normalization
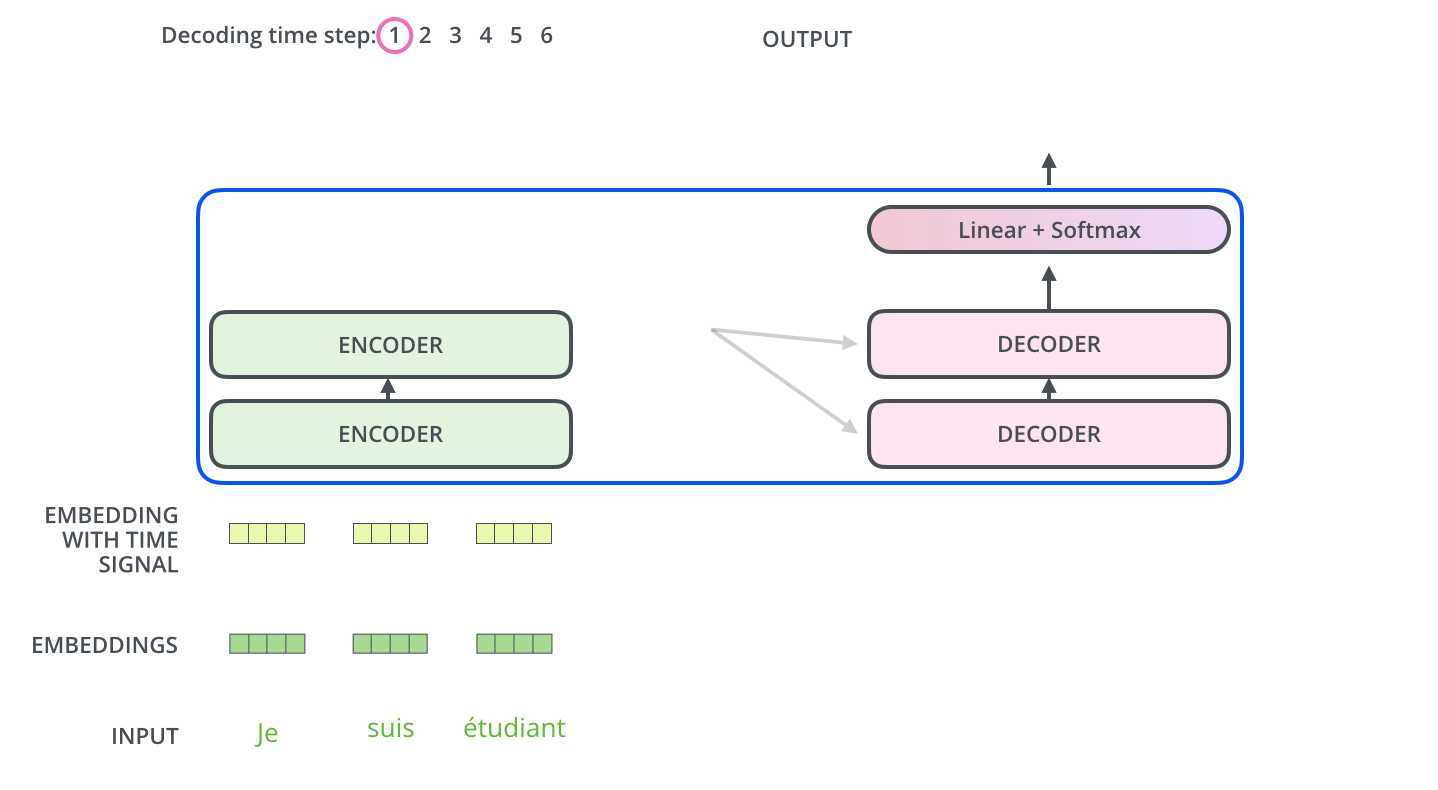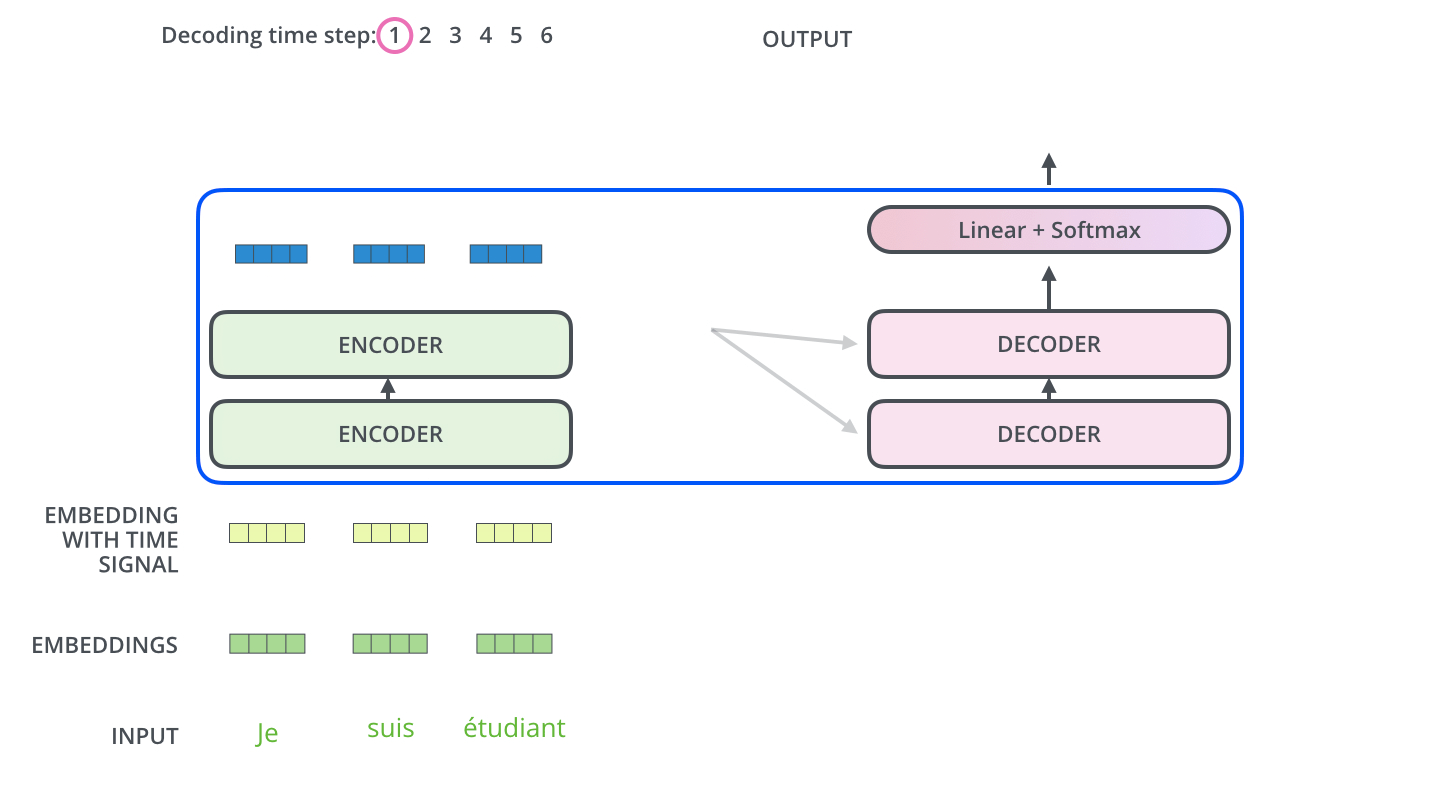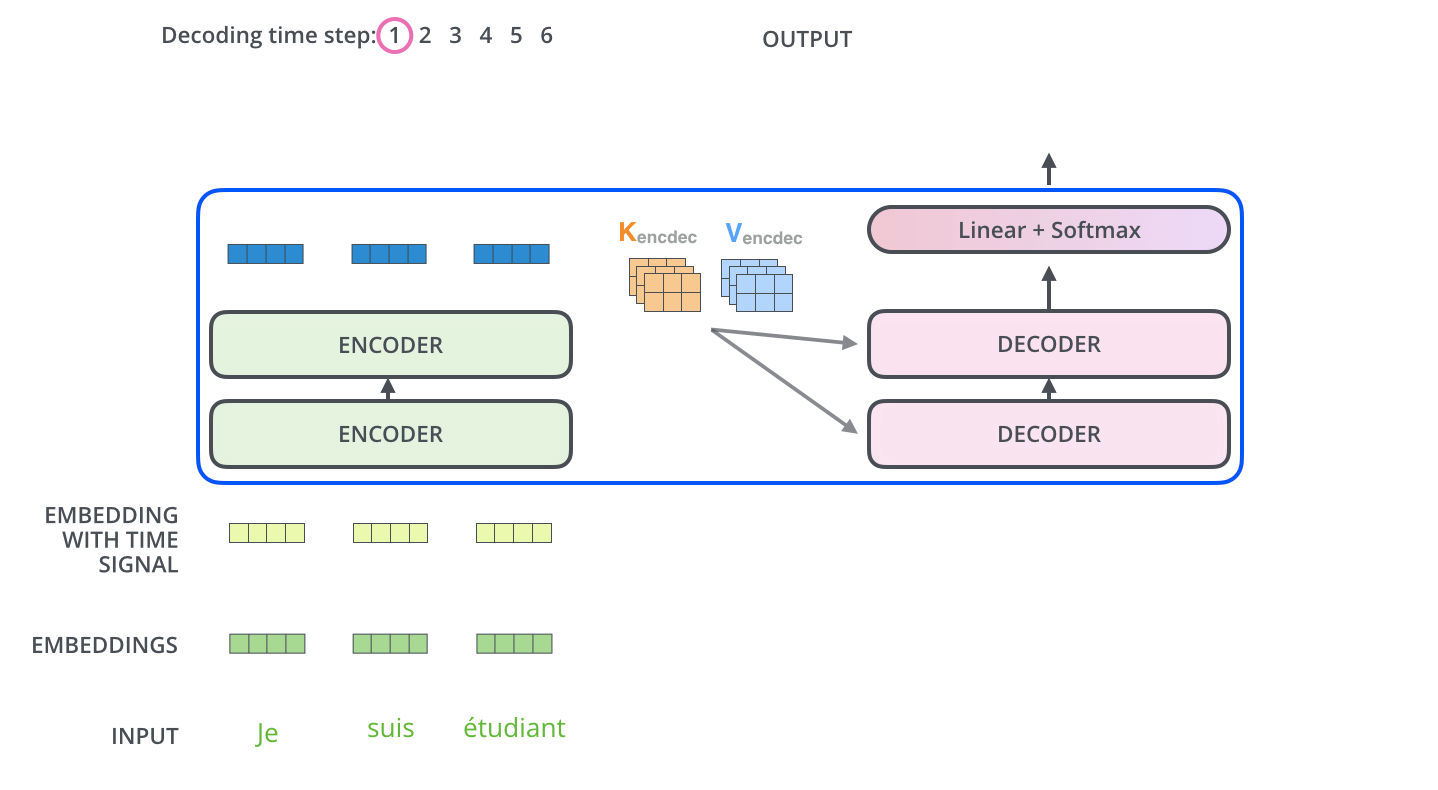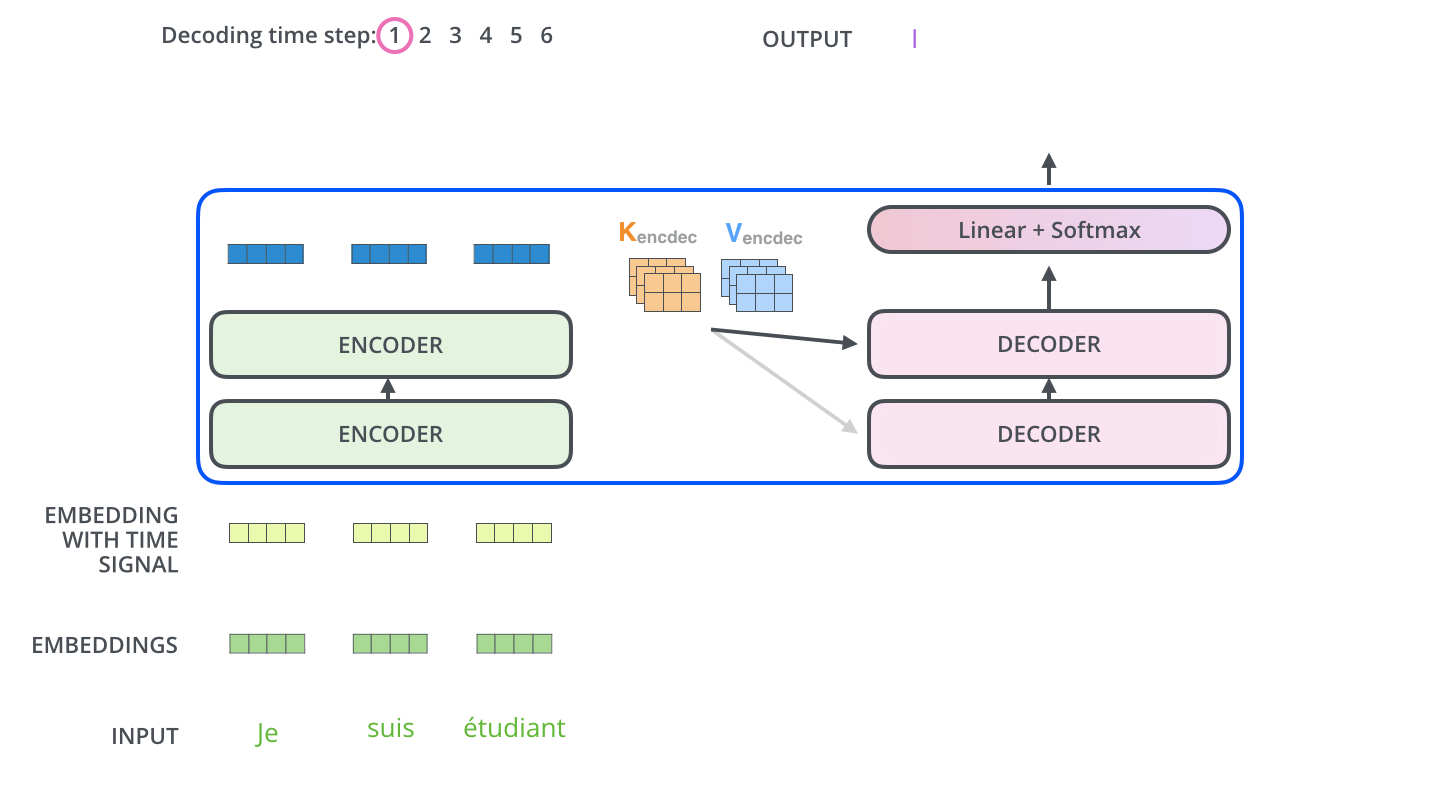
4、Encoder-Decoder Attention
:这是为了将输入的Seq和输出的Seq关联起来。这个Attention和Self-Attention是一样的,只不过其中的Key和Value是来自Encoder的,Query是根据Decoder中Self-Attention的输出算的。
5、feed forward neural network
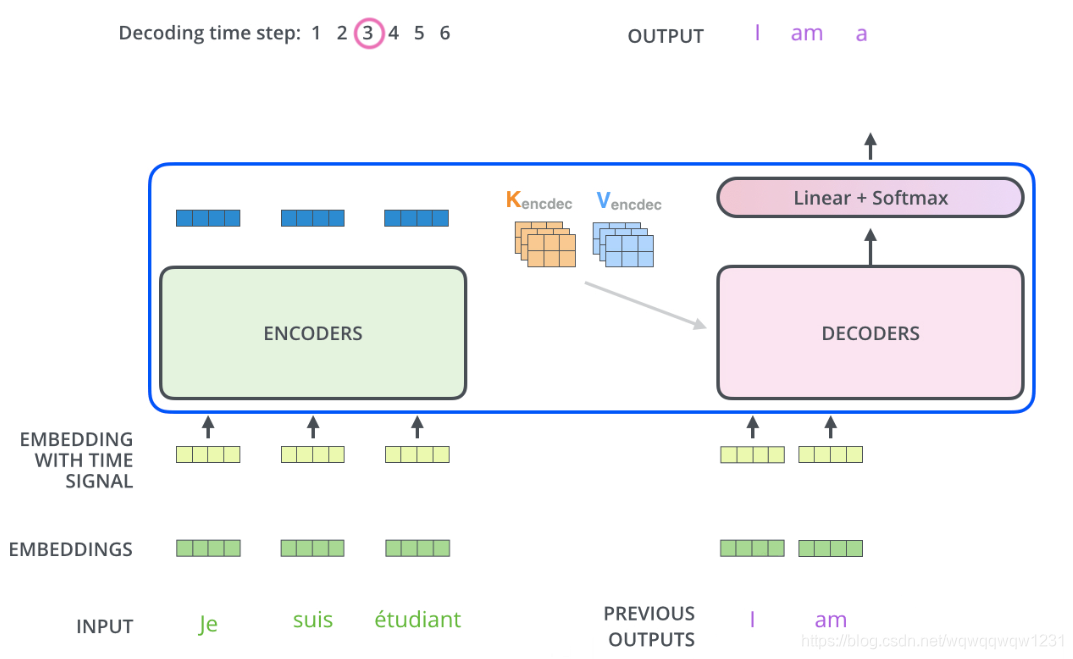
工作流程
再用两张图说明一下Decoder的工作过程:
1、先用encoder计算到
K
e
n
c
o
d
e
r
K_{encoder}
K
e
n
c
o
d
e
r
,
V
e
n
c
o
d
e
r
V_{encoder}
V
e
n
c
o
d
e
r
2、开始Decoding过程,每次预测一个单词。下面第二张图就是预测第三个单词时,Decoder的输入是预测的前两个单词。