官网介绍:https://pytorch.org/docs/stable/generated/torch.nn.Module.html;
nn.Module模块是所有神经网络的基类
,任何类都应该继承这个nn.Module类并且实现__init__和forward两个方法(forward方法基类中不实现);
Modules本身可以嵌套;
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
# Modules的嵌套
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
1: nn.Module模块常见方法
add_module(
name
,
module
)
import torch.nn as nn
from collections import OrderedDict
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.conv_block=torch.nn.Sequential()
self.conv_block.add_module("conv1",torch.nn.Conv2d(3, 32, 3, 1, 1))
self.conv_block.add_module("relu1",torch.nn.ReLU())
self.conv_block.add_module("pool1",torch.nn.MaxPool2d(2))
apply(
fn
):作用于所有子模块
@torch.no_grad()
def init_weights(m):
print(m)
if type(m) == nn.Linear:
m.weight.fill_(1.0)
print(m.weight)
net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
net.apply(init_weights)
bfloat16:将所有float类型转换为float16类型
模型中需要保存下来的参数包括两种:
- 一种是反向传播需要被optimizer更新的,称之为 parameter;
- 一种是反向传播不需要被optimizer更新,称之为 buffer;
buffers(
recurse=True
):返回模块所包含buffer的迭代器;
for buf in model.buffers():
print(type(buf), buf.size())
# <class 'torch.Tensor'> (20L,)
# <class 'torch.Tensor'> (20L, 1L, 5L, 5L)
children():返回所有子模块;
cpu()/cuda():设备;
eval():验证模式,与训练时的dropout或者BN会有不同;
get_parameter(
target
):获取模型参数;
load_state_dict(
state_dict
,
strict=True
):载入保存的ckpt(parameter和buffer);
# 模型的保存与加载
# state_dict 状态字典 一般包含parameters buffers
# 只保存权重
torch.save(model.state_dict(),'model_weights.pth')
# 加载训练的权重
model.load_state_dict(torch.load('model_weights.pth'))
model.eval()
# 保存优化器
model = Net()
optimizer = optim.SGD(net.parameters(), lr=0.001,momentum=0.9)
epoch = 5
loss = 0.4
PATH = ''
# 字典类型的 key-value
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
...
}, PATH)
# 加载部分
# 实例化模型
checkpoint = torch.load(PATH)
# 分别加载优化器参数
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.eval()
requires_grad_(
requires_grad=True
):是否需要梯度更新;
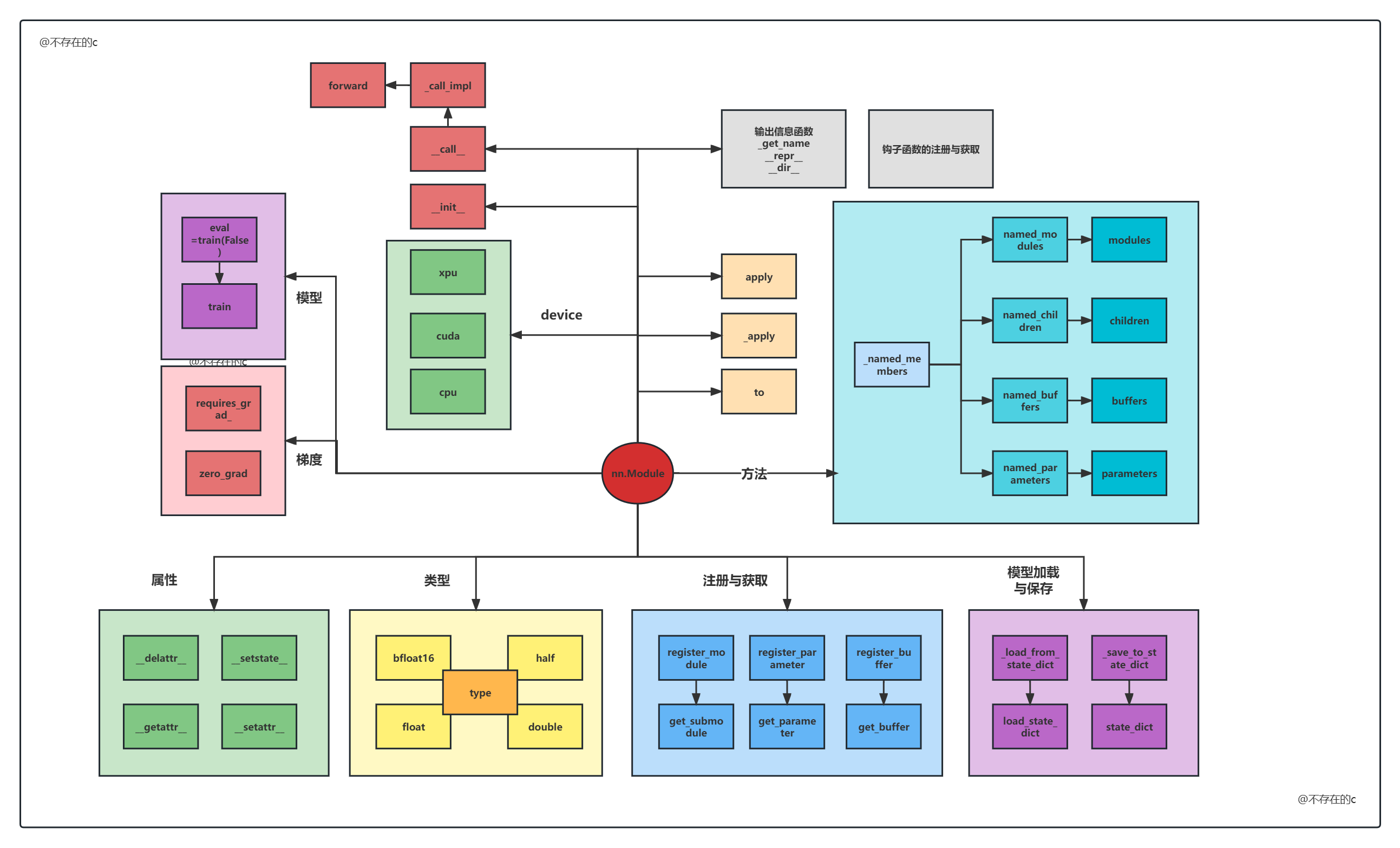
nn.Module常见函数
2: nn.Module源码
源码位置:torch/nn/modules/module.py
class Module:
def __init__(self) -> None:
# 注册buffer
def register_buffer(self, name: str, tensor: Optional[Tensor], persistent: bool = True) -> None:
# name: buffer的名字 tensor:具体的数据 persistent:是否持久化保存
# 一般自己实现一个层时才会用到
if ...:
# 抛出异常...
else:
# OrderedDict() 类型
self._buffers[name] = tensor
if persistent:
self._non_persistent_buffers_set.discard(name)
else:
self._non_persistent_buffers_set.add(name)
# 注册参数
def register_parameter(self, name: str, param: Optional[Parameter]) -> None:
# name:参数名 比如 权重w 偏置b
# Parameter类: Tensor类的继承
# 区别: Parameter类可以自动将参数添加的参数列表中 Tensor类不行
if param is None:
self._parameters[name] = None
else:
self._parameters[name] = param
# 添加模块
def add_module(self, name: str, module: Optional['Module']) -> None:
self._modules[name] = module
# 同添加模块
def register_module(self, name: str, module: Optional['Module']) -> None:
self.add_module(name, module)
# 获取模块内容 和add_module对应 有可能时嵌套的模块
def get_submodule(self, target: str) -> "Module":
atoms: List[str] = target.split(".")
mod: torch.nn.Module = self
for item in atoms:
mod = getattr(mod, item)
return mod
def get_parameter(self, target: str) -> "Parameter":
# rpartition:字符串的方法 将字符串分为 ".之前的" "." ".之后的"
module_path, _, param_name = target.rpartition(".")
# 先获取模块 模块存在参数才存在
mod: torch.nn.Module = self.get_submodule(module_path)
# 模块不存在则抛出异常
if not hasattr(mod, param_name):
raise AttributeError(mod._get_name() + " has no attribute `"
+ param_name + "`")
param: torch.nn.Parameter = getattr(mod, param_name)
if not isinstance(param, torch.nn.Parameter):
raise AttributeError("`" + param_name + "` is not an "
"nn.Parameter")
return param
def get_buffer(self, target: str) -> "Tensor":
# rpartition:字符串的方法 将字符串分为 ".之前的" "." ".之后的"
module_path, _, buffer_name = target.rpartition(".")
mod: torch.nn.Module = self.get_submodule(module_path)
if not hasattr(mod, buffer_name):
raise AttributeError(mod._get_name() + " has no attribute `"
+ buffer_name + "`")
buffer: torch.Tensor = getattr(mod, buffer_name)
# 判断是不是buffer 有可能是普通的tensor
if buffer_name not in mod._buffers:
raise AttributeError("`" + buffer_name + "` is not a buffer")
return buffer
def _apply(self, fn):
# 1.对所有子模块进行调用
for module in self.children():
module._apply(fn)
# 2. 对所有参数进行调用
for key, param in self._parameters.items():
if param is None:
continue
with torch.no_grad():
param_applied = fn(param)
# 3. 对所有buffer部分调用
for key, buf in self._buffers.items():
if buf is not None:
self._buffers[key] = fn(buf)
return self
# apply 函数和 _apply 函数的区别在于,_apply () 是 专门针对 parameter 和 buffer 而实现的一个“仅供内部使用”的接口
# 但是 apply 函数是“公有”接口 (Python 对类的“公有”和“私有”区别并不是很严格,一般通过单前导下划线来区分)
# 一般模型参数初始化时用到 递归的将fn应用到子模块
def apply(self: T, fn: Callable[['Module'], None]) -> T:
for module in self.children():
module.apply(fn)
fn(self)
return self
# 以下三个 关于device
# 应用_apply 匿名函数
def cuda(self: T, device: Optional[Union[int, device]] = None) -> T:
# pytorch的.cuda函数 其实是tensor的函数
# parameter和buffer都是tensor的(子)类型
return self._apply(lambda t: t.cuda(device))
def xpu(self: T, device: Optional[Union[int, device]] = None) -> T:
return self._apply(lambda t: t.xpu(device))
def cpu(self: T) -> T:
return self._apply(lambda t: t.cpu())
def type(self: T, dst_type: Union[dtype, str]) -> T:
# .type函数是tensor的函数
return self._apply(lambda t: t.type(dst_type))
# 以下转换数据格式的函数
def float(self: T) -> T:
return self._apply(lambda t: t.float() if t.is_floating_point() else t)
def double(self: T) -> T:
return self._apply(lambda t: t.double() if t.is_floating_point() else t)
def half(self: T) -> T:
return self._apply(lambda t: t.half() if t.is_floating_point() else t)
def bfloat16(self: T) -> T:
return self._apply(lambda t: t.bfloat16() if t.is_floating_point() else t)
# 对当前模型的parameter和buffer移动到device上
# 好像用处不大...
def to_empty(self: T, *, device: Union[str, device]) -> T:
return self._apply(lambda t: torch.empty_like(t, device=device))
# to函数的好几种用法
@overload
def to(self: T, device: Optional[Union[int, device]] = ..., dtype: Optional[Union[dtype, str]] = ...,
non_blocking: bool = ...) -> T:
...
@overload
def to(self: T, dtype: Union[dtype, str], non_blocking: bool = ...) -> T:
...
@overload
def to(self: T, tensor: Tensor, non_blocking: bool = ...) -> T:
...
# 原地修改Module(in-place)
# 举个例子
'''
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]], dtype=torch.float64)
'''
def to(self, *args, **kwargs):
device, dtype, non_blocking, convert_to_format = torch._C._nn._parse_to(*args, **kwargs)
# 把float转为其他
def convert(t):
if convert_to_format is not None and t.dim() in (4, 5):
# if t.is_floating_point() 找到浮点类型的进行转换
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None,
non_blocking, memory_format=convert_to_format)
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
return self._apply(convert)
# _call_impl函数体内会调用forward
# forward在基层类并不会实现 需要自己写代码时继承并实现
def _call_impl(self, *input, **kwargs):
# self.forward 需要自己实现
forward_call = (self._slow_forward if torch._C._get_tracing_state() else self.forward)
result = forward_call(*input, **kwargs)
return result
# 代表call函数调用了 _call_impl
# 这里__call__实际指向了_call_impl函数,因此调用__call__实际是调用_call_impl
__call__ : Callable[..., Any] = _call_impl
# 设置变量 为OrderedDict类型
def __setstate__(self, state):
self.__dict__.update(state)
# Support loading old checkpoints that don't have the following attrs:
if '_forward_pre_hooks' not in self.__dict__:
self._forward_pre_hooks = OrderedDict()
if '_state_dict_hooks' not in self.__dict__:
self._state_dict_hooks = OrderedDict()
if '_load_state_dict_pre_hooks' not in self.__dict__:
self._load_state_dict_pre_hooks = OrderedDict()
if '_non_persistent_buffers_set' not in self.__dict__:
self._non_persistent_buffers_set = set()
if '_is_full_backward_hook' not in self.__dict__:
self._is_full_backward_hook = None
# __getattr__ 魔法函数
# Python的魔法函数是指Python的类中,一系列函数名由双下划线包裹的函数
# 是Python的一种高级语法,允许你在类中自定义函数(函数名格式一般为__xx__),并绑定到类的特殊方法中
def __getattr__(self, name: str) -> Union[Tensor, 'Module']:
# 都是字典类型
# 调用 model._parameters 只能找到当前模块 不能递归子模块
# model.buffers
# model._modules
if '_parameters' in self.__dict__:
_parameters = self.__dict__['_parameters']
if name in _parameters:
return _parameters[name]
if '_buffers' in self.__dict__:
_buffers = self.__dict__['_buffers']
if name in _buffers:
return _buffers[name]
if '_modules' in self.__dict__:
modules = self.__dict__['_modules']
if name in modules:
return modules[name]
raise AttributeError("'{}' object has no attribute '{}'".format(
type(self).__name__, name))
# 设置属性 魔法函数
def __setattr__(self, name: str, value: Union[Tensor, 'Module']) -> None:
def remove_from(*dicts_or_sets):
for d in dicts_or_sets:
if name in d:
if isinstance(d, dict):
del d[name]
else:
d.discard(name)
params = self.__dict__.get('_parameters')
if isinstance(value, Parameter):
if params is None:
raise AttributeError(
"cannot assign parameters before Module.__init__() call")
remove_from(self.__dict__, self._buffers, self._modules, self._non_persistent_buffers_set)
self.register_parameter(name, value)
elif params is not None and name in params:
if value is not None:
raise TypeError("cannot assign '{}' as parameter '{}' "
"(torch.nn.Parameter or None expected)"
.format(torch.typename(value), name))
self.register_parameter(name, value)
else:
modules = self.__dict__.get('_modules')
if isinstance(value, Module):
if modules is None:
raise AttributeError(
"cannot assign module before Module.__init__() call")
remove_from(self.__dict__, self._parameters, self._buffers, self._non_persistent_buffers_set)
modules[name] = value
elif modules is not None and name in modules:
if value is not None:
raise TypeError("cannot assign '{}' as child module '{}' "
"(torch.nn.Module or None expected)"
.format(torch.typename(value), name))
modules[name] = value
else:
buffers = self.__dict__.get('_buffers')
if buffers is not None and name in buffers:
if value is not None and not isinstance(value, torch.Tensor):
raise TypeError("cannot assign '{}' as buffer '{}' "
"(torch.Tensor or None expected)"
.format(torch.typename(value), name))
buffers[name] = value
else:
object.__setattr__(self, name, value)
# 删除给定name的Module类中的成员
def __delattr__(self, name):
if name in self._parameters:
del self._parameters[name]
elif name in self._buffers:
del self._buffers[name]
self._non_persistent_buffers_set.discard(name)
elif name in self._modules:
del self._modules[name]
else:
object.__delattr__(self, name)
# 将module state储存到destination,并且只针对该module
# 所以这个函数一般是被module中的所有SubModule调用
# 被调用
def _save_to_state_dict(self, destination, prefix, keep_vars):
# 1. 遍历当前module的参数
# fan如destination字典中
for name, param in self._parameters.items():
if param is not None:
destination[prefix + name] = param if keep_vars else param.detach()
# 2. 遍历当前modulede buffer
for name, buf in self._buffers.items():
if buf is not None and name not in self._non_persistent_buffers_set:
destination[prefix + name] = buf if keep_vars else buf.detach()
extra_state_key = prefix + _EXTRA_STATE_KEY_SUFFIX
if getattr(self.__class__, "get_extra_state", Module.get_extra_state) is not Module.get_extra_state:
destination[extra_state_key] = self.get_extra_state()
T_destination = TypeVar('T_destination', bound=Mapping[str, Tensor])
@overload
def state_dict(self, destination: T_destination, prefix: str = ..., keep_vars: bool = ...) -> T_destination:
...
@overload
def state_dict(self, prefix: str = ..., keep_vars: bool = ...) -> 'OrderedDict[str, Tensor]':
...
# 返回一个包含module所有state的字典
def state_dict(self, destination=None, prefix='', keep_vars=False):
if destination is None:
# 以字典形式返回
destination = OrderedDict()
destination._metadata = OrderedDict()
destination._metadata[prefix[:-1]] = local_metadata = dict(version=self._version)
# 存储当前module的para和buffer
self._save_to_state_dict(destination, prefix, keep_vars)
# 遍历子模块
for name, module in self._modules.items():
if module is not None: # 结束条件
# 递归调用
module.state_dict(destination, prefix + name + '.', keep_vars=keep_vars)
for hook in self._state_dict_hooks.values():
hook_result = hook(self, destination, prefix, local_metadata)
if hook_result is not None:
destination = hook_result
return destination
# 用来加载module的(para and buffer)
# 被load_state_dict调用
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
for hook in self._load_state_dict_pre_hooks.values():
hook(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)
# 获取buffer和parameters的key放入local_state中
persistent_buffers = {k: v for k, v in self._buffers.items() if k not in self._non_persistent_buffers_set}
local_name_params = itertools.chain(self._parameters.items(), persistent_buffers.items())
local_state = {k: v for k, v in local_name_params if v is not None}
# 遍历local_state
for name, param in local_state.items():
key = prefix + name
if key in state_dict:
input_param = state_dict[key]
# ...
try:
with torch.no_grad():
# 如果当前key在state_dict中
# 则copy(赋值)
param.copy_(input_param)
except Exception as ex:
# ...
elif strict:
missing_keys.append(key)
# 加载ckpt模块
def load_state_dict(self, state_dict: 'OrderedDict[str, Tensor]',
strict: bool = True):
# 缺失值
missing_keys: List[str] = []
# 多余值
unexpected_keys: List[str] = []
error_msgs: List[str] = []
# copy state_dict so _load_from_state_dict can modify it
metadata = getattr(state_dict, '_metadata', None)
state_dict = state_dict.copy()
if metadata is not None:
# mypy isn't aware that "_metadata" exists in state_dict
state_dict._metadata = metadata # type: ignore[attr-defined]
# 核心
def load(module, prefix=''):
local_metadata = {} if metadata is None else metadata.get(prefix[:-1], {})
# 调用 当前模块的para和buffer
module._load_from_state_dict(
state_dict, prefix, local_metadata, True, missing_keys, unexpected_keys, error_msgs)
# 递归调用
for name, child in module._modules.items():
if child is not None:
load(child, prefix + name + '.')
load(self)
del load
return _IncompatibleKeys(missing_keys, unexpected_keys)
# 对应的4组
# parameters named_parameters
# buffers named_parameters
# children named_children
# modules named_children
# 返回一个迭代器 包括names和members (name,value)
# 一个查找函数
def _named_members(self, get_members_fn, prefix='', recurse=True):
r"""Helper method for yielding various names + members of modules."""
memo = set()
modules = self.named_modules(prefix=prefix) if recurse else [(prefix, self)]
for module_prefix, module in modules:
members = get_members_fn(module)
for k, v in members:
if v is None or v in memo:
continue
memo.add(v)
name = module_prefix + ('.' if module_prefix else '') + k
yield name, v
# 调用self.named_parameters
# _parameters: 属性(不包含子模块)
# parameters: 函数(包含子模块)
def parameters(self, recurse: bool = True) -> Iterator[Parameter]:
for name, param in self.named_parameters(recurse=recurse):
yield param
# 遍历 通过匿名函数进行遍历
def named_parameters(self, prefix: str = '', recurse: bool = True) -> Iterator[Tuple[str, Parameter]]:
# _named_members 通过传入函数进行遍历
gen = self._named_members(
lambda module: module._parameters.items(),
prefix=prefix, recurse=recurse)
for elem in gen:
yield elem
def buffers(self, recurse: bool = True) -> Iterator[Tensor]:
for _, buf in self.named_buffers(recurse=recurse):
yield buf
def named_buffers(self, prefix: str = '', recurse: bool = True) -> Iterator[Tuple[str, Tensor]]:
gen = self._named_members(
lambda module: module._buffers.items(),
prefix=prefix, recurse=recurse)
for elem in gen:
yield elem
def children(self) -> Iterator['Module']:
for name, module in self.named_children():
yield module
def named_children(self) -> Iterator[Tuple[str, 'Module']]:
memo = set()
for name, module in self._modules.items():
if module is not None and module not in memo:
memo.add(module)
yield name, module
def modules(self) -> Iterator['Module']:
for _, module in self.named_modules():
yield module
def named_modules(self, memo: Optional[Set['Module']] = None, prefix: str = '', remove_duplicate: bool = True):
if memo is None:
memo = set()
if self not in memo:
if remove_duplicate:
memo.add(self)
yield prefix, self
for name, module in self._modules.items():
if module is None:
continue
submodule_prefix = prefix + ('.' if prefix else '') + name
for m in module.named_modules(memo, submodule_prefix, remove_duplicate):
yield m
# 训练模式
# 将Module及其SubModule分别设置为training mode
# mode: 影响子模块
# 更多信息见如Dropout代码 参数设置
def train(self: T, mode: bool = True) -> T:
if not isinstance(mode, bool):
raise ValueError("training mode is expected to be boolean")
self.training = mode
for module in self.children():
module.train(mode)
return self
# 验证模式
# 只对特定的Module有影响,例如Class Dropout、Class BatchNorm
def eval(self: T) -> T:
return self.train(False)
# 是否需要记录梯度
def requires_grad_(self: T, requires_grad: bool = True) -> T:
# 遍历所有参数
for p in self.parameters():
# 这个是tensor的函数 p是tensor
p.requires_grad_(requires_grad)
return self
# 设置self.parameters()的gradients为零
# 一般对优化器用
def zero_grad(self, set_to_none: bool = False) -> None:
# 遍历参数
for p in self.parameters():
if p.grad is not None:
if set_to_none:
p.grad = None
else:
if p.grad.grad_fn is not None:
p.grad.detach_()
else:
p.grad.requires_grad_(False)
p.grad.zero_()
# 输出Module的相关信息
def _get_name(self):
return self.__class__.__name__
# 输出Module的相关信息
def __repr__(self):
# We treat the extra repr like the sub-module, one item per line
extra_lines = []
extra_repr = self.extra_repr()
# empty string will be split into list ['']
if extra_repr:
extra_lines = extra_repr.split('\n')
child_lines = []
for key, module in self._modules.items():
mod_str = repr(module)
mod_str = _addindent(mod_str, 2)
child_lines.append('(' + key + '): ' + mod_str)
lines = extra_lines + child_lines
main_str = self._get_name() + '('
if lines:
# simple one-liner info, which most builtin Modules will use
if len(extra_lines) == 1 and not child_lines:
main_str += extra_lines[0]
else:
main_str += '\n ' + '\n '.join(lines) + '\n'
main_str += ')'
return main_str
# 输出Module的相关信息
def __dir__(self):
module_attrs = dir(self.__class__)
attrs = list(self.__dict__.keys())
parameters = list(self._parameters.keys())
modules = list(self._modules.keys())
buffers = list(self._buffers.keys())
keys = module_attrs + attrs + parameters + modules + buffers
# Eliminate attrs that are not legal Python variable names
keys = [key for key in keys if not key[0].isdigit()]
return sorted(keys)