1. 现象
压测无法进入hystrix熔断处理, 检查feign.hystrix.enabled是开启的,hystrix设定的最大并发连接为100,降级最大并发连接为50
hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests=100
hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests=50
理论上连接超过150,就会触发fallback降级处理, 但并发压测线程从100~1500, 都未能触发熔断降级,于是开始了逐步排查之路。
2. 排查
-
检查hytrix有无独立配置
FeignClient是可以支持独立的配置,检查要调用的服务,有无配置configuration
@FeignClient(name = Constants.SERVICE_NAME, fallback = OrderService.HystrixClientOrderService.class, configuration = FeignClientWithoutHystrixConfig.class)如果配置中采用的是Feign.builder(), 是不会走hystrix熔断逻辑:
public class FeignClientWithoutHystrixConfig { private final Logger log = LoggerFactory.getLogger(this.getClass()); @Bean public Feign.Builder feignBuilder() { return Feign.builder(); } }再检查有无全局的@Configuration配置, 发现并没有。
-
检查hystrix有未真正拦截处理
原接口存在一大堆业务逻辑, 为便于调试, 简化逻辑,重新抽取为独立的接口,调用测试,
发现是受到hystrix的控制,通过HystrixInvocationHandler对象进行调用:

-
检查hystrix有无读到正确的并发数配置
增加属性配置, 并打印出来, 是配置正确的并发数

-
检查测试程序的并发是否受限
到这一步, 问题就变得比较蹊跷, 这时候需要检查测试程序是否能够达到相应的并发数,因为是走的http并非feign方式调用, 这时需要检查httpclient的连接池配置, 发现存在问题:

我们要知道服务的调用关系以及熔断作用的地方:
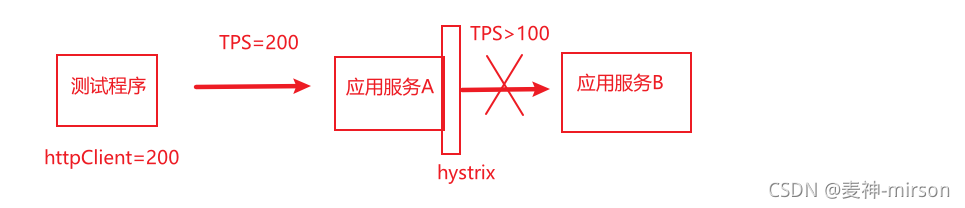
maxConnPerHost 为 50,限制住了调用应用服务A最大50个连接, 从上游就限制住了并发数是进入不了熔断的,所以需要将maxTotalConn和maxConnPerHost都调大, 要超过hystrix配置的最大并发数。
这就结束了?并没有,但结果有一些不一样, 应用服务A重启后, 第一次压测, 会有部分连接进入熔断,但再重试几次, 就没有再进入压测, 这又是什么原因, 还得继续摸排。
-
减小hystrix并发阈值
由于服务启动第一次能进入熔断,说明hystrix是有生效的, 这时候尝试将hystrix的并发阈值调小:
hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests=50
效果出来了, 每次调用,都会有部分请求出现熔断, 但为何加大就不行呢, 生产环境肯定不能配置这么小,
得继续查明具体原因。
-
hytrix源码增加日志打印
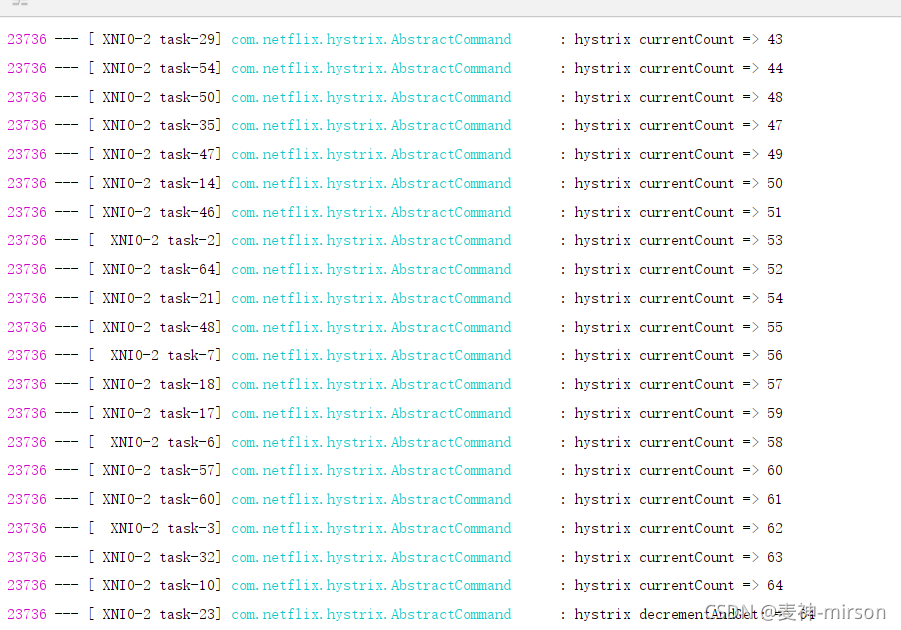
这时候就有必要深入源码进行跟踪分析了, 找到AbstractCommand关于信号量的判断处理逻辑, 在内部增加日志打印, 观测实时的信号量变化。

要让日志正常打印, 不要忘记指定日志级别输出

测试并跟踪输出,发现连续几轮, 信号量最高都是在60左右徘徊, 无论测试程序的并发数是100或1000
-
修改容器undertow的并发接入数限制
排查一大圈, 可以确定应用服务内部是受到了限制, 导致并发上不去, 那会有什么在hystrix之前对连接做限制呢, 最大的嫌疑就是服务容器了,检查了spring boot启动输出, 采用的是undertow,看下默认的连接数是多少, 查阅其源码:
private Builder() { ioThreads = Math.max(Runtime.getRuntime().availableProcessors(), 2); workerThreads = ioThreads * 8; long maxMemory = Runtime.getRuntime().maxMemory(); //smaller than 64mb of ram we use 512b buffers if (maxMemory < 64 * 1024 * 1024) { //use 512b buffers directBuffers = false; bufferSize = 512; } else if (maxMemory < 128 * 1024 * 1024) { //use 1k buffers directBuffers = true; bufferSize = 1024; } else { //use 16k buffers for best performance //as 16k is generally the max amount of data that can be sent in a single write() call directBuffers = true; bufferSize = 1024 * 16; } }可以看到workerThreads就是控制实际工作的线程数, 这里默认是根据CPU核心数来配置的, 如果CPU是8个核心,那么workerThreads工作线程数就是64,这也就意味着,如果每个请求占据1S的处理时间, 那么TPS并发只能是64,这和上面的信号量一直在60左右是初步吻合的,我们修改其数量为256:
server:
undertow:
worker-threads: 256再次进行压测, 可以看到信号量上升超过了100阈值,请求被拒绝了:

至此, hystrix可以正常生效控制了。
3. 总结
-
进行hystrix限流降级配置,要了解其工作原理和各项配置的作用, 便于排查定位。
如果并发超过阈值hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests=100,会产生拒绝rejection,并进入降级处理逻辑:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iJbGLwef-1632187599457)(images/image-20210918212934172.png)]
如果进入降级的请求数超过阈值
hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests=50, 则会拒绝产生熔断,熔断恢复要根据时间窗配置的时间确定hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds=20000
-
在进行压测时, 一定要确保各个环节的连接没有受限, 无论是测试程序的httpClient,还是应用服务容器的undertow,或是操作系统的tcp连接限制, 都要做好相应的检查。undertow的工作连接配置修改:
server:
undertow:
worker-threads: 256如果测试程序是采用feign连接调用,那么需要修改feign的http连接池配置,参数如下:
feign.httpclient.enabled=true
feign.httpclient.max-connections=400
feign.httpclient.max-connections-per-route=200