我想大家对Kafka或多或少都有所耳闻,那么它究竟是什么呢?其实说白了也很简单,它其实就是一个分布式的消息队列,也就是我们通常所说的消息的发布和订阅,只是它的目标更倾向于高吞吐和低延迟。那我们就从头开始来看看Kafka究竟是如何诞生的。
发布/订阅消息
在正式开始聊Kafka之前,我们来看看什么是消息的发布和订阅。我们先来看这样一个例子:系统中有两个应用程序,然后我们有一个metrics的dashboard,当这两个应用程序开始运行时,会把相关的metric数据发送到dashboard所在的server,然后就可以把它们的metric显示出来,简单的架构如下所示:

这种架构看起来还是很清晰的,但是当我们的系统变得稍微庞大起来,有了更多的应用,也需要有了不同的metric处理方式,比如我们既需要显示metrics的数据到一个UI上,又需要分析这个metric或者根据metric的数据来做一些monitor发送alerts之类的,那整个系统就可能变得复杂起来,甚至有时你会觉得有一些系统,比如monitor其实并不需要你一直把metric发送过去,最好是做个poll的形式,让monitor主动找application来拿数据,于是你的系统变成了下面这样:

这样一来整个系统看起来就很乱,程序员的特性让你蠢蠢欲动,捋起袖子来refactor一下呗,你想啊想,要是能在中间加一层,让所有的应用端把数据都发送给这一层,然后对这个数据感兴趣的server再统一到这一层来拿就完美了,于是你的想法就变成了下面这样的一个架构:
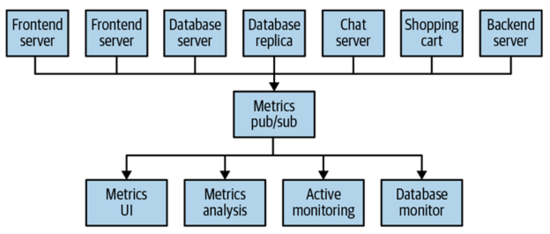
而这就是最基本的消息发布和订阅的形式。
这个架构运行得还不错,于是你在吃饭的时候和同事吹嘘了一下,你的同事发现它在处理log和tracking的时候也有类似的需求,于是他来和你学习了一下,把它那边的处理逻辑也改成了这个机制,所以你们的系统变成了下面这样:
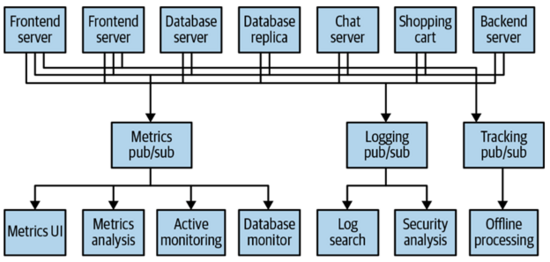
这样一来你的系统里面有了三个类似的发布/订阅系统,他们的business逻辑有所不同,但技术层面是类似的。所以当你们把这个架构demo给老板看并要求提职加薪的时候,老板说,你们能不能搞一个统一的系统,这样可以给所有有类似需求的team一起使用,而且也不需要单独处理各自的bug等等。这个时候Kafka就诞生了,它就是这样一个统一的系统,来处理类似的功能需求的。
消息
我们把各个应用给Kafka发送的内容称之为消息,然后各个处理的模块只要订阅相应的消息就可以了。对Kafka本身来说看,消息是什么样子的它并不关心,因为它只是一个转发中心,只要接受端的各个处理模块能理解就好。我们可以简单把消息理解成类似数据库中的一条记录,当然可以有它定义的格式或者schema,但是对数据库本身来说,它并不关心这个schema的定义。
Topics和partitions
Kafka中的消息会被分类成一个topics,用数据库来理解,topics就类似一个表。每个topics会被分成多个partition。所以当你写数据到topics时,会按照partition的规律写到各个partition中,在每个partition中它是有序的,有点类似数据库的append-only log的方式,但是多个partition之间数据的顺序是无法保证的。
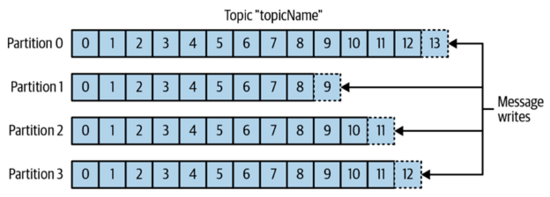
上面这个图就显示了一个拥有4个partition的topic,也许你会问为什么要这个partition啊,这里有很多好处,比如说我们可以把不同的partition部署到不同的机器上,这样就可以在大吞吐量的时候做到很好的scalability,当然我们还可以对每个partition做replication,从而提高high availability以防止单点的fail。
我们通常所说的数据流在Kafka这里对应的其实就是一个topic。
Producer和Consumer
Producer和Consumer这两个概念比较好理解,前者产生消息,后者需要接收处理消息。
对producer来说,主要需要注意的就是把消息发送给谁,也就是topics中的哪个partition,需要有一定的机制来决定发送到的partition,可以是类似hash的map来选择partition,这样同样的消息能发送到同一个partition,也可以是均匀的partition分布或者是基于consumer的partition分布,这些方式的选取取决于你的数据形式和business的需求。只是需要注意的是不同的partition之间的顺序是无法保证的,但是同一个partition则是可以保证这一点的。
Consumer可以订阅多个topics中的多个partition的消息,它是通过消息的offset来判断是否已经取得了相应的消息,offset是一个递增的数值,每个消息的这个offset都不一样(同一parition中),这样一来consumer就可以使用这个值来区分不同的消息。只要保存好这个offset,哪怕有重启等事件的发生,也能够继续从上次的地方取消息。
多个consumer还可以组成一个consumer group,他们可以共同订阅一个topics的消息,但是一个partition只能被consumer group中的一个consumer来进行处理,当这个consumer group中的某个consumer出现了问题之后,可以让consumer group中别的consumer来继续处理出问题的consumer所对应的partition,示意图如下所示:
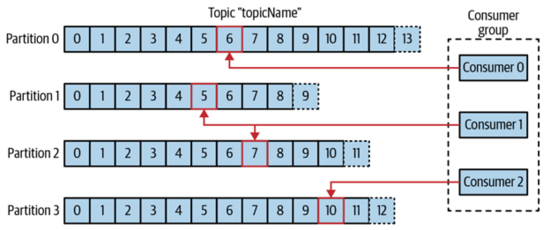
Broker和Cluster
我们称每个Kafka中的server就是一个broker,它一方面接收producer的消息,给他们加上offset,把这些消息写到磁盘中。另一个方面它还要服务consumer,处理它们请求消息的request。一般来说,一个broker可以支持几千个partition,每秒处理百万基本的消息(当然不同的硬件也有不同的处理能力)。
多个broker可以组成cluster,其中一个broker会被选举成controller,这个controller需要做一些特殊的操作,比如把不同的partition assign给不同的broker,监控处理fail的broker等。
同样在partition level还有一个leader的概念,我们前面提到partition可以有多份拷贝(replication),他们中只有一份拷贝是leader,另外的我们称之为followers,一般来说会分布在不同的broker上,从而达到高可靠性的目的。所有的producer都必须把消息发布给leader,而consumer则可以从leader或者followers来获取消息。其实和数据库的读写一样,写必须经过leader,读则可以到任意节点。简单的示意如下图所示:
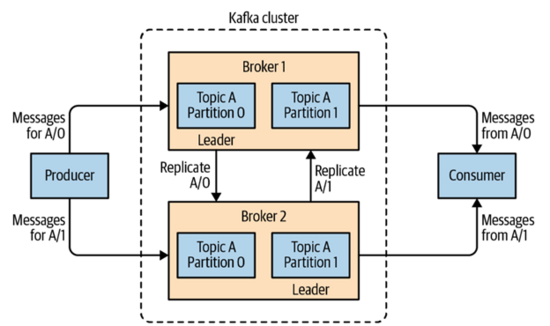
另外一个Kafka很重要的特性就是它的持久保存,也就是说每个broker都会把消息保存一段时间或者直到保存的消息大于某个大小。这个多长时间的设置一般会设置在topic这个层级上。
多个cluster
很多时候我们会使用多个cluster,这样做有各种各样的原因,一般来说下面这三种原因会比较主流:
- 隔离不同类型的数据
- 因为安全的原因进行隔离
- 不同数据库的隔离
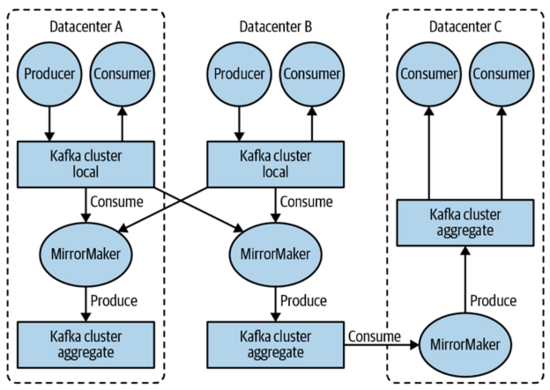
有时候我们希望消息能够在不同的cluster之间交互,这个时候就引入了一个新的技术,我们称之为MirrorMaker。下图所示的例子就是数据中心A、B通过MirroMaker组成了一个新的aggregate的cluster,然后这个aggregate的消息又被数据中心C订阅,然后发布给数据中心C的aggregate的cluster,从而被数据中心C的consumer使用。
Kafka的特性
我们上面简单介绍了Kafka中的各种概念,下面来看看我们为什么要选择Kafka:
支持多producer
Kafka支持多个producer,就像我们上面例子中提到的一样,多个应用可以很自然地送消息给同个topic或者不同的topic。这样一来consumer就可以只需要处理一个数据流。
支持多consumer
Kafka支持多个consumer读哪怕是同一个数据流,这和别的类似系统中消息只能被一个consumer读取不太相同。当然你也可以把这些consumer放到同一个consumer group中,这样一个消息就只被一个consumer读取了。
数据持久保存到磁盘
Kafka的消息是被持久保存到磁盘上的,这样一来consumer就不需要实时来拿消息了,这也就意味着即使consumer很慢也不用担心有消息会丢失,甚至可以把consumer拿出去维护一下,然后再加回来也是可以继续获取消息而不需要担心有任何问题。
Scalable
Kafka的这种架构很容易处理大量的数据,production环境可以搞个几十或者几百个broker的cluster完全没有问题。而且因为replication的存在,所以对failure的处理也有保证。
高性能
把上面这些特性结合起来也就意味着Kafka的性能很容易就可以做得很好,毕竟多producer/consumer加上cluster完全可以高效地处理很大的流量。
总结
至此本文就把Kafka相关的基本概念和总体架构进行了简单介绍,希望大家能够对Kafka有个初步的了解。