:什么是分布式软件系统?分布式软件系统是什么意思?
分布式软件系统(Distributed Software Systems)是支持分布式处理的软件系统,是在由通信网络互联的多处理机体系结构上执行任务的系统。它包括分布式操作系统、分布式程序设计语言及其编译(解释)系统、分布式文件系统和分布式数据库系统等。
分布式操作系统负责管理分布式处理系统资源和控制分布式程序运行。它和集中式操作系统的区别在于资源管理、进程通信和系统结构等方面。
分布式程序设计语言用于编写运行于分布式计算机系统上的分布式程序。一个分布式程序由若干个可以独立执行的程序模块组成,它们分布于一个分布式处理系统的多台计算机上被同时执行。它与集中式的程序设计语言相比有三个特点:分布性、通信性和稳健性。
分布式文件系统具有执行远程文件存取的能力,并以透明方式对分布在网络上的文件进行管理和存取。
分布式数据库系统由分布于多个计算机结点上的若干个数据库系统组成,它提供有效的存取手段来操纵这些结点上的子数据库。分布式数据库在使用上可视为一个完整的数据库,而实际上它是分布在地理分散的各个结点上。当然,分布在各个结点上的子数据库在逻辑上是相关的。
分布式系统的几个重要特性
从使用分布式系统的用户所关心的主要问题出发,我们可以看出分布式系统的具有以下几个重要特征。
1) 高稳定性
分布式系统的用户获取服务的请求随时随地都有可能发生。所以,我们需要分布式系统一年365天7*24小时随时给用户提供服务,分布式系统的稳定性要求非常高。如果系统的稳定性不好,经常发生宕机事故,将会伤害到用户的忠诚度。
2) 高可用性
什么是高可用?这个概念在分布式系统中是一个非常重要的概念。高可用是指,当系统发生了不可抗拒的灾难(例如机房断电,火灾等)以后,能快速恢复服务的能力。通常来说,也就是双机热备。当系统的一部分设备发生灾难以后,能使服务快速、无缝的切换到备份集群上,使用户几乎感受不到灾难的发生。
3) 高可扩展
一般来说,分布式系统要求能承载海量的数据,而且要求运行相当长的时间。而物理设备的空间、容量和性能是一定的。对于一家不断发展的公司而言,用户的数据量却是不断增长的。在系统运行了一段时间以后,往往会受到物理设备的局限,例如,物理设备的总硬盘空间不够,或者物理设备的总运算能力不够,或者网络吞吐能力不足等局限。一般来说,架构设计合理的分布式系统,是可以通过增加物理设备以实现增加系统服务能力的,例如用户并发量,系统数据吞吐量,系统数据总容量等。如果不能做到这一点,那么系统的可扩展性到达极限,可能需要对系统进行重新设计。然而,总体来说,分布式系统的扩展性是相对的,不是无限的。
4) 高可管理
我们知道,分布式系统需要持续运行相当长的时间。通常来说,系统运行的时间越长,宕机的风险也就越大。从概率统计的观点来看,我们很容易理解这一点。正如我们都知道,飞机的出事故的概率是很低的,然而长时间运行无故障以后,发生事故的概率就会明显上升。因此,停机检修成为了降低故障率的一个重要措施。分布式系统也一样。我们需要在相对稳定的系统运行了一段时间以后,分集群对服务器进行检修,这里就涉及到系统的可管理性。这里需要强调的是,系统检修不等于停止服务。对于分布式系统,我们需要始终坚持的一个原则是一年365天7*24小时提供服务。系统的可管理性可以分为两种,一种是故障发生时的管理;一种是故障发生前的管理。故障隔离属于发生故障时的管理;而系统检修则是故障发生前的管理,即事前管理。我们希望做到事前管理。
那么,如何才能做到事前管理呢?由于系统具有高可用性,我们可以实现对系统的检修。例如,如果我们的分布式系统采用的是主辅集群设计,通常情况下,辅集群是不对外提供服务,而只是备份用的,那么这时候,我们可以将用户流量切换到辅集群上,关闭主机群的服务,对主集群的系统进行检修,排除一些隐患和故障以后,重新开启主机群的服务,将用户流量切换到主集群。这个是采用主辅集群轮换的方式实现系统检修的。当系统流量非常大的时候,这种做法的风险非常大,主要原因是,在用户流量的切换过程中,瞬间的流量冲击太大,容易出现问题。
还有一种比较好的方式是局部检修。如果系统设计采用的是局部对等的小集群设计,我们可以先将某一个小集群(例如20台服务器)挂起(系统挂起指的是保持老用户的服务功能,拒绝为新的用户提供服务),等待该集群的用户切换到其他的对等的小集群上,当切换完成后,就可以对该小集群的服务器进行检修。这样做的好处在于切换过程中,用户流量小,避免了大流量冲击的风险。
5) 高并发性
高并发性是一个相对比较容易理解的概念,即系统在单位时间内能同时接受和处理的请求数量。高并发性也是分布式系统的一个基本要求。然而,承载着不同应用的不同分布式系统,对于并发设计的要求也是有很大差异的。一般来说分为两种情况:一种情况,需要对会话过程进行保持(session保持),即,当用户与分布式系统的连接断开以后,需要重新连回到分布式系统内部原来分配给用户提供服务的设备上;另一种,不需要对会话过程进行保持,也就是说,用户与分布式系统内部的某一物理设备连接断开后,重新连接到分布式系统内部的任意物理设备也能提供正确的服务。
一般来说,解决高并发问题,核心的设计是负载均衡。在某一个时刻,单一物理设备的处理能力是有限的。将用户流量、用户的并发请求合理的分配到更多的物理设备上,是解决高并发问题的基本方法。负载均衡算法(有很多种)往往也是分布式系统测试的核心内容。
6) 数据一致性
分布式系统具有硬件设备分布式零散性的特点,内部数据的一致性也是非常重要的。数据的时效性对于用户来是非常重要的。然而,这也是分布式系统设计中需要解决的一个难题。对于海量数据和跨地域数据同步来说,则更加困难。首先,我们要保证数据同步的正确性;其次,我们需要保证数据同步的高效性,即在足够短的延时中完成数据同步。由于分布式系统可能存在地域分散的特点,区域间的固定延时(RTT)将是分布式系统设计的一个难题。
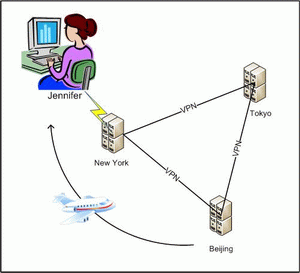
一个典型的分布式系统的应用
在分布式系统的应用中,下图描述的是一个典型的应用。A公司的用户遍布全球各地,该公司在全球分别设有多个IDC数据服务中心(例如:纽约、北京、东京等)。某北京用户Jennifer一直在北京使用A公司的数据服务,并且保存了相当多的文档和数据等。由于工作需要,Jennifer到纽约出差,需要使用A公司的数据服务,使用以前保存的文档和数据。这时,Jennifer使用到的数据服务将由A公司部署在纽约的数据服务器提供。