在自然语言处理中比较热门的操作就是中文或英文语句分词了,分词就是按照不同的算法和参数将语句分成若干词汇。拆分后的关键词可以进行词频统计或者词云图片生成等,能够快速方便的找到语句的核心主题热点。
在java开发中,如果单纯进行原始功能开发,分词功能耗时耗力,效果不一定能达到理想结果。有一个比较流行的代码工具平台“昂焱数据”,其官方网址为
www.ayshuju.com
。上面有封装好的各种功能代码工具。该网站上的“语句分词及相似度对比”java代码工具可以直接使用,中文语句分词支持的分词算法包括Lucene、Ansj、corenlp、HanLP、IKAnalyzer、Jcseg、Jieba、mmseg4j、MYNLP、Word等10种;英文语句分词支持的分词算法包括IKAnalysis、StanfordNlp等两种主流算法。
下面将“语句分词及相似度对比”工具使用步骤做一下记录:
第一步:下载并安装jar到本地maven库
登录该网站,在“代码工具”一栏找到“语句分词及相似度对比”代码工具,代码工具如下图所示:
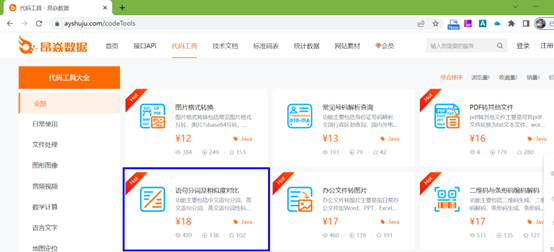
下载该代码工具并解压,双击“”执行,将提示的maven坐标粘贴到项目的pom文件中即可。
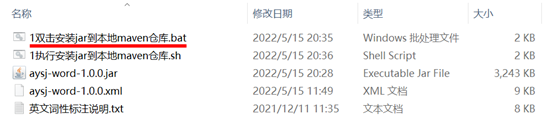
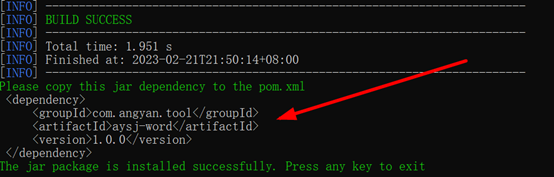
第二步:将该jar包的maven坐标粘贴到项目的pom文件中
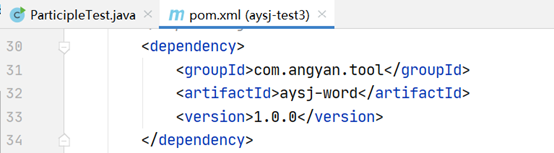
第三步:完整的测试代码如下
package com.example.demo.test;
import com.angyan.tool.word.base.enums.ChineseTokenizerEnum;
import com.angyan.tool.word.base.enums.EnglishTokenizerEnum;
import com.angyan.tool.word.util.TokenizerUtil;
import java.util.List;
/**
* @author angyankj
*/
public class ParticipleTest {
public static void main(String[] args) {
// 中文文本
String chnContent = "昂焱数据是为IT行业各种角色人员提供丰富的一站式技术资源的平台!";
// 中文分词
String chnResult = TokenizerUtil.getChineseTokenizerResult(ChineseTokenizerEnum.ANSJ, chnContent);
// 打印中文分词结果
System.out.println(chnResult);
// 英文文本
String engContent = "Love is not a maybe thing. You know when you love someone.";
// 英文分词
List<String> engResult = TokenizerUtil.getEnglishTokenizerResult(EnglishTokenizerEnum.IKANALYZER, engContent);
// 打印英文分词结果
System.out.println(engContent);
}
}
中文分词及英文分词的运行结果如下(分词之间以空格隔开):

版权声明:本文为houfengfei668原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。