1 深度学习中的注意力机制
2014年Recurrent Modelsof Visual Attention — NIPS 2014: 2204-2212
https://proceedings.neurips.cc/paper/2014/file/09c6c3783b4a70054da74f2538ed47c6-Paper.pdf
![]()
https://proceedings.neurips.cc/paper/2014/file/09c6c3783b4a70054da74f2538ed47c6-Paper.pdf
2014年-2015年Attention in Neural Machine Translation — ICLR 2015
https://arxiv.org/abs/1409.0473
![]()
https://arxiv.org/abs/1409.0473
2015年Attention-Based RNN in NLP and Image — ICML 2015
http://proceedings.mlr.press/v37/xuc15.pdf
![]()
http://proceedings.mlr.press/v37/xuc15.pdf
2015年-2016年Attention-Based CNN in NLP
2017年Self-Attention in Neural Machine Translation
2 Recurrent Models of Visual Attention
1. RNN模型处理图像分类任务,采用
强化学习的方法训练 — 当要看的图片很大时,模仿人类看图片时会注意图片的某些位置 — 关注图片重点信息,忽略不重点信息
模型由如下几部分构成:
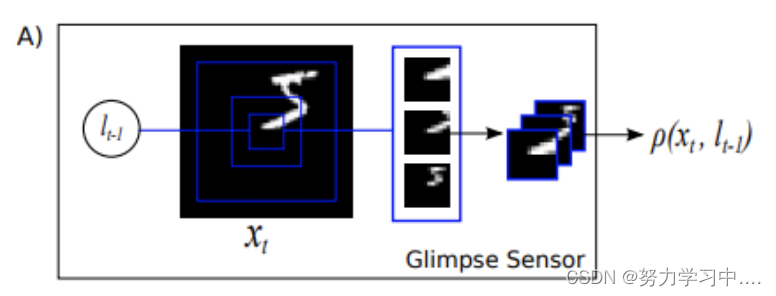
Glimpse Sensor:
Glimpse Sensor提取图像输入,通过位置信息
(前一时刻传来的),
为输入数据,位置信息传到
后,将会对
的
位置进行采样,按照图里的样子,在这个特定的位置,要采集3个patchs,比如初始的采样图像大小为8*8,接着采样的大小为(8 * 2) * (8 * 2)– 最里面那个方框
“2”表示的是一个因子,是相对前一次采样的尺寸大小的乘子,最后一次采样的大小为(8 * 2 * 2) * (8 * 2 * 2),这3个采样的照片的中心位置不变,就是前面传过来的
,接下来对这三个采样的照片进行一个resize,接下来对这三个采样的照片进行一个resize,例如全部都重新设置成大小为8 * 8 尺寸的照片,最后得到
,这样就把不同层次的信息组合了起来。
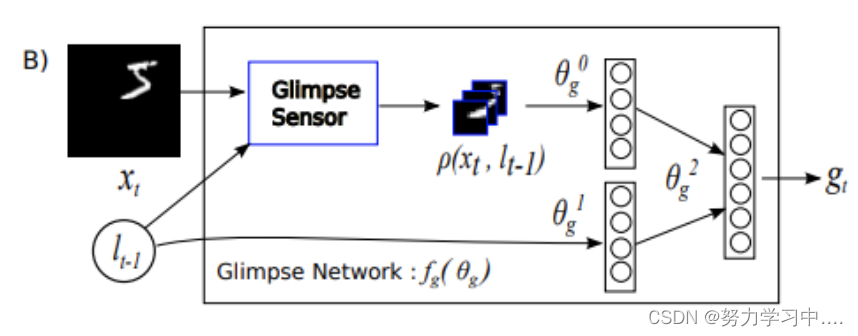
Glimpse Network
给定位置信息
,和输入的图片
用Glimpse Sensor来提取数据
,经过线性表示【也就是经过一个普通的神经网络】得到
,位置信息也经过网络表示【同上】得到
,然后
和
也经过一个线性层,结合两者得到
,Glimpse网络
定义了用来产生glimpse representation
的注意力网络的可训练带宽限制传感器
Action and Location Extractor
输入信息
和前一段隐藏层信息
,通过RNN得到下一阶段输入的隐藏层信息,而隐藏层信息通过
不完全可观察马尔科夫决策过程
(POMDP)得到下状态
, 和下一阶段的位置信息
action和location的提取
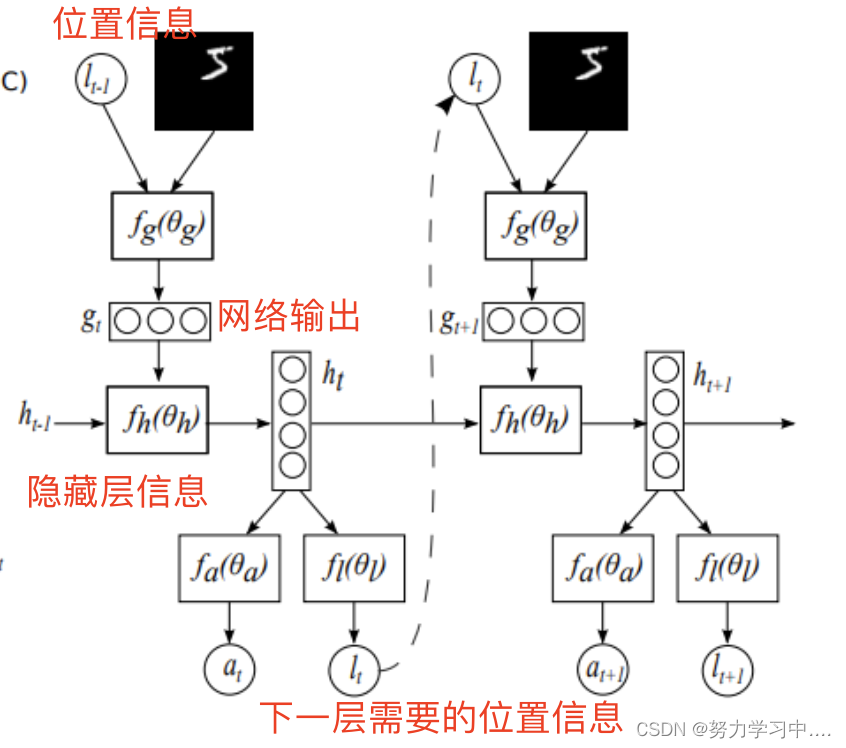
奖罚机制:在执行一次活动之后(意思也就是对一个输入图片,经过这个系统之后得出分类结果),如果分类正确,则判为1,否则判为0
2.
训练
整个模型过程可以看做是一个局部马尔科夫决策过程。
每个阶段的动作和位置只与上一阶段的动作和位置有关
。
即展开RNN结构,以时间为序,整个过程可表示为:
— 在这个分布的条件下最大化我们的奖赏函数;
最大化J不是一件简单的事情,因为这涉及到高维相互序列的期望,可能导致进入未知的环境空间;

神经网络可作为非常好的特征抽取器和函数拟合器,与其他算法结合,训练出更理想的模型。
参考博客:
【Recurrent Models of Visual Attention】(讲解)_David Wolfowitz的博客-CSDN博客
3 注意力机制在在神经机器翻译领域的应用
1. 神经机器翻译主要以Encoder-Decoder模型为基础结构
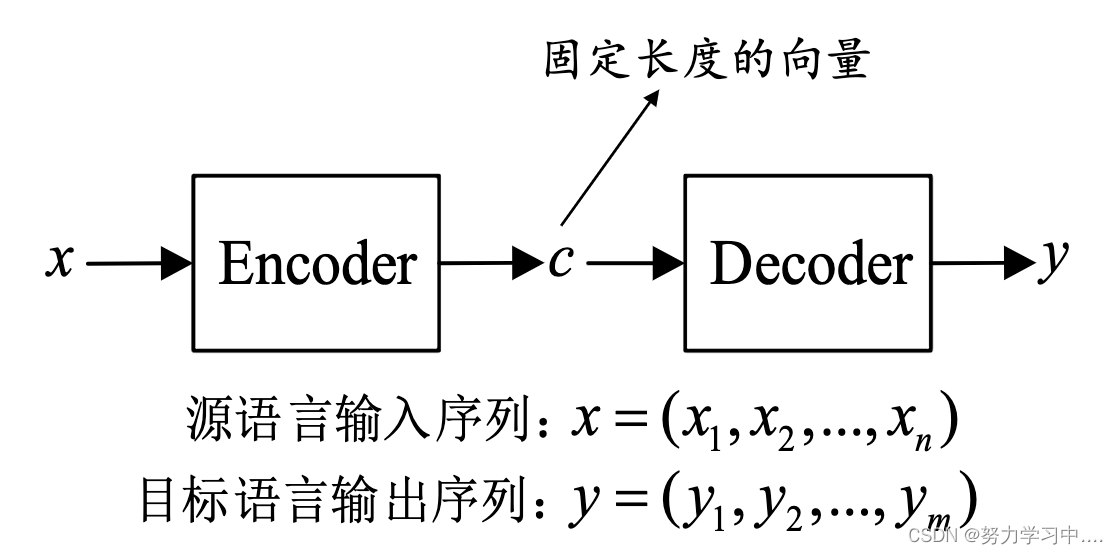
在神经机器翻译中,
Encoder一般采用RNN或者LSTM实现
从统计角度,翻译相当于寻找译句y,使得给定原句x时条件概率最大;
得到上下文向量c的方法有很多,可以直接将最后一个隐状态作为上下文变量,也可对最后的隐状态进行一个
非线性变换σ(⋅)
,或对所有的隐状态进行非线性变换σ(⋅)
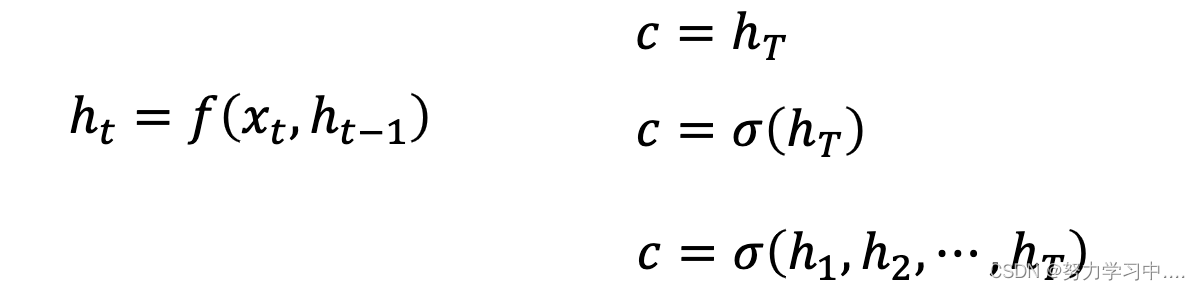
解码器
用给定的上下文向量c和之前已经预测的词
![]()
现存问题:
输入序列
不论长短都会被编码成一个固定长度的向量表示
,而
解码则受限于该固定长度的向量表示
;
这个问题
限制了模型的性能
,尤其是当输入序列比较长时,模型的性能会变得很差;
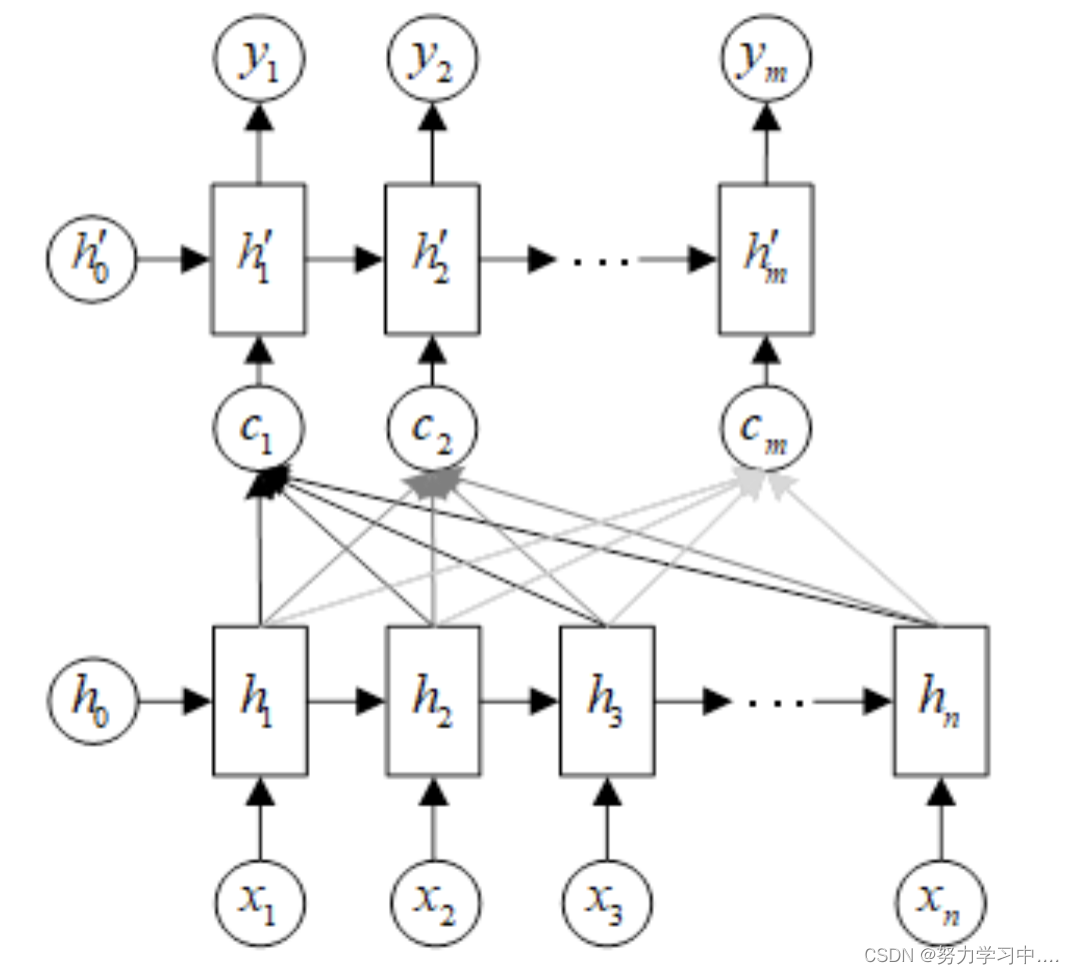
2. 神经网络模型注意力机制
在这个新结构中,定义每个输出的条件概率为:
;
其中
为解码器RNN中的隐层状态:
;
这里的上下文向量
取决于解码器状态序列,通过使用注意力系数
对
加权求得:
注意力系数计算:
— 反映i位置的输入和j位置输出的匹配程度–alignment mode
计算注意力系数的相似函数(alignment model)有以下几种:
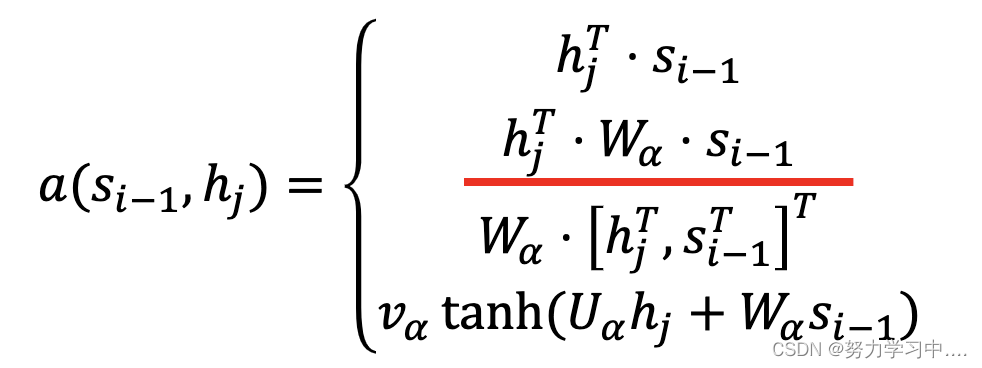
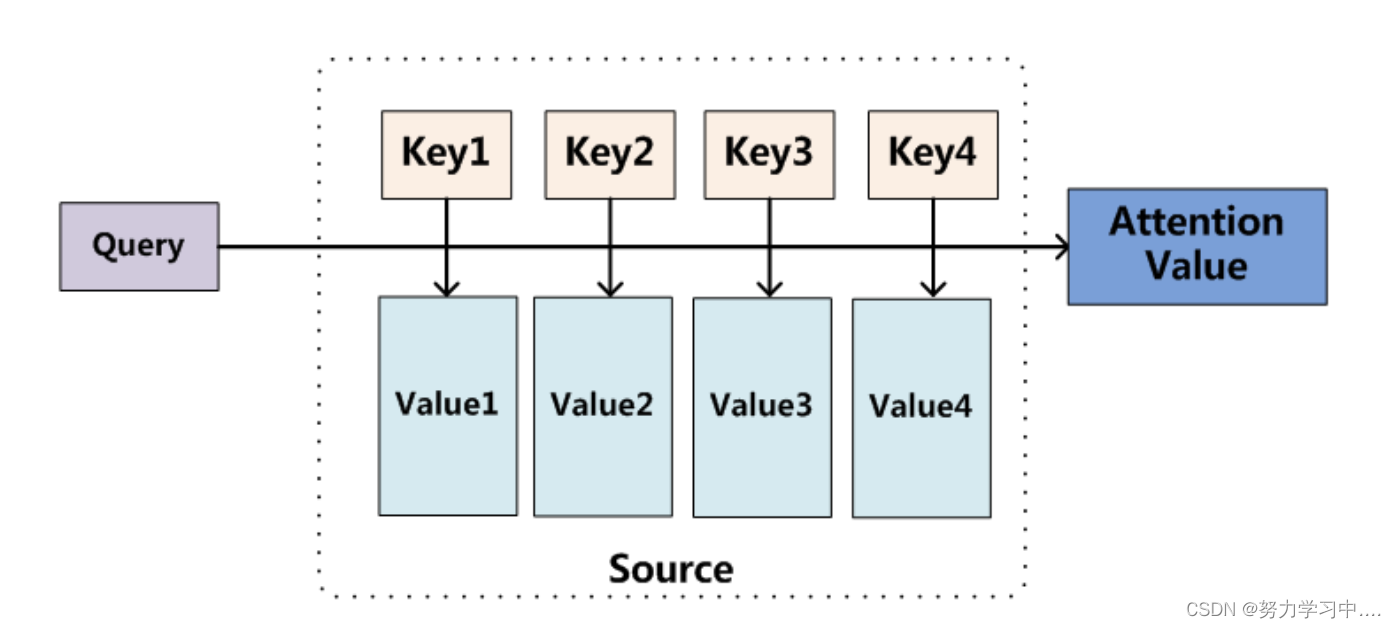
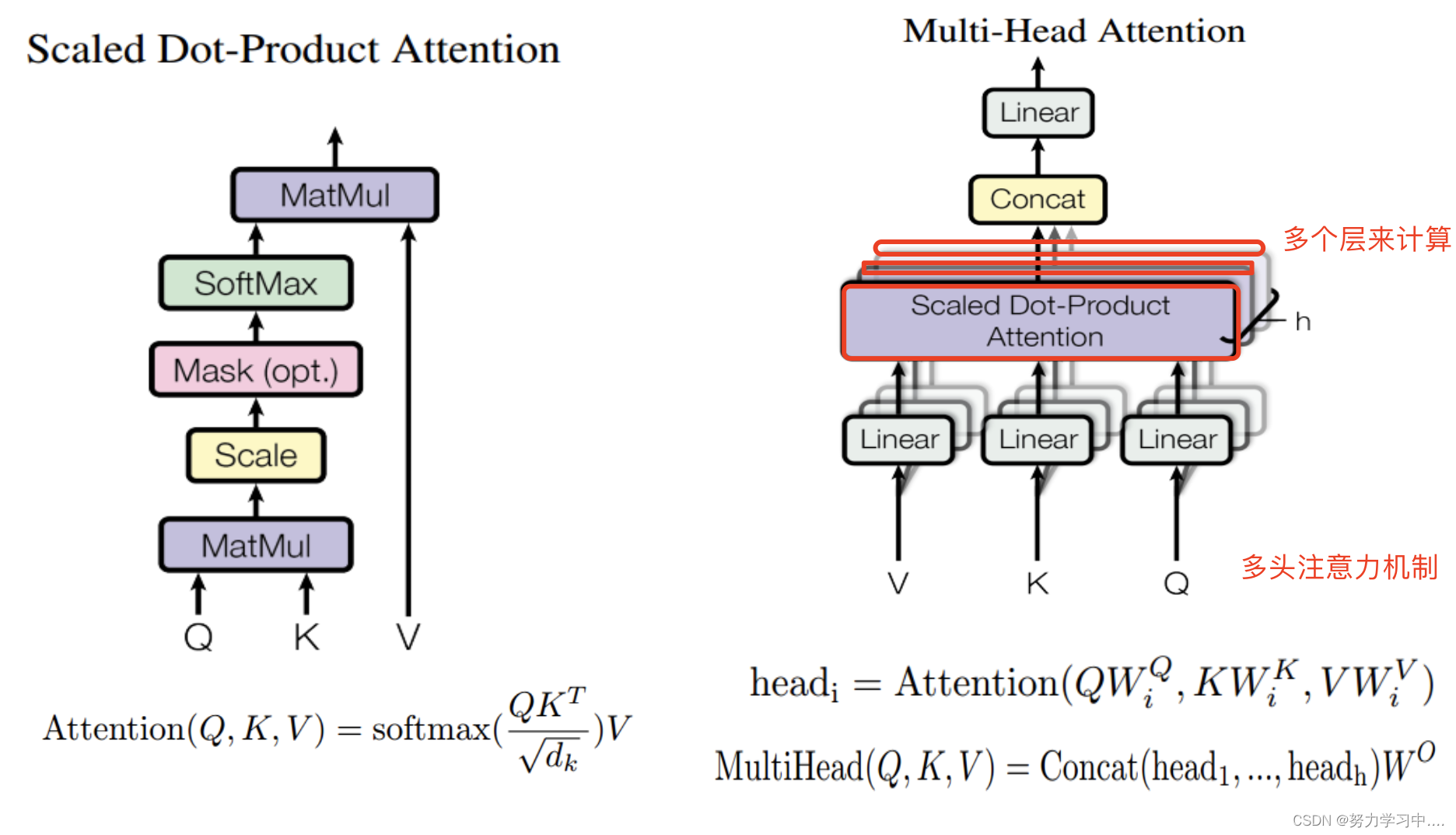
3. 注意力机制的抽象理解
Attention函数的本质可以被描述为
一个查询(query)
到
一系列(键key-值value)
对的映射
这里除以
的目的是:防止QK相乘权重过大,最后归一化后出现梯度很小的情况,当计算出来的值过小则很难训练。
注意力系数计算:
阶段1:根据Query和Key计算两者的相似性或者相关性;
阶段2:对第一阶段的原始分值进行归一化处理;
阶段3:根据权重系数对Value进行加权求和,得到Attention Value;
关于Q,K,V表示含义通俗易懂的例子:
Q就相当于在淘宝中输入查询词汇,比如“裙子”
K就相当于淘宝内部的数据库,有各式各样的词汇与图片;
就相当于计算相似度,根据相似度将与裙子匹配的数据库中的词条找出来 — 但是这还不是相似度,做了归一化才是相似度;
V就是找出来的词条的价值,比如价格、购买量、品牌等,相当于物品的总和价值;
相似度与价值的成绩得到每个物品的应得到分数,然后根据分数进行排序,得到最终的浏览页面顺序。
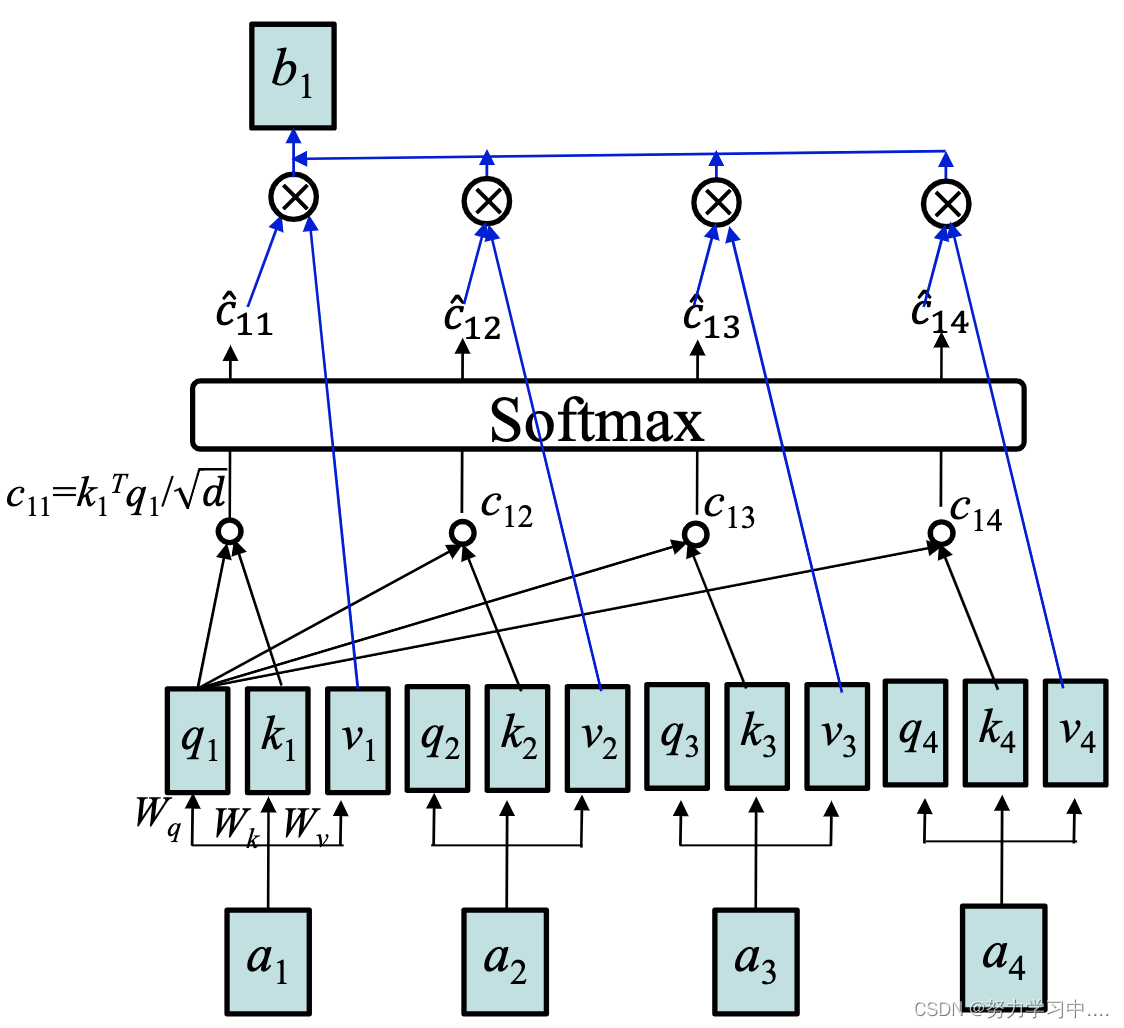
4. 自注意力机制与注意力机制的区别
自注意力机制的QKV都在同一边,比如都在encoder端,或者都在decoder端;
注意力机制的Q,K,V分布在不同端,如Q在Decoder端,而KV在encoder端。
5. 多头自注意力机制与注意力机制区别
注意力机制是只用一组
来与字编码相乘;
而多头注意力机制是使用多组
来与字编码相乘。
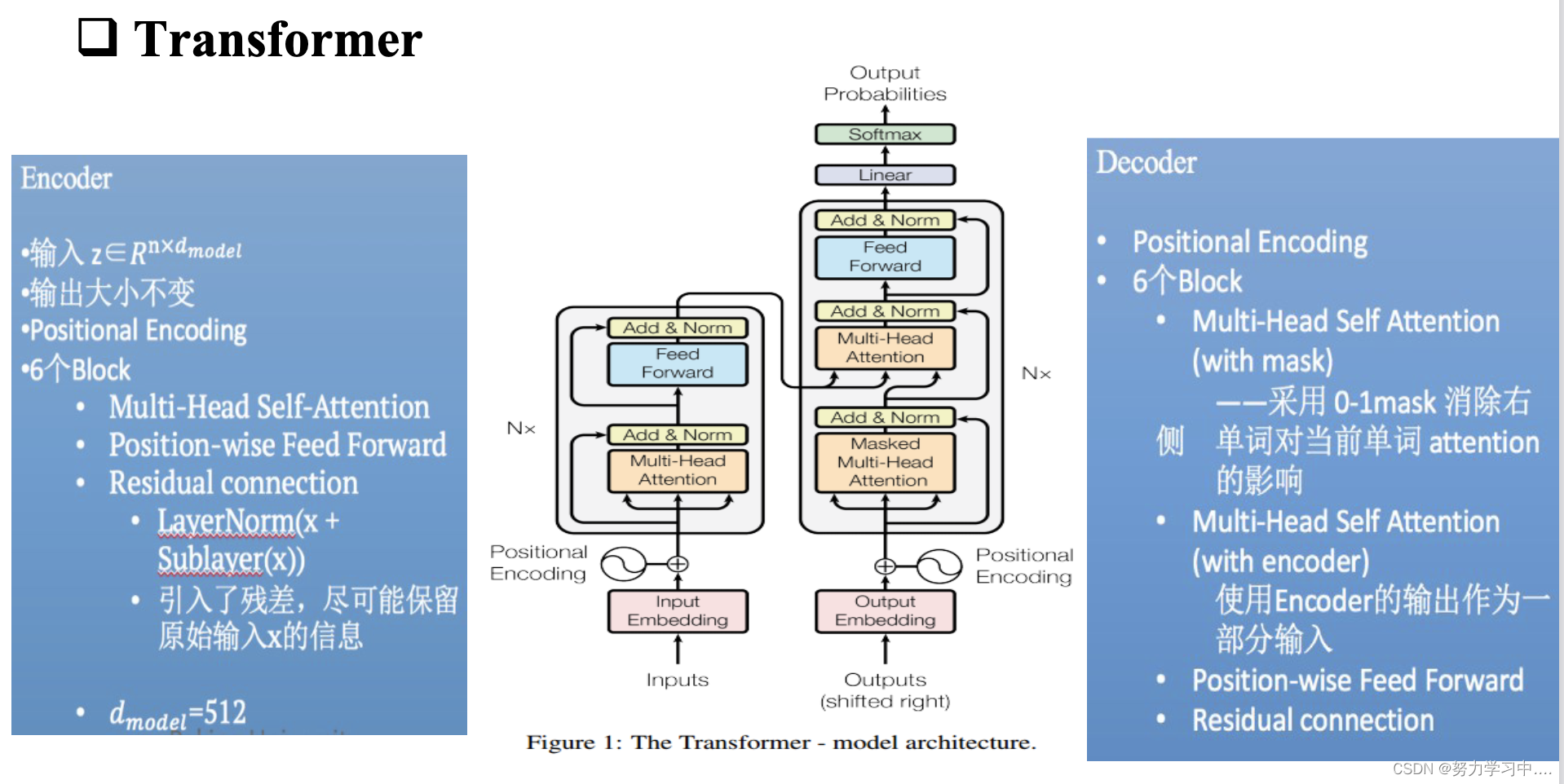
6. Transformer 整体架构
参考: 国科大- 深度学习课件