关注公众号,发现CV技术之美
本文分享 IJCAI 2022 的一篇论文
『GL-RG: Global-Local Representation Granularity for Video Captioning』
,由复旦&西湖&Meta AI等研究机构提出GL-RG模型,建模Video Captioning的全局-局部表示粒度!SOTA代码已开源!
详细信息如下:

-
论文链接:https://arxiv.org/abs/2205.10706
-
项目链接:https://github.com/ylqi/GL-RG
01
摘要
视频字幕(Video captioning)是一项具有挑战性的任务,因为它需要将视觉理解准确地转换为自然语言描述。到目前为止,最先进的方法无法充分模拟视频帧中的全局-局部表示以生成字幕,因此还有很大的改进空间。
在这项工作中,作者从一个新的角度来处理视频字幕任务,并提出了一个用于视频字幕的GL-RG框架,即全局-局部表示粒度。与之前的工作相比,本文的GL-RG显示出三个优势:1)作者明确地利用来自不同视频范围的广泛视觉表示来改进语言表达;2) 作者设计了一种新的全局编码器来产生丰富的语义词汇,以获得跨帧视频内容的描述粒度;3) 作者开发了一种增量训练策略,该策略以增量方式组织模型学习,以产生最佳字幕。
在具有挑战性的MSR-VTT和MSVD数据集上的实验结果表明,本文的DL-RG比最新的方法有显著的优势。
03
Motivation
视频字幕(Video captioning)具有很大的社会相关性,在许多现实世界的应用中都有价值,包括字幕生成、盲人辅助和自动驾驶仪叙事。然而,孤立的视频帧可能会出现运动模糊或遮挡,这会给字幕任务的视觉理解带来很大的混乱。因此,迫切需要回答一个主要问题:如何利用好视频中的跨帧连贯性和单帧信息来缩小视觉理解与语言表达之间的差距?
尽管取得了重大进展,但现有的视频字幕方法无法充分捕捉局部和全局表现。各种研究将深度神经网络应用于原始像素,以建立更高层次的联系。这些方法侧重于局部对象特征,但忽略了对象变换或交互。对局部对象特征进行建模是视频字幕的一种原始解决方案,因为帧之间的时间连接没有仔细研究。
为了研究全局-局部相关性问题,其他相关视觉任务利用图神经网络(GNNs)的图表示。然而,实验结果表明,目前视频字幕中使用图表示全局-局部相关性是次优的,因为它在训练中经常遇到过度平滑问题,导致推理过程中的结果较弱。许多视频字幕方法直观地利用多模态融合(即视觉或音频特征)来丰富预测中的特征表示。然而,这些简单的方法无法充分利用多模态特征,难以跨模态执行联合优化,留下了很大的改进空间。

为了解决上述问题,作者尝试以更灵活的方法解决视频字幕问题,该方法利用全局-局部视觉表示粒度。具体而言,本文的贡献如下:
-
作者设计了一个称为GL-RG的简单框架,即全局-局部表示粒度,该框架对广泛的视觉表示进行建模,并基于不同范围的视频内容生成丰富的词汇特征。
-
作者提出了一种新的全局局部编码器,它利用丰富的时间表示进行视频字幕。编码器对长距离帧进行联合编码以描述时空对应关系,短距离帧用于捕获对象运动和趋势,局部关键帧用于保留内部对象外观和位置细节(如上图所示)。
-
作者引入了一种增量的两阶段训练策略。在第一个阶段,作者设计了一个用于非强化学习的区分性交叉熵,它解决了人类标注差异的问题。在第二个增强阶段,作者为强化学习调整了差异奖励,它稳定地估计了每个视频的预期奖励偏差。
-
作者在MSR-VTT和MSVD数据集上评估了本文的方法。大量的实验结果表明,本文的方法优于SOTA,并且使用更短的训练时间。
03
方法
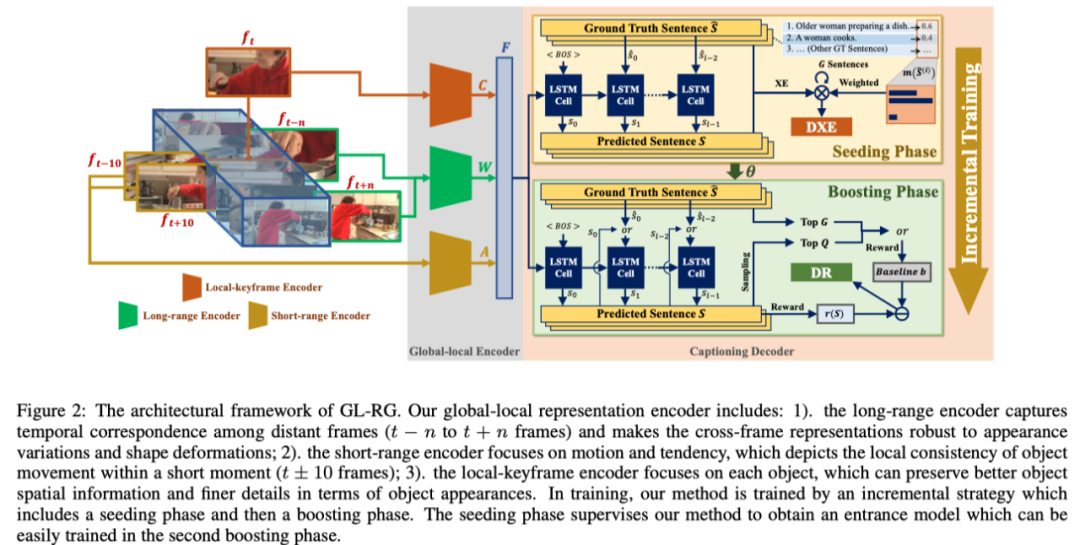
3.1 Overvie
GL-RG的框架如上图所示。GL-RG还采用了编码器-解码器架构。更具体地说,GL-RG包括一个全局-局部编码器和一个字幕解码器。全局-局部编码器选择不同范围的帧作为输入,并将其编码为不同的词汇表特征。将获得的所有特征聚合在一起,以丰富跨视频帧的全局-局部视觉表示。然后,在增量训练策略的监督下,字幕解码器将词汇特征翻译成自然语言句子。
3.2 Global-Local Encoder
本文的全局局部编码器包括三个基本部分:长距离编码器、短距离编码器和关键帧编码器。
Long-range encoder
作者对随机全局视频帧进行编码,以生成基于随机关键帧训练的全局词汇表。本文的训练迭代将使整个视频片段完全饱和,因为每个迭代将从视频中随机选择不同的帧(总数固定)。本文的远程编码器首先对输入进行2D卷积,以识别相关的上下文特征。第一步的输出特征由3D卷积网络(CNN)处理,以获取全局时间对应关系。作者从ground truth句中选择最常用的K个单词(频率最高),作为K分类任务指导词汇生成。dense层的输出定义为:
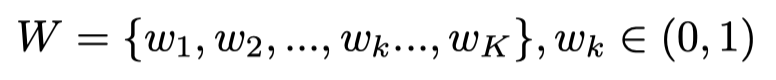
其中,W是预测的long-range词汇的集合。因为W包含了从ground truths中选择单词的所有可能性,它可以提供视频中时间内容的描述。
Short-range encoder
本文的短程编码器用于捕捉物体的运动和趋势。具体而言,同时采取关键帧的两个近邻(和),2D CNN和3D-Resnet18分别产生语义和运动表示。之后,这些表示被堆叠并输入到密集动作分类层中。给定在Kinetics-400、UCF101或HMDB数据集中中J个最高频率的动作,本文的短程编码器输出如下:
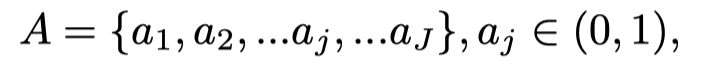
其中A是的集合,是动作数据集中第j个动作的预测置信度。
Local-keyframe encoder
局部语义的词汇知识是通过残差网络学习的,残差网络从关键帧中提取显著的对象特征。鉴于图像分类数据集中的图像类数(如ImageNet)为M,局部编码器的输出为:
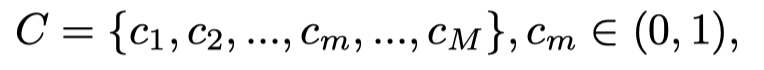
其中C是的集合,是该局部帧第m类的预测置信度。
一旦获得了来自不同范围的所有词汇表特征,模型将执行融合编码。首先使用由线性层构成的特征池,将每个词汇特征投影到相同大小的嵌入中,然后将它们聚合在一起,生成融合特征F:
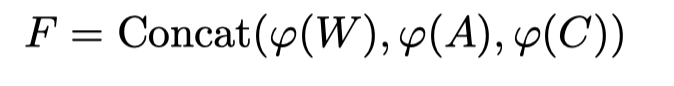
3.3 Captioning Decoder
本文的字幕解码器将融合的特征转换为l个字的序列来组成预测句。具体而言,作者在第i步使用LSTM生成隐藏状态和单元状态:
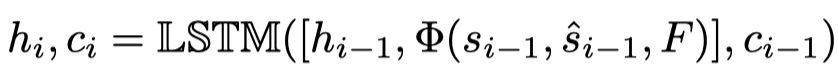
其中[·,·]表示concatenation。分别是先前隐藏状态、预测词、ground truth、编码融合特征和cell状态。是使用前面的每个token来预测下一个单词的方案。作者采用时间表抽样技术随机选择token或使用随机变量:
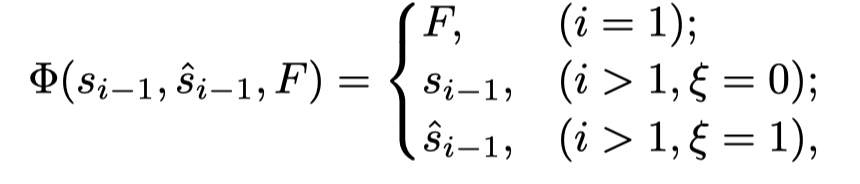
当i=0时,LSTM的初始输入为融合特征F;当i>1时,在每个epoch中逐渐增加ξ=1的概率,直到ξ绝对等于1。然后,作者通过降低ξ=1的概率来对抗这个过程。
因此,预测词的概率为:
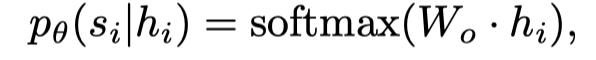
其中是隐藏状态,是将隐藏状态映射到词汇大小嵌入的权重矩阵,以便在句子中找到上下文匹配的单词。
3.4 Incremental Training
本文的增量训练包括一个seeding阶段和一个boosting阶段。这两个训练阶段将实现不同的学习目标。seeding阶段旨在生成入口模型,以促进第二阶段的顺利训练,而boosting阶段则利用强化学习(RL)来提高性能。
Seeding phase
现有模型通常使用交叉熵(XE)损失进行训练,该损失衡量生成句子和所有Ground Truth句子的平均相似度。由于不同的标注者可能会以不同的方式解释视频内容,因此来自训练数据集的Ground Truth值可能包括注释偏差。作者认为,字幕预测与真实情况之间的直接比较不能产生最佳的训练结果。因此,作者在计算交叉熵时使用所有Ground Truth的度量分数作为区分权重,以使训练偏向于那些写得很好的Ground Truth。可以使用不同的选项,如BLEU-4、METEOR、ROUGE-L和CIDEr。
如果每个视频都由G个标注句子,则discriminative cross-entropy(DXE)损失函数为:
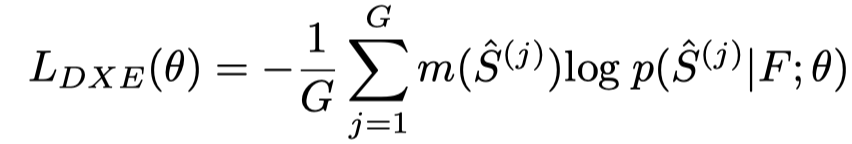
其中,可以被视为一个常数,用每个句子和ground truth的指标计算。
与加权损失熵(手动为所有类别分配权重以解决数据不平衡的问题)不同,DXE的权重是通过度量自动计算的,用于评估所有标注的质量。本文的DXE为高质量标注分配了更高的权重,帮助模型生成更接近它们的字幕。
Boosting phase
在Seeding阶段之后,作者使用discrepant reward(DR)的强化学习来进一步提高GL-RD模型的性能。为了优化模型参数θ,使用强化学习的传统方法在训练中执行不可微的reward:
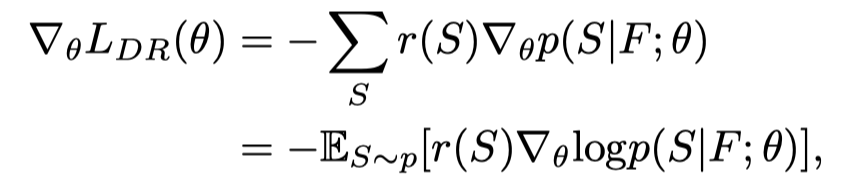
其中表示分布的期望值,reward是采样句子的评估度量分数,F是从全局-局部编码器中提取的融合特征。这种训练策略的一个问题是,奖励函数总是正的,因为度量分数在0到1之间。因此,只能在学习中鼓励特征表示,而不能进行抑制。
为了解决这个问题,本文的DR等于原始奖励r(S)减去偏差b,其中b是baseline。有了偏差项,模型的学习可以对预测中的变化更加稳健。那么强化学习策略梯度可以定义为:
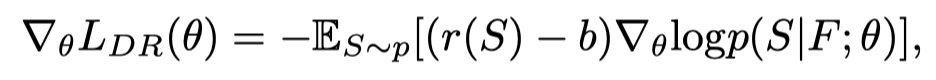
其中,。之前的SCS利用测试时greedy输出的回报作为baseline ,代价是在每次训练迭代中再次运行推理。在本文的实现中,baseline b有两个变体:1、:由G个Ground Truth字幕获得;2、:在前一步中,由得分最高的模型抽取的前Q句。baseline(或)都可以减少梯度的方差,而不会改变梯度的期望值,因为。更新梯度时,此梯度可以通过单个训练样本的蒙特卡罗采样来近似。因此,reward的最终梯度是:
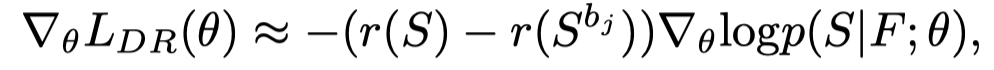
04
实验
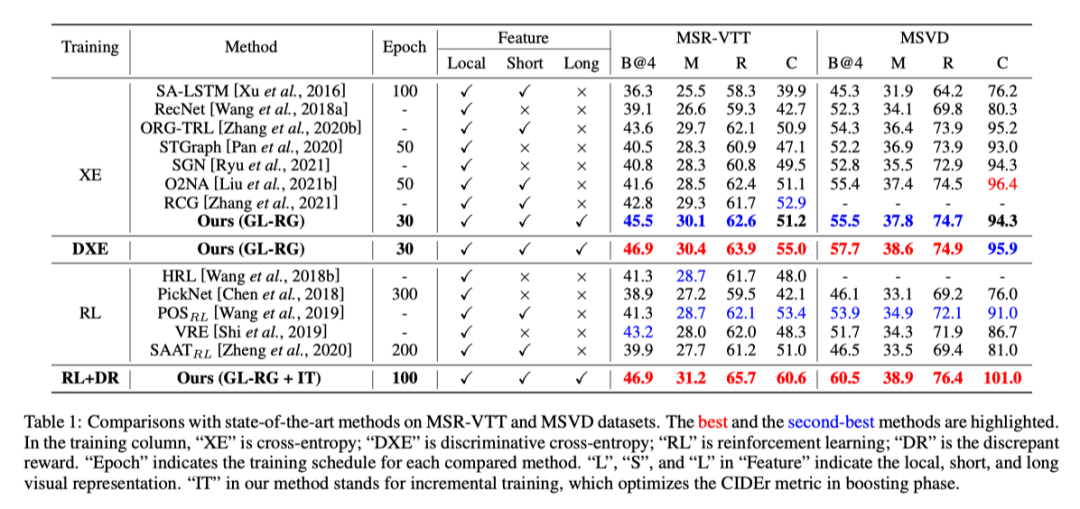
MSR-VTT和MSVD数据集的评估结果如上表所示。通过更短的训练时间,本文的方法可以实现与其他最先进方法不相上下的表现。经过充分训练的模型在所有指标上都超过了所有比较的方法。

上图展示了MSRVTT数据集上的一些定性结果。
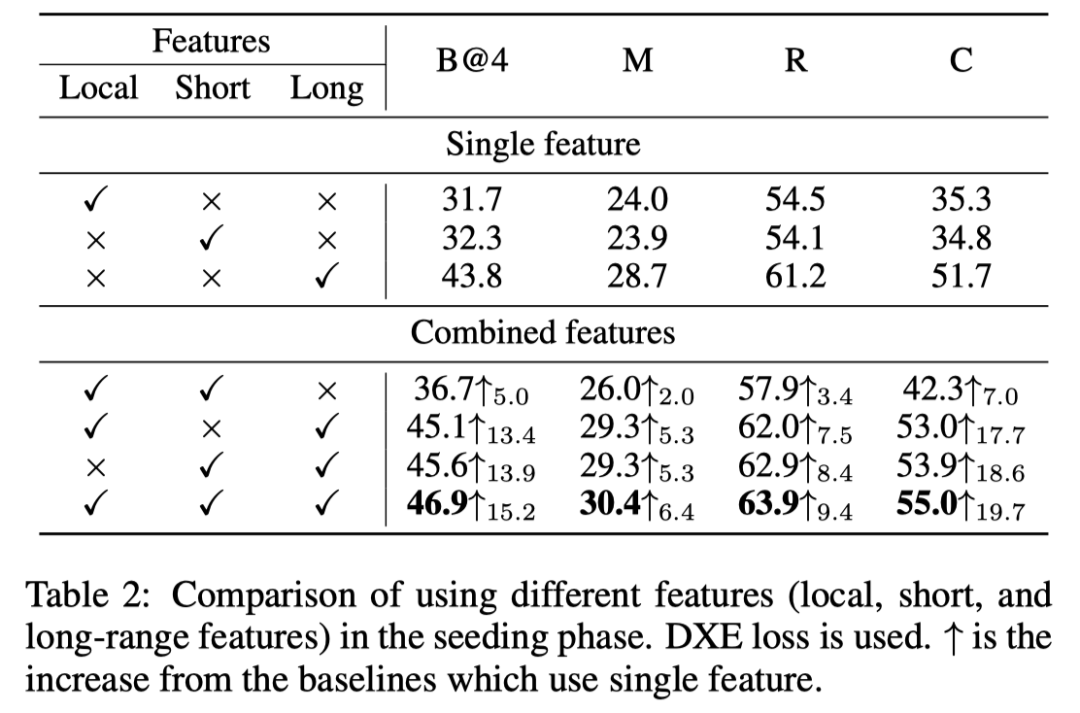
作者使用不同的全局-局部特征来衡量模型的性能(见上表)。在表格的上半部分,作者评估了使用单个特征进行字幕预测的不同方法的性能。结果表明,使用long-range特征在所有指标上都具有最高的性能。在表格的下半部分中,作者检查了不同特征渐进式组合的影响,可以发现使用这三个特征的完整模型优于所有其他同类模型变体。
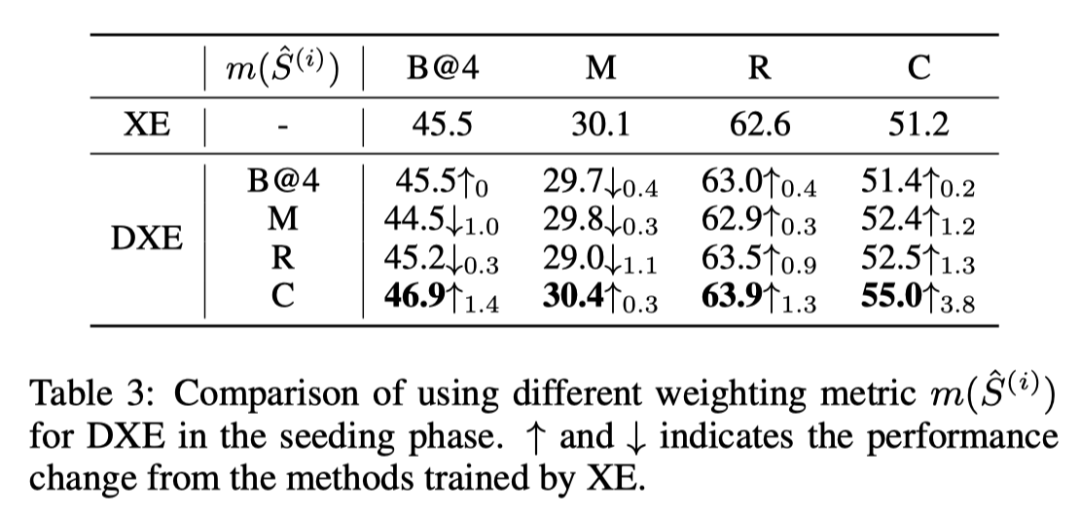
Seeding阶段的训练很重要,因为它为接下来的Boosting阶段生成入口模型。因此,在上表中,作者评估了使用不同加权指标进行训练。
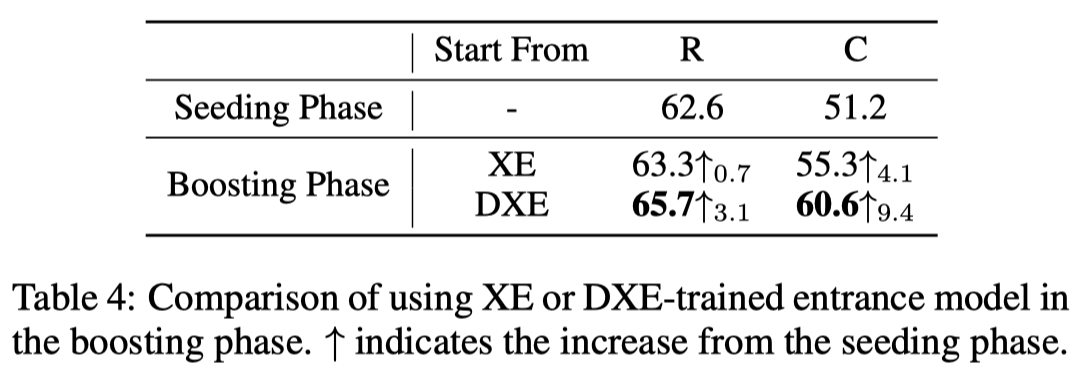
作者评估了增量训练是否可以有效地提高本文的方法性能。上表显示了从Seeding阶段开始稳定增加的Boosting阶段的结果。
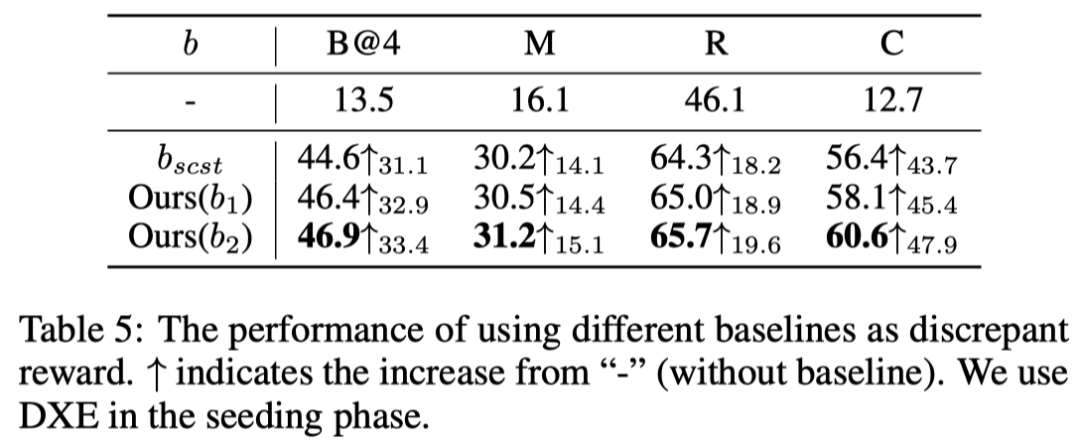
上表显示了与相比,使用不同差异(和)reward的模型的结果。
05
总结
视频字幕是一个重要的研究课题,具有多种下游应用。在本文中,作者提出了一个用于视频字幕的GL-RG框架,该框架利用全局局部视觉表示,通过增量训练策略实现视频内容的细粒度字幕。在两个基准上的实验结果证明了本文方法的有效性。
参考资料
[1]https://arxiv.org/abs/2205.10706
[2]https://github.com/ylqi/GL-RG

END
欢迎加入「
视频字幕」
交流群?备注:
VC
