
【从零开始学机器学习第 11 篇】
摘要:
通俗易懂介绍线性回归算法,并 Python 手写实现。
之前我们介绍了:kNN 算法,主要用于解决分类问题,也可以解决回归问题,它有很多优缺点,其中一个缺点是模型结果不具有可解释性,而很多时候我们是希望得到的模型是能够作出合理解释的,以便指导业务。今天要介绍的
线性回归(Linear Regression)模型就是一个很好的可解释模型
。
比如建立了一个关于房价和房屋面积的线性回归模型:y(房价)= 15000*x(房屋面积)+ 100
就可以解释成:房屋面积每增加一平米,房价就会增加 15,000 元。
除了这个优点以外,线性回归还有一个重要的优点是它是很多机器学习算法的基础,比如之后会介绍的多项式回归、逻辑回归、svm。通常在建立复杂的模型前都会先尝试一下线性回归模型,所以很有必要学好它。
相比与 kNN 模型,我们更熟悉线性回归,因为它和初中学过的一元函数
y = k*x + b
很像,算法思想也比较简单,仅多了一点数学公式推导。
下面依然通过一个小场景切入该算法:
01 场景代入
小花是一家房屋中介销售员,一天有个客户打电话过来说,想卖掉自己一套 80 平米的房子,问小花这边能报价多少。小花说稍后给客户报价,放下电话后赶紧查看过往房屋销售记录,想从中找个参考价格,但发现此前并没有接手过 80 平米的房子,便一下犯了难不知道报多少合适:报高了自己吃亏,报少了客户可能去别家。
作为小花的同事,你把一切看在眼里,善解人意地问她是否需要帮忙,她如找到救星一般,一边点头一边抓住你的手,拜托你给她个参考价出来。你不慌不忙拿出纸笔,一顿狂算后给了小花一个答案:125 万,在这个基准价上可以再适当调整。
小花告诉了客户后很顺利地拿下这一单。走到你跟前抛来崇拜的眼神,说下班要请你吃饭,你口头忙说不用客气心里却万马奔腾。下了班小花带你去了一家她和闺蜜常去的店,还专门点了瓶红酒。喝到微醺恍惚之时,你发觉不知什么时候小花坐到了你身边,你面红耳赤小心脏扑通直跳,不敢想接下来会发生什么,只好装懵闭上了眼睛。只感觉小花越来越近,近到快贴到耳根边,感觉要发生点什么的时候,听到她飘来一句:
那个房自你为什么确定报价 125 万?
你睁开眼发现小花坐在对面认真地在等你的回答,才发觉刚才是自己在 YY,只好抛出一句自己的口头禅来化解尴尬:
无他,唯机器学习熟尔。
段子编完了。。。
02 线性回归解释
下面我们就
用线性回归来解决为什么 80 平米的房报价
125 万
这个问题。分为两步:抽象出线性回归模型,接着 Python 手写代码预测结果。
由于小花手上只有一组少量的房屋成交记录,这组记录由房屋面积和报价两列数据组成(为了建模而作的简单假设),因此,我们可以将其绘制到坐标轴中(横轴是房屋面积,纵轴是房价),如下面红点所示:
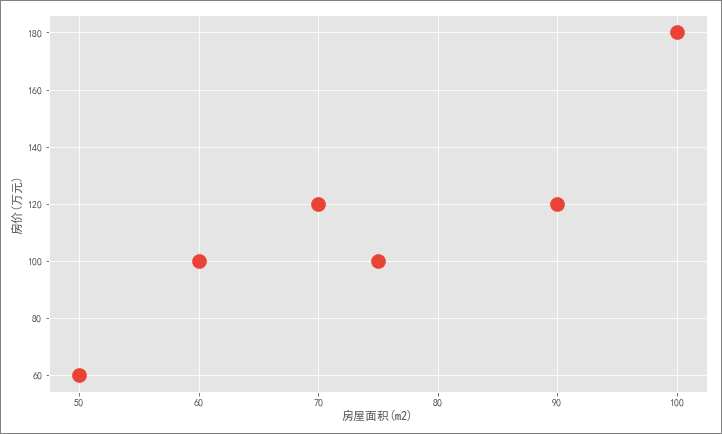
现在,需要根据这组数据去给客户 80 平米的房子预测出一个合理价格。显然,仅凭这几个散点找不到任何规律,房价可以假设成很多值:
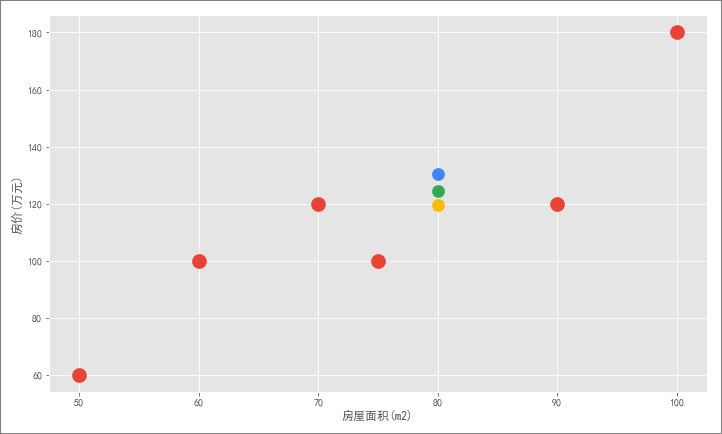
不过,我们看到房价和房屋面积呈现一定的线性关系,于是自然地想到是否可以
画出一条直线,能够最大化地拟合住所有红色样本点。
这条直线能够代表样本的总体规律,从而可以建立一个线性方程:y = ax + b,将 x = 80 代入该方程就可以得到最合适的房价:
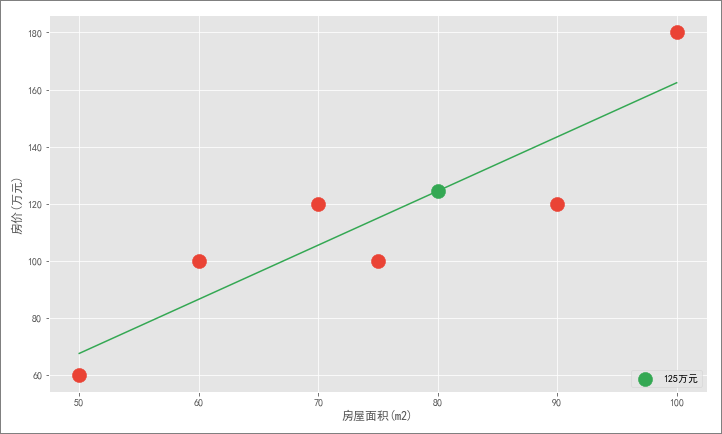
不过新的问题来了,如何确定这条直线就能够最大化拟合红色样本点?因为可以画出很多这样的直线:
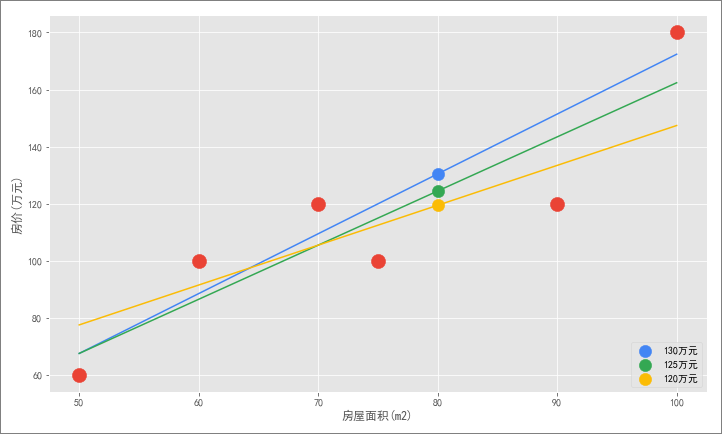
可以这样来想:图中每个样本都有预测房价和实际房价,且每条直线的预测房价不尽相同,那么可以使用这一个方法来
判断直线拟合程度的好坏
:
计算各直线上全部样本点的实际房价和预测房价的差值,求出它们的总和,对比哪条直线的总和最小,就认为该条直线拟合效果最好。
不过差值有正有负,为了避免相互抵消,可以换成计算差值的平方和:
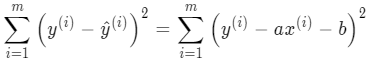
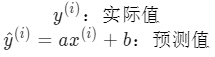
这个平方和计算公式也叫
损失函数(loss function)
,损失的意思就是指没有拟合到真实值的部分。
另外,这里的未知数不再是 x 和 y (x y 都是已知样本值)而是斜率 a 和 截距 b,相当于是关于 a 和 b 的二次方程。我们知道它是一条抛物线,有最小值。
所以,我们的
目的从找到一条最大化拟合住所有红色样本点的直线,转变成找到一条损失函数值最小的直线
。
寻找这条直线显然不能靠手动划线去找,因为穷举不完。可以换个思路:
求出该损失函数的最小值,反解出未知数 a 和 b,就可以找到这条直线。
如何求该函数的最小值呢?这就可以用到中学学过的函数求导来解决,让导函数等于 0 就能找到函数最小值。
到这儿,我们的
找直线问题最终变成了数学求导
。
求导不难高中数学知识就够,下面来一步步写下:
03 线性回归公式推导
为了方便求导,令该损失函数等于 J(a,b),分别对 a 和 b 求偏导,令其等于 0 求解 a 和 b 的值:
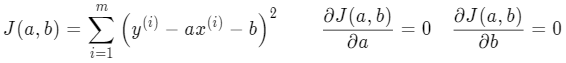
b 的形式简单些,所以先对 b 求导:
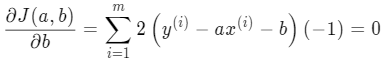
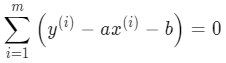
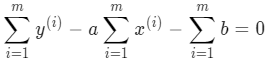
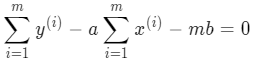
很容易就能求出 b 的值:
y 的均值减去 a 乘以 x 的均值
:
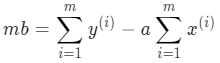
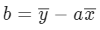
由于,我们已有全部样本点的 x 和 y 值,所以均值很容易计算,只需要求出 a。
下面来推导 a ,会稍微复杂点:
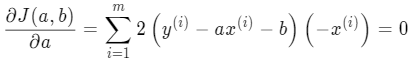
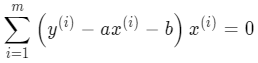
把 b 代入:
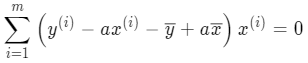
分别乘入 x^{(i)}:
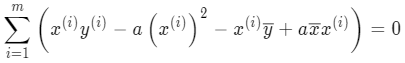
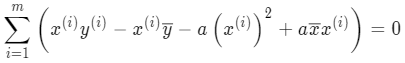
将 a 整理合并:
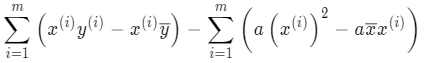
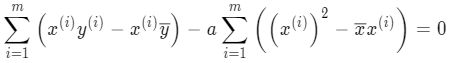
最后就能求出 a:
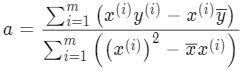
不过该公式略复杂,还可以进一步整理让 a 跟 x 和 y 的均值产生联系。对分子第二项做变换:
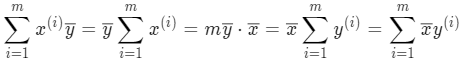
变换后,发现 x 和 y 对调后上式也成立,接着再从另一个角度变换:
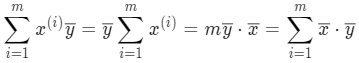
这样就可以对 a 的表达式做替换,分子和分母都加一项再减去相等的一项(等于没加没减):
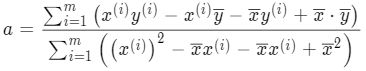
凑成这样的形式是为了变换:分子可以合并因式分解项,分母可以写成完全平方公式:
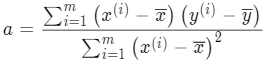
到这里, a 和 b 的计算公式就都和 x 和 y 的均值产生联系,很容易能求出来:
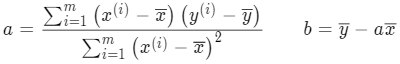
数学公式推导出来后,简单的几行 Python 代码就可以计算出 a 和 b,有了 a 和 b 就能解出直线 y 的表达式,从而绘制出前面的最佳拟合直线。
04 Python 手写线性回归
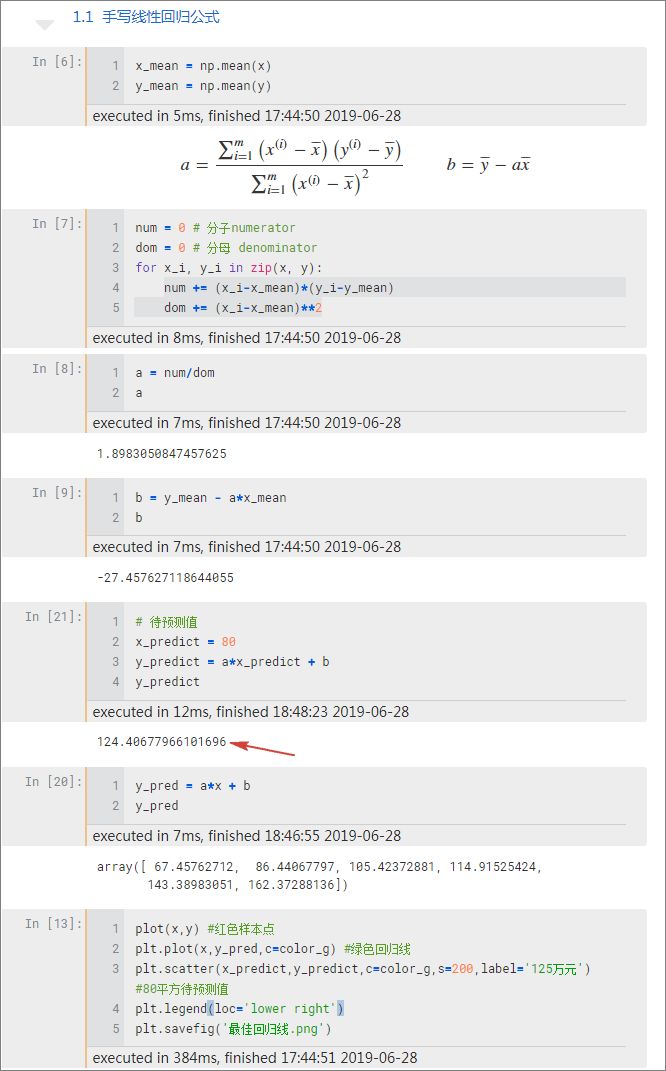
可以看到,数学是编程的基础很重要,如果觉得推导过程难可以不用管它,只需记住 a 和 b 的表达式就可以编程实现。
到这儿我们介绍了线性回归算法,并用简单的 Python 代码实现了它,解决了房价为什么是 125 万的问题。
进一步地我们还可以像调用 sklearn 库一样,把这些代码封装成一个名为 SimpleLinearRegression 的库方便快速调用:
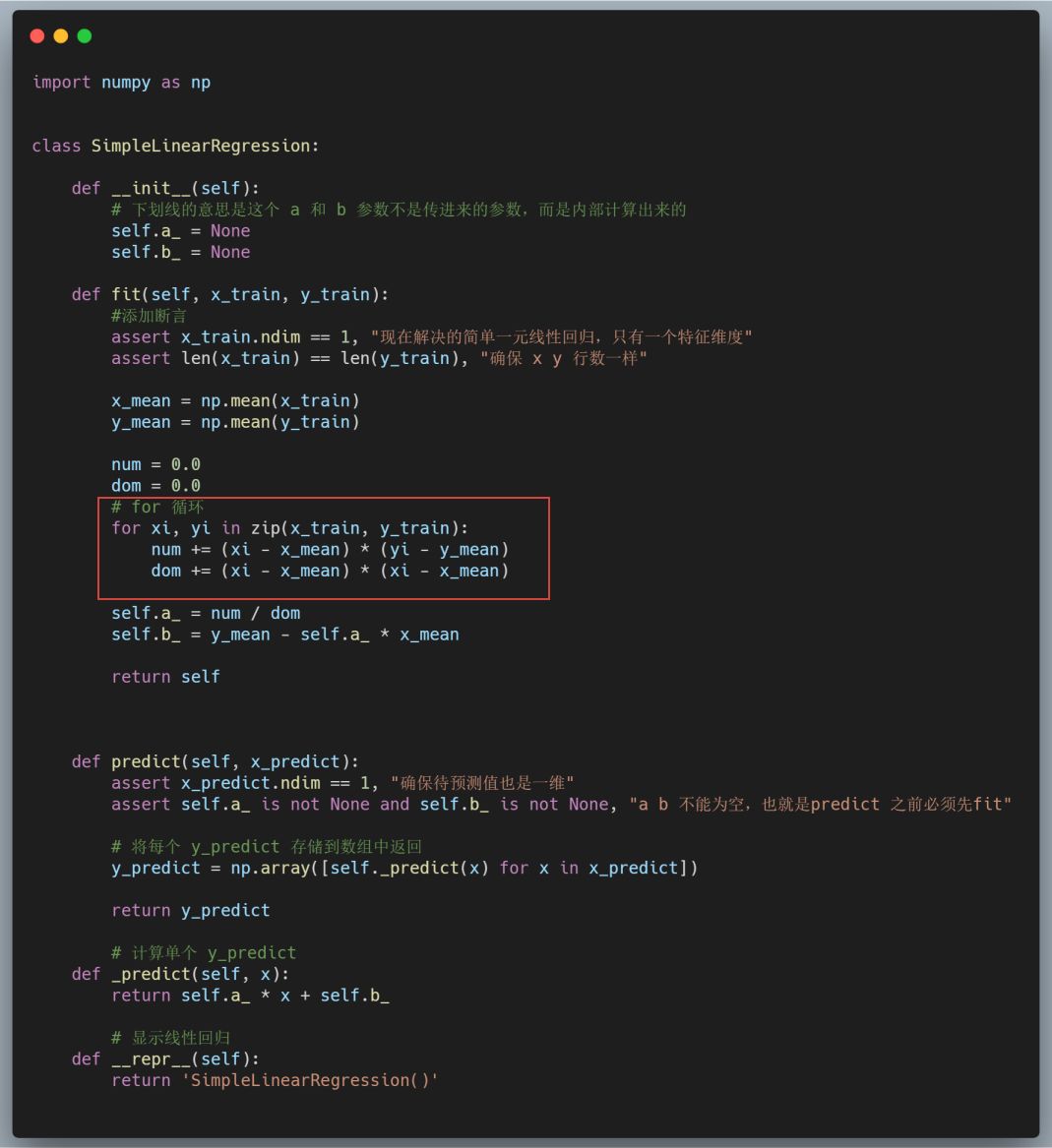
上面这些代码是模仿 sklearn 底层编写的,写好后在 jupyter notebook 中就可以调用该类方法:
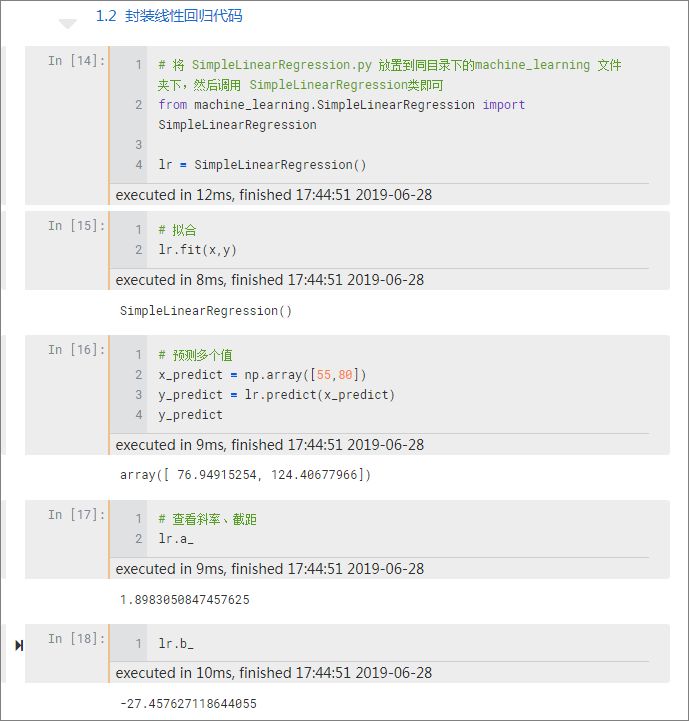
可以看到我们得到了一样的 a 和 b 以及房价,初步完整地实现了线性回归算法代码。
不过发现了一个问题就是前面在计算斜率 a 的值时,使用了 for 循环这种低效率计算方法,当数据量很大时算法运行会变慢。
那么有什么优化方法么?有的,就是使用:
向量化运算,它可以将算法运行效率提升一到两个数量级。
下面具体介绍下如何使用向量化运算改进,只需要两行代码。
05 向量化加速线性回归运算
我们换个角度来看上面的斜率 a 计算公式,可以
把 a 的分子和分母都看成是两个向量 w v 的每一个元素相乘再相加
:
即分子分母都看成是这样的形式:
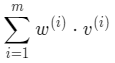
这里的 w 和 v 向量都有 m 个元素:
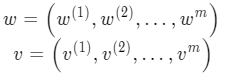
其实向量相乘再相加,就是向量的点积公式
即:
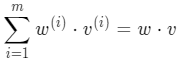
这样就可以不用 for 循环而直接用 numpy 的向量点积公式 np.dot 计算分子分母的值:
# np.dot 向量化计算分子分母 num = (x-x_mean).dot(y-y_mean)dom = (x-x_mean).dot(x-x_mean)
num = (x-x_mean).dot(y-y_mean)
dom = (x-x_mean).dot(x-x_mean)
进而求出 a 和 b:
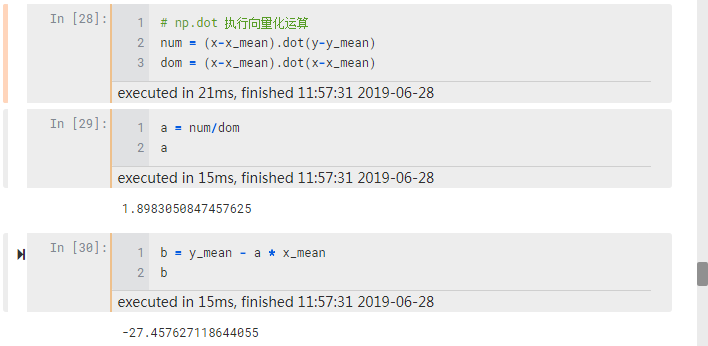
可以看到,a 和 b 的值和 for 循环结果相同,两行代码就解决了。
刚才说当数据量很大时,for 循环计算效率很低,而向量化运算则会快很多,由于我们例举的数据集很小所以体现不出二者性能区别。下面重新生成一个 100 万的大数据集测试一下:
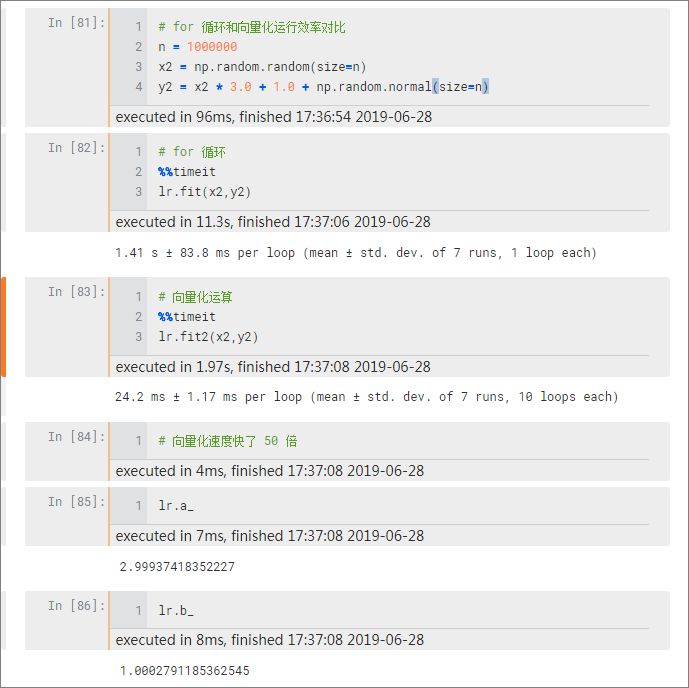
上面模拟生成了一个在 y = 3*x + 1 直线附近的数据集,首先使用 for 循环拟合(lr.fit),程序平均运行时间在 1.41s,接着使用向量化拟合(lr.fit2),平均运行时间只有 24.2 ms,二者相差了
50 倍
!性能差距很大。
所以,
线性回归算法实现时尽量使用向量化运算这种方式
。
06 调用 sklearn 线性回归算法
最后,我们来熟悉使用下 sklearn 中的线性回归算法,只需要 5 行代码:
from sklearn.linear_model import LinearRegression lr = LinearRegression()lr.fit(x,y)x_predict = np.array([55, 80])y_predict = lr.predict(x_predict)# [out]: array([[ 76.94915254], [124.40677966]])import LinearRegression
lr = LinearRegression()
lr.fit(x,y)
x_predict = np.array([55, 80])
y_predict = lr.predict(x_predict)
# [out]:
array([[ 76.94915254],
[124.40677966]])
从 sklearn 的 linear_model 方法中调用线性回归库 LinearRegression,实例化之后在训练集(x,y)上 fit 拟合,然后在预测集上 (x_predict) 预测得到 y 值(预测房价),结果和我们刚才手写的一样。
sklearn 库调用起来很简单,但是只有自己动手去写一遍才能更深刻理解该算法。
以上就是线性回归算法的第一篇文章,算法介绍完了我们还需要知道如何评价其效果好坏,下一篇文章将介绍线性回归的几个评价指标。
本文的 jupyter notebook 代码,可以在公众号后台回复「
LR1
」得到,加油!
推荐文章阅读