神经网络语言模型
1.NNLM的原理
1.1 语言模型
-
假设
S
表示某个有意义的句子,由一串特定顺序排列的词
w1
,
w
2
,
.
.
,
w
n
w_1,w_2,..,w_n
w
1
,
w
2
,
.
.
,
w
n
组成,
n
是句子的长度。目的:计算
S
在文本中(语料库)出现的可能性
P
(
S
)。

1.2 神经网络语言模型
-
直接从语言模型出发,将模型最优化过程转化为求词向量表示的过程.

2. NNLM的网络结构
2.1 NNLM的结构图
-
NNLM网络结构包括输入层、投影层,隐藏层和输出层
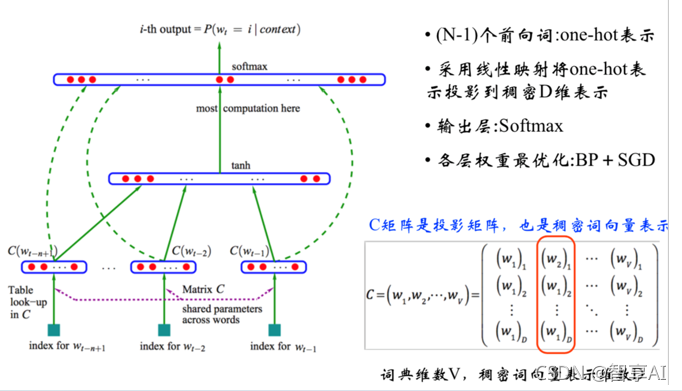
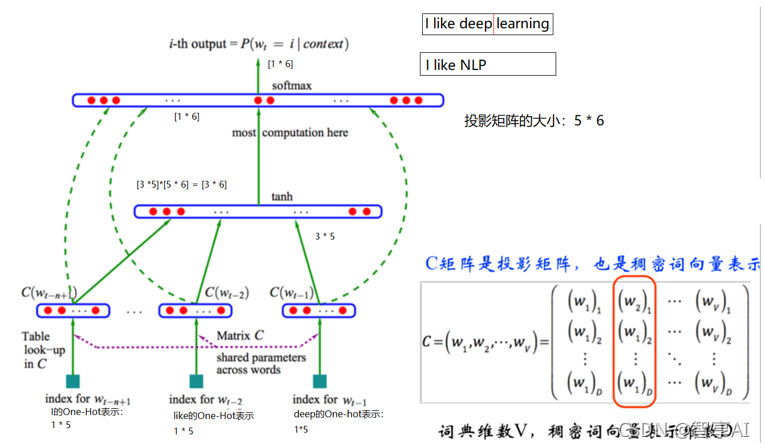
2.2 NNLM的计算过程
-
根据前面的n-1个单词,预测第n个单词的概率
2.3 环境
python3.7
torch==1.8.0
2.4 步骤
步骤一:读取数据
# 加载数据
def load_data():
sentences = ['i like dog', 'i love coffee', 'i hate milk']
word_list = " ".join(sentences).split() # ['i', 'like', 'dog', 'i', 'love', 'coffee', 'i', 'hate', 'milk']
word_list = list(set(word_list)) # 去除重复的单词
# {'hate': 0, 'dog': 1, 'milk': 2, 'love': 3, 'like': 4, 'i': 5, 'coffee': 6}
word_dict = {w: i for i, w in enumerate(word_list)}
# {0: 'like', 1: 'dog', 2: 'coffee', 3: 'hate', 4: 'i', 5: 'love', 6: 'milk'}
number_dict = {i: w for i, w in enumerate(word_list)}
return word_dict, number_dict,sentences
步骤二:实现mini-batch迭代器
# 实现一个mini-batch迭代器
def make_batch(sentences):
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split() # ['i', 'like', 'dog']
input = [word_dict[n] for n in word[:-1]] # 列表对应的数字序列,一句话中最后一个词是要用来预测的,不作为输入
target = word_dict[word[-1]] # 每句话的最后一个词作为目标值
input_batch.append(input)
target_batch.append(target)
return input_batch, target_batch #
步骤三:超参数设置和mini-batch组装
# 超参数
dtype = torch.FloatTensor
n_class = len(word_dict) # 词典|V|的大小,也是最后分类的类别,这里是7
# NNLM(Neural Network Language Model) Parameter,模型的参数
n_step = len(sentences[0].split()) - 1 # 文中用n_step个词预测下一个词,在本程序中其值为2
n_hidden = 2 # 隐藏层神经元的数量
m = 2 # 词向量的维度
# mini-batch 迭代器
input_batch, target_batch = make_batch(sentences)
input_batch = torch.LongTensor(input_batch)
target_batch = torch.LongTensor(target_batch)
dataset = Data.TensorDataset(input_batch, target_batch)
loader = Data.DataLoader(dataset=dataset, batch_size=16, shuffle=True)
步骤四:模型构建
# 定义模型
class NNLM(nn.Module):
def __init__(self):
"""
C: 词向量,大小为|V|*m的矩阵
H: 隐藏层的weight
W: 输入层到输出层的weight
d: 隐藏层的bias
U: 输出层的weight
b: 输出层的bias
1. 首先将输入的 n-1 个单词索引转为词向量,然后将这 n-1 个词向量进行 concat,形成一个 (n-1)*w 的向量,用 X 表示
2. 将 X 送入隐藏层进行计算,hidden = tanh(d + X * H) [3,4] * [4 * 2]
3. 输出层共有|V|个节点,每个节点yi表示预测下一个单词i的概率,y的计算公式为y = b + X * W + hidden * U
n_step: 文中用n_step个词预测下一个词,在本程序中其值为2
n_hidden: 隐藏层(中间那一层)神经元的数量
m: 词向量的维度
"""
super(NNLM, self).__init__()
# 7 * 2
self.C = nn.Embedding(n_class, m) # 词向量随机赋值,代替了先使用one-hot,然后使用matrix C映射到词向量这一步
self.H = nn.Parameter(torch.randn(n_step * m, n_hidden).type(dtype)) # 4 * 2
self.W = nn.Parameter(torch.randn(n_step * m, n_class).type(dtype)) # 4 * 7
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype)) # 2
self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype))
self.b = nn.Parameter(torch.randn(n_class).type(dtype)) # 词典的大小
print("---")
def forward(self, X):
"""
X: [batch_size, n_step]
"""
X = self.C(X) # [batch_size, n_step] => [batch_size, n_step, m]
X = X.view(-1, n_step * m) # [batch_size, n_step * m]
hidden_out = torch.tanh(self.d + torch.mm(X, self.H))
output = self.b + torch.mm(X, self.W) + torch.mm(hidden_out, self.U)
return output
步骤五:实例化模型和预测
# 实例化模型,优化器,损失函数
model = NNLM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# train
for epoch in range(5000):
for batch_x, batch_y in loader:
optimizer.zero_grad()
output = model(batch_x)
loss = criterion(output, batch_y)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost = ', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
# Test
predict = model(input_batch).data.max(1, keepdim=True)[1]
# squeeze():对张量的维度进行减少的操作,原来:tensor([[2],[6],[3]]),squeeze()操作后变成tensor([2, 6, 3])
print([sen.split()[:n_step] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
2.6 运行结果
运行结果:
---
Epoch: 1000 cost = 0.311220
Epoch: 2000 cost = 0.044960
Epoch: 3000 cost = 0.011267
Epoch: 4000 cost = 0.004640
Epoch: 5000 cost = 0.002216
[['i', 'like'], ['i', 'love'], ['i', 'hate']] -> ['dog', 'coffee', 'milk']
版权声明:本文为GUANGZHAN原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。