文章目录
前言
索引是对数据库表中一列或多列的值进行排序的一种结构。MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度
。索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。
我想很多人对mysql的认知可能就是CRUD(代表创建(Create)、更新(Update)、读取(Retrieve)和删除(Delete)操作),也不敢说自己会用和熟悉mysql,当然我就是其中一个,虽然知道mysql有很多东西,但是一直都没有深入的了解和掌握,最近想着好好的把Mysql原理学习下,这篇就是开胃菜吧,以后的慢慢道来。本篇文章内容主是基于mysql的InnoDB存储引擎。
一、MySQL索引介绍
索引是一个单独的、存储在磁盘上的数据库结构,它们包含着对数据表里所有记录的引用指针。使用索引用于快速找出在某个或多个列中有一特定值的行,所有MySQL列类型都可以被索引,对相关列使用索引是提高查询操作速度的最佳途径
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。比如我们在查字典的时候,前面都有检索的拼音和偏旁、笔画等,然后找到对应字典页码,这样然后就打开字典的页数就可以知道我们要搜索的某一个key的全部值的信息了。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件),而不是在select的字段中,实际上,索引也是一张“表”,该表保存了主键与索引字段,并指向实体表的记录,虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件,建立索引会占用磁盘空间的索引文件。说白了索引就是用来提高速度的,但是就需要维护索引造成资源的浪费,所以合理的创建索引是必要的。
1.1 索引的类别
先去官网文档看看支持的索引类型,索引的实现方式如下图所示:
https://dev.mysql.com/doc/refman/8.0/en/create-index.html
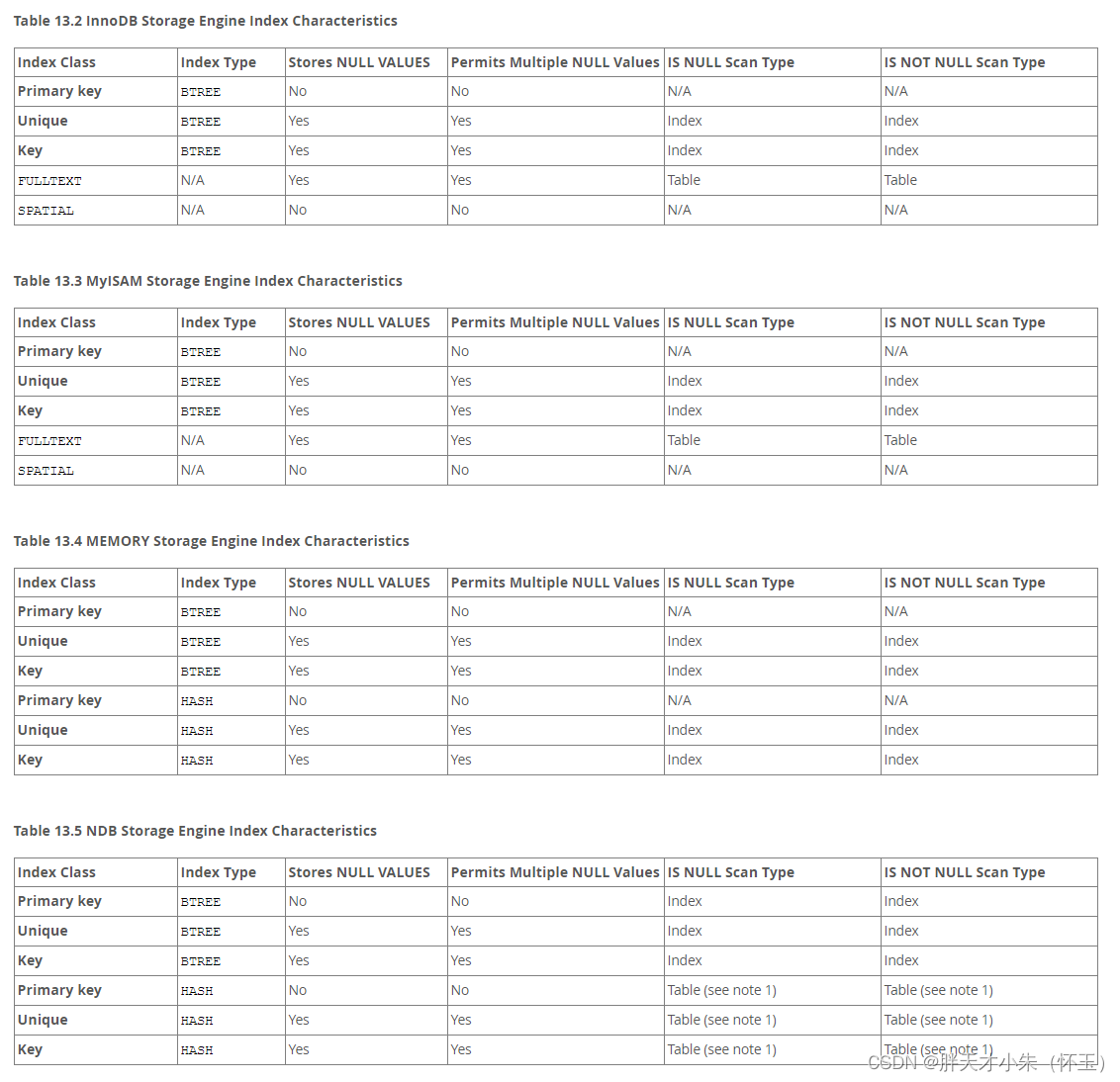
由于本文是基于mysql的InnoDB存储引擎,索引我们主要看第一个表格,其他的表格可以自行的观看,都不难,从表格我们可以看出来,InnoDB存储引擎索引只支持BTREE类型的索引,索引的类别有Primary Key,Unique,Key,FULLTEXT和SPATIAL。当然也有其他的分法,按照索引列的数量分为单列索引和组合索引。
- Primary Key(聚集索引):InnoDB存储引擎的表会存在主键(唯一非null),如果建表的时候没有指定主键,则会使用第一非空的唯一索引作为聚集索引,否则InnoDB会自动帮你创建一个不 可见的、长度为6字节的row_id用来作为聚集索引。
- 单列索引:单列索引即一个索引只包含单个列
- 组合索引:组合索引指在表
-
的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用。使用组合索引时遵循最左前缀集合
Unique(唯一索引):索引列的值必须唯一,但允许有空值。若是组合索引,则列值的组合必须唯一。主键索引是一种特殊的唯一索引,不允许有空值 - Key(普通索引):是MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值
- FULLTEXT(全文索引):全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在CHAR、VARCHAR或者TEXT类型的列上创建
- SPATIAL(空间索引):空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING和POLYGON。MySQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类似的语法创建空间索引。创建空间索引的列必须声明为NOT NULL
这里在说一下组合索引的遵循最左前缀原则:
order by使用索引最左前缀
- order by a
- order by a,b
- order by a,b,c
- order by a desc, b desc, c desc
如果where使用索引的最左前缀定义为常量,则order by能使用索引
- where a=const order by b,c
- where a=const and b=const order by c
- where a=const and b > const order by b,c
不能使用索引进行排序
- order by a , b desc ,c desc --排序不一致
- where d=const order by b,c --a丢失
- where a=const order by c --b丢失
- where a=const order by b,d --d不是索引的一部分
- where a in(...) order by b,c --a属于范围查询
创建一个简单的表:
CREATE TABLE my_test (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) DEFAULT NULL,
`sex` varchar(5) DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
`birthday` datetime NOT NULL,
`user_num` int(11) unique,
PRIMARY KEY (`id`),
index(username)
);
show index from my_test;

明明在建表的时候只创建了一个索引,查询出来的有三个,其实主键,唯一约束列,外键这些都自动会生成索引,至于外键大家可以去尝试下。
上表格中各个列的说明:
table #表名称
non_unique #如果索引不能包括重复词,为0,如果可以,则为1
key_name #索引的名称
seq_in_index #索引中的列序号
column_name #列名称
collation #列以什么方式存储在索引中,在mysql中,有值'A'(升序)或者NULL(无分类)
cardinality #索引在唯一值的数据的估值,通过运行analyze table xxx_table;或者 myisamchk -a 可以更新,技术根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没必要是精确的,基数越大,当进行联合所饮食,mysql使用该索引的机会越大。myisam中,该值是准确的,INNODB中该值数据是估算的,存在偏差
sub_part #如果列只是部分的编入索引 则为被编入索引的字符的数目,如果整列被编入索引,则为NULL
packed #指示关键词如何被压缩,如果没有被压缩,则为NULL
NULL #如果列含有NULL,则含有YES,如果没有,则该列为NO
index_type #用过的索引方法(BTREE,FULLTEXT,HASH,RTREE)
comment #备注
index_comment #为索引创建时提供了一个注释属性的索引的任何评论
1.2 索引的创建原则
- 索引并非越多越好,一个表中如果有大量的索引,不仅占用磁盘空间,而且会影响INSERT、DELETE、UPDATE等语句的性能,因为在表中的数据更改的同时,索引也会进行调整和更新
- 避免对经常更新的表进行过多的索引,并且索引中的列尽可能少。而对经常用于查询的字段应该创建索引,但要避免添加不必要的字段。
- 数据量小的表最好不要使用索引,由于数据较少,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果。
- 在条件表达式中经常用到的不同值较多的列上建立索引&