目录
语句组合:select … from … where … group by having order by limit; (看自己需求)
1、select 基础语句(DQL应用)
SELECT {*|字段列表} [FROM <表1>,<表2>... [where <表达式> [GROUP BY ] [HAVING [{}...]] [ORDER BY ] [LIMIT {,} ]]
-
{*|字段列表}:
*
代表所有字段|字段1,字段2,字段3… - FROM <表1>,<表2>…:查询的数据来自那张表
- WHERE子句:查询条件
- GROUP BY <字段>:结果按某字段分组
- HAVING子句 :分组后结果查询条件,跟在group by 后使用
- [ORDER BY <字段>]:结果按某字段排序
1.1、单独使用
-- select @@xxx 查看系统配置参数
select @@port;
select @@basedir;
select @@datadir;
select @@socket;
select @@server_id;select +函数 使用:
SELECT NOW();
SELECT DATABASE();
SELECT USER();
SELECT CONCAT("hello world");
SELECT CONCAT(USER,"@",HOST) FROM mysql.user;
SELECT GROUP_CONCAT(USER,"@",HOST) FROM mysql.user;
1.2、单表语句
如果表数据过大慎用
select * from stu ;
查询stu表中,学生姓名和入学时间
select sname , intime from stu;
1.3、world库单表操作
下面是world练习库下载地址
https://download.csdn.net/download/weixin_47647077/19825832
world --->库名
city --->城市表
country --->国家表
countrylanguage --->国家语言
city:城市表
DESC city;
ID 城市ID
NAME 城市名
CountryCode 国家代码,比如中国CHN 美国USA
District 区域(省)
Population 人口
use world;
show create table city; 查看表的建成
select * from city where id<10; 查看表的内容情况
1.3.1、单表语句之where
以下是 SQL SELECT 语句使用 WHERE 子句从数据表中读取数据的通用语法:
SELECT field1, field2,...fieldN FROM table_name1, table_name2...
[WHERE condition1 [AND [OR]] condition2.....- 查询语句中你可以使用一个或者多个表,表之间使用逗号, 分割,并使用WHERE语句来设定查询条件。
- 你可以在 WHERE 子句中指定任何条件。
- 你可以使用 AND 或者 OR 指定一个或多个条件。
- WHERE 子句也可以运用于 SQL 的 DELETE 或者 UPDATE 命令。
- WHERE 子句类似于程序语言中的 if 条件,根据 MySQL 表中的字段值来读取指定的数据。
1、实例-查询中国城市信息:(会列出所有中国的城市)
select * from city where countrycode='CHN';
2、实例-查询黑龙江省信息:
select * from city where District='heilongjiang';
3、实例-查询city表中上海的信息
select * from city where name='shanghai';1、配合符合查询(<,>,=,>=,<=,<>)
实例-查询人口小于100的城市
select * from city where Population<100;
2、配合逻辑运算符(and,or)
实例-条件1(在中国)条件2(人口大于500w)
select * from city where CountryCode='CHN' and Population>5000000;
实例-查询黑龙江或江苏信息
select * from city where District='heilongjiang' or District='jiangsu';
3、配合模糊查询
实例-查询省的名字前面带guang开头的
SELECT * FROM city WHERE district LIKE 'guang%';
注意:%不能放在前面,因为不走索引.
4、配合in查询
实例-查询黑龙江或江苏信息(和or一个结果)
select * from city where District in ('heilongjiang','jiangsu');
5、配合between and
实例-查询世界上人口数量大于100w小于200w的城市信息
SELECT * FROM city WHERE population >1000000 AND population <2000000;
SELECT * FROM city WHERE population BETWEEN 1000000 AND 2000000;
1.3.2、单表语句之group by
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
GROUP BY 语法:
SELECT column_name, function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;1、常用聚合函数:
**max()** :最大值
**min()** :最小值
**avg()** :平均值
**sum()** :总和
**count()** :个数
group_concat() : 列转行
实例1-统计有city表中每个国家有多少个市:
select CountryCode,count(*) from city GROUP BY CountryCode;
实例2-统计每个国家人口
SELECT countrycode ,SUM(population) FROM city GROUP BY countrycode;
实例3-统计中国各个省的总人口数量
SELECT district,SUM(Population) FROM city WHERE countrycode='chn' GROUP BY district;
实例4:统计世界上每个国家的城市数量
SELECT countrycode,COUNT(id) FROM city GROUP BY countrycode;
实例5-统计中国每个省的总人口数,只打印总人口数小于100(where,group,having)
SELECT district,SUM(Population) FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(Population) < 1000000 ;
1.3.3、order by + limit 用法
1、order by 默认是从小到大的排序(加 desc的从大到小)
实例1-查看中国城市人口的排序从小到大
select * from city where CountryCode='CHN' ORDER BY Population;
实例2-查看中国城市人口的排序从大到小
select * from city where CountryCode='CHN' ORDER BY Population desc;
2、order by + limit (是加了显示多少行的限制)
实例1-统计中国,每个省的总人口,找出总人口大于500w的,并按总人口从大到小排序,只显示前三名
SELECT district, SUM(population) FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 3 ;
实例2-LIMIT N ,M --->跳过N,显示一共M行 (LIMIT 5,5)
SELECT district, SUM(population) FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 5,5;
语句组合:select … from … where … group by having order by limit; (看自己需求)
1.3.4、distinct去重
实例1-显示所有国家的名字不去重
SELECT countrycode FROM city;
实例2-显示所有国家的名字去重
SELECT DISTINCT(countrycode) FROM city;
1.3.5、union all –联合查询
1、中国或美国城市信息
实例1-in的查询方法:
SELECT * FROM city WHERE countrycode IN ('CHN' ,'USA');
实例2-union all 查询方法
SELECT * FROM city WHERE countrycode='CHN'
UNION ALL
SELECT * FROM city WHERE countrycode='USA';
说明:一般情况下,我们会将 IN 或者 OR 语句 改写成 UNION ALL,来提高性能
UNION 去重复
UNION ALL 不去重复
1.3.6、案例准备
use school
student :学生表
sno: 学号
sname:学生姓名
sage: 学生年龄
ssex: 学生性别
teacher :教师表
tno: 教师编号
tname:教师名字
course :课程表
cno: 课程编号
cname:课程名字
tno: 教师编号
score :成绩表
sno: 学号
cno: 课程编号
score:成绩
-- 项目构建
drop database school;
CREATE DATABASE school CHARSET utf8;
USE school
CREATE TABLE student(
sno INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(20) NOT NULL COMMENT '姓名',
sage TINYINT UNSIGNED NOT NULL COMMENT '年龄',
ssex ENUM('f','m') NOT NULL DEFAULT 'm' COMMENT '性别'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE course(
cno INT NOT NULL PRIMARY KEY COMMENT '课程编号',
cname VARCHAR(20) NOT NULL COMMENT '课程名字',
tno INT NOT NULL COMMENT '教师编号'
)ENGINE=INNODB CHARSET utf8;
CREATE TABLE sc (
sno INT NOT NULL COMMENT '学号',
cno INT NOT NULL COMMENT '课程编号',
score INT NOT NULL DEFAULT 0 COMMENT '成绩'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE teacher(
tno INT NOT NULL PRIMARY KEY COMMENT '教师编号',
tname VARCHAR(20) NOT NULL COMMENT '教师名字'
)ENGINE=INNODB CHARSET utf8;
INSERT INTO student(sno,sname,sage,ssex)
VALUES (1,'zhang3',18,'m');
INSERT INTO student(sno,sname,sage,ssex)
VALUES
(2,'zhang4',18,'m'),
(3,'li4',18,'m'),
(4,'wang5',19,'f');
INSERT INTO student
VALUES
(5,'zh4',18,'m'),
(6,'zhao4',18,'m'),
(7,'ma6',19,'f');
INSERT INTO student(sname,sage,ssex)
VALUES
('oldboy',20,'m'),
('oldgirl',20,'f'),
('oldp',25,'m');
INSERT INTO teacher(tno,tname) VALUES
(101,'oldboy'),
(102,'hesw'),
(103,'oldguo');
DESC course;
INSERT INTO course(cno,cname,tno)
VALUES
(1001,'linux',101),
(1002,'python',102),
(1003,'mysql',103);
DESC sc;
INSERT INTO sc(sno,cno,score)
VALUES
(1,1001,80),
(1,1002,59),
(2,1002,90),
(2,1003,100),
(3,1001,99),
(3,1003,40),
(4,1001,79),
(4,1002,61),
(4,1003,99),
(5,1003,40),
(6,1001,89),
(6,1003,77),
(7,1001,67),
(7,1003,82),
(8,1001,70),
(9,1003,80),
(10,1003,96);
SELECT * FROM student;
SELECT * FROM teacher;
SELECT * FROM course;
SELECT * FROM sc;
1.3.6、join 联表查询
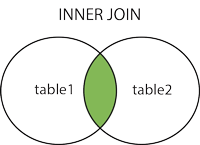
JOIN 按照功能大致分为如下三类:(关联表之间先找到关联)
-
INNER JOIN(内连接,或等值连接)
:获取两个表中字段匹配关系的记录。 -
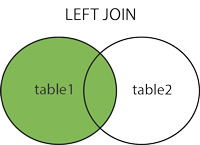
LEFT JOIN(左连接):
获取左表所有记录,即使右表没有对应匹配的记录。 -
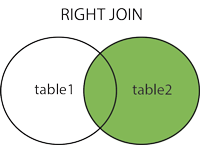
RIGHT JOIN(右连接):
与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
1、内连接(inner join) inner 可加可不加
实例1-查询student,sc表以学号相同为条件
select student.sno,student.sname,sc.cno,sc.score from
student inner join sc
on student.sno=sc.sno;
实例2-类似上面查询用where 实现
SELECT student.sno,student.sname,sc.cno,sc.score from student,sc
where student.sno=sc.sno;
1.3.7、别名
列别名,表别名
SELECT
a.Name AS an ,
b.name AS bn ,
b.SurfaceArea AS bs,
a.Population AS bp
FROM city AS a JOIN country AS b
ON a.CountryCode=b.Code
WHERE a.name ='shenyang';
1.4、多表练习(以school库为基础)
实例1-统计zhang3,学习了几门课
SELECT st.sname , COUNT(sc.cno)
FROM student AS st JOIN sc ON st.sno=sc.sno
WHERE st.sname='zhang3';
实例2-查询zhang3,学习的课程名称有哪些? (GROUP_CONCAT(co.cname)这个是合并课程在一行)
SELECT st.sname , GROUP_CONCAT(co.cname)
FROM student AS st JOIN sc ON st.sno=sc.sno
JOIN course AS co ON sc.cno=co.cno
WHERE st.sname='zhang3';
实例3-查询oldguo老师教的学生名.
SELECT te.tname ,GROUP_CONCAT(st.sname)
FROM student AS st JOIN sc ON st.sno=sc.sno
JOIN course AS co ON sc.cno=co.cno
JOIN teacher AS te ON co.tno=te.tno
WHERE te.tname='oldguo';
实例4-每位老师所教课程的平均分,并按平均分排序
SELECT te.tname,AVG(sc.score)
FROM teacher AS te JOIN course AS co ON te.tno=co.tno
JOIN sc ON co.cno=sc.cno
GROUP BY te.tname
ORDER BY AVG(sc.score) DESC ;
1.5、视图应用
1.5.1、视图使用
use world;
定义视图:
CREATE VIEW aa as
select District,SUM(Population) from city WHERE CountryCode='CHN'
GROUP BY District;
下面这个查询等同于as 后面那个查询
SELECT * from aa;
1.5.2、视图库
DESC information_schema.TABLES
TABLE_SCHEMA ---->库名
TABLE_NAME ---->表名
DATA_LENGTH ---->表的大小(字节)
ENGINE ---->引擎
TABLE_ROWS ---->表的行数
AVG_ROW_LENGTH ---->表中行的平均行(字节)
INDEX_LENGTH ---->索引的占用空间大小(字节)实例操作:
use information_schema;
实例1-查询整个数据库中所有库和所对应的表信息
select table_schema,GROUP_CONCAT(table_name) from tables
group by table_schema;
实例2-统计所有库下的表个数
select table_schema,count(table_name) from tables
group by table_schema;
实例3-查询所有innodb引擎的表及所在的库
select table_schema,table_name from tables
where engine='innodb';
实例4-统计world数据库下每张表的磁盘空间占用
select table_name,data_length from tables
WHERE table_schema='world';
实例5-统计所有数据库的总的磁盘空间占用
select table_schema,SUM(data_length) from tables
GROUP BY table_schema;
生成整个数据库下的所有表的单独备份语句
生成整个数据库sk和world下的所有表的单独备份语句
模板语句:
mysqldump -uroot -p123 world city >/tmp/world_city.sql (单表备份语句)
SELECT CONCAT("mysqldump -uroot -p123 ",table_schema," ",table_name," >/tmp/",table_schema,"_",table_name,".sql" )
FROM information_schema.tables
WHERE table_schema IN('sk','world')
INTO OUTFILE '/tmp/bak.sh' ;
语句拼接是重点:
CONCAT("mysqldump -uroot -p123 ",table_schema," ",table_name," >/tmp/",table_schema,"_",table_name,".sql" )
2、show语句
show databases; #查看所有数据库
show tables; #查看当前库的所有表
SHOW TABLES FROM #查看某个指定库下的表
show create database world #查看建库语句
show create table world.city #查看建表语句
show grants for root@'localhost' #查看用户的权限信息
show charset; #查看字符集
show collation #查看校对规则
show processlist; #查看数据库连接情况
show index from #表的索引情况
show status #数据库状态查看
SHOW STATUS LIKE '%lock%'; #模糊查询数据库某些状态
SHOW VARIABLES #查看所有配置信息
SHOW variables LIKE '%lock%'; #查看部分配置信息
show engines #查看支持的所有的存储引擎
show engine innodb status\G #查看InnoDB引擎相关的状态信息
show binary logs #列举所有的二进制日志
show master status #查看数据库的日志位置信息
show binlog evnets in #查看二进制日志事件
show slave status \G #查看从库状态
SHOW RELAYLOG EVENTS #查看从库relaylog事件信息
desc (show colums from city) #查看表的列定义信息
版权声明:本文为weixin_47647077原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。