准备工作:
- txt格式的词云文本素材
- wordcloud(词云)、jieba(中文分词)、numpy(数组处理)、PIL(读取图片)4个库。
没有安装的话需要在cmd里pip install 一下,使用jupyter也可以在Anaconda Powershell Prompt 里安装。
在正常下载完jieba(pip install jieba)、PIL(pip install pillow)、numpy库后,pip install wordcloud 报错是我遇见的第一个问题。
更新pip,通过镜像下载均不行,查找一番资料后,发现可以通过
https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud
选择合适的版本下载whl文件,如图
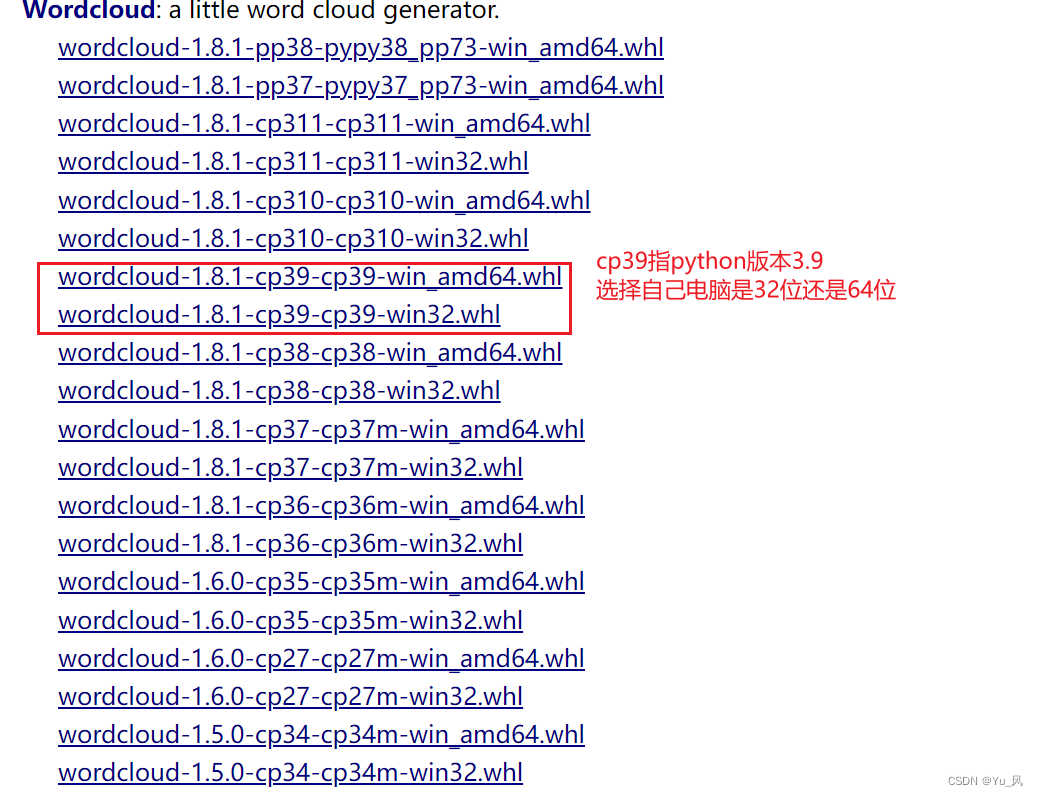
在cmd里pip install wheel,成功后进入下载好文件的所在路径pip install 文件名,或者pip install 全路径文件名。成功后可以打开pycharm➡file➡setting➡python interpreter查看其是否存在来进行检验。
在所有准备工作做好后,正式开始我们的词云制作。
import wordcloud
import numpy
from PIL import Image
import jieba
pic = Image.open(r"C:\Users\Administrator\Desktop\computer.PNG","r") #背景图
pic = numpy.array(pic)
w = wordcloud.WordCloud(mask=pic)
# 构建并配置词云对象w,scale参数,提高清晰度
w = wordcloud.WordCloud(width=1000,
height=700,
background_color='white',
font_path=r'D:\Ziti\FZHLJW.TTF',
mask=pic,
scale=15)
# 对来自外部文件的文本进行中文分词,得到string
f = open(r"C:\Users\Administrator\Desktop\work.txt","r",encoding = 'utf-8')
txt = f.read()
txtlist = jieba.lcut(txt) #精确模式,每个词只用一遍,没有冗杂词汇,利用 jieba 将文本 txt 进行分词、并形成一个列表传递给变量 txtlist
jieba.suggest_freq(('大数据'), True) #输出分词结果后发现大数据被分为了大和数据两个词,调整词典使其不被分开
string = " ".join(txtlist)#利用字符串的 .join 方法将列表重新转换成字符串
# 将string变量传入w的generate()方法,给词云输入文字
w.generate(string)
# 将词云图片导出到当前文件夹
w.to_file('ciyun_pic.png')背景图是一个打开的笔记本电脑,导出的图片如下所示。

版权声明:本文为weixin_46861115原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。