【引言】
最近对区块链技术有一些兴趣,区块链技术估计这个名字已经被大家所熟知了,但区块链数据库估计还没几个人知道。目前国内有两种数据库RepChain(中科院研发)和CovenantSQL ,本文讲重点讲解CovenantSQL 这一新兴区块链数据库。
区块链数据库的优势主要体现在信任、溯源、数据共享、数据交易、数据交换上。
不懂? 接着往下看。
以下文章转自如下链接,根据本文理解做了适当调整。
https://zhuanlan.zhihu.com/p/42517534
区块链数据库为什么开头有这样的想法?因为我们相信传统应用中对区块链是有诉求的,不管是信任、溯源、数据共享、数据交易、数据交换,相信这些都是有应用点的。所以把区块链技术和分布式数据库进行结合,希望做出新一代的数据库系统。
CovenantSQL 是应用区块链技术构建的去中心化 SQL 云数据库,
结合了区块链、共享经济、分布式数据库的优势,保障了用户隐私及对数据的所有权。
CovenantSQL 具备以下特点:
SQL接口: 支持 SQL-92 标准,传统 App 几乎0修改即可数据上链
去中心化: 基于独有的高效拜占庭容错共识算法 Kayak 实现的去中心化结构
不可篡改: CovenantSQL 中的 Query 历史记录是可追溯的
隐私: 如果 Bitcoin 是人们的私人钱包,那么 CovenantSQL 就是是人们的去中心化的私密数据库
相信在下一个互联网时代,每个人都应该有完整的数据权利。
CovenantSQL 原理
CovenantSQL 是一个运行在 Internet 上的开放网络,主要有以下三种角色组成:
主链节点:
通过去中心化的架构,DPoS 模式的共识机制对矿工和用户进行撮合、协调、仲裁
侧链矿工:
所有人都可以通过运行 Covenant Miner 来提供数据库服务来赚取奖励
通过 ETLS 传输层加密、应用层签名、落盘加密、端到端加密来保证用户数据隐私
数据库用户:
用户通过一个私钥就可以创建指定数量节点的分布式数据库,存储自己的结构化数据
数据矿工的分布和地址仅对数据库用户可见,防止用户数据被嗅探
通过 去中心化的高可用的架构 和 Miner 押金机制,用户的数据可以在成本和可靠性、可用性上达到平衡可控
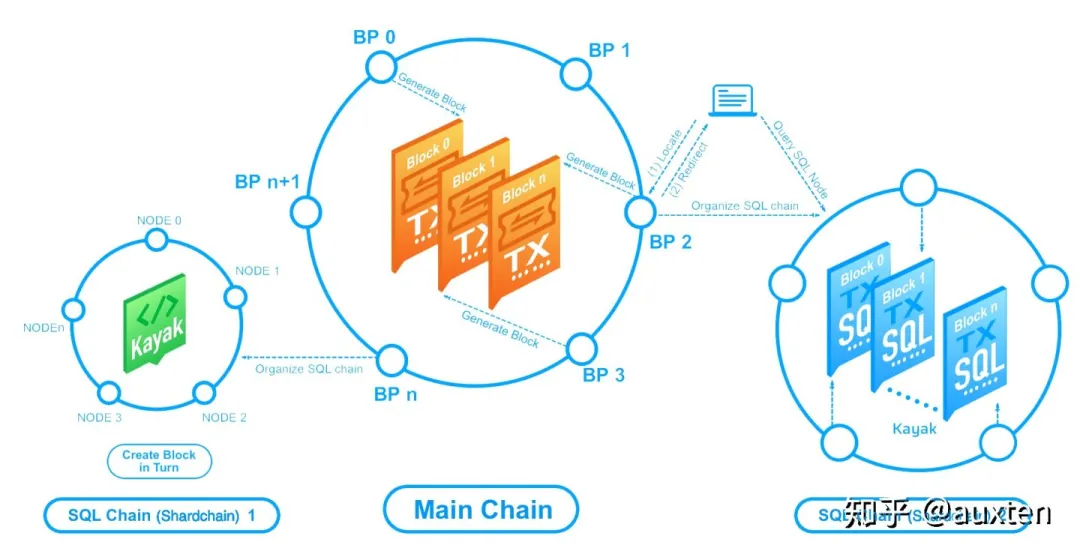
第一层:全局共识层(主链,架构图中的中间环):
整个网络中只有一个主链。
主要负责数据库矿工与用户的合同匹配,交易结算,反作弊,子链哈希锁定等全局共识事宜。
第二层:SQL 共识层(子链,架构图中的两边环):
每个数据库都有自己独立的子链。
主要负责数据库各种事务的签名,交付和一致性。这里主要实现永久可追溯性的数据历史,并且在主链中执行哈希锁定。
第三层:数据储存层(支持 SQL-92 的数据库引擎):
每个数据库都有自己独立的分布式引擎。
主要负责:数据库存储和加密;查询处理和签名;高效索引。
做点有意思的事情
很喜欢Jeff Hammerbacher说过的一句话:
The best minds of my generation are thinking about how to make people click ads.
作为One of the best minds,当你不再需要为了生计而去努力,你最想去做点什么呢?也许人的一生应该办一点事,留一点痕迹。
2017年冬天,freebsd来北京,约我在知春路撸串,还是那个当年一起吃着火锅鄙视着MongoDB用BSON做存储的学长给我描述了一个有意思的想法。又想起了他河畔签名上的那段中二的话:“西天取完了经,东边应该还有,伙伴们好不好让我们再拯救地球……”
这个想法大致就是:
把闲置的计算机利用起来,通过一套Code Law组成一个分散的,支持SQL查询的数据库,用户和数据库矿工可以在Code Law的限制下完成撮合和价值交换。
经历了刚接触Bitcoin这个idea时候的兴奋,把全部身家买了比特币,起起伏伏,最后失望清盘……
经历了Blockchain概念被单独提出时,甚至想过用Blockchain的idea重新写一版Boinc(Berkeley的Volunteer computing框架,能让用户电脑在闲置的时候用于各种科学计算,包括“寻找外星人计划”),但最后还是没能下定决心……
经历了Ethereum横空出世,但现在看来最大的用途竟然是割韭菜……
无奈这个时代,人人都想布局未来,一夜暴富。但思想的碰撞需要时间、理论的成熟需要时间,编码落地需要时间。互联网热潮催生了一波.com泡沫,照目前自媒体的发达程度来看区块链离真正落地,至少还差三波泡沫……
但这一次,我决定为了一个idea全力以赴一次,即使失败了,也希望后世踏着我们倒下的身躯冲上更高的地方。拿着烤串的我当即决定离职,做点有意思的事情……
现在想来,选择去做这么底层的东西,可能部分源自于我们对数据库的中二执念,更多的则是改变数据&隐私混乱现状的愿望:
下一代的互联网,所有人都应该拥有自己数据的完整权益(Data Rights)
Data Rights
数据放在自己的电脑里固然比较安全,但也容易意外丢失,也不方便查阅。无论是Facebook还是微信、各种云盘,用户的数据几乎都是存储在大佬控制的数据库里。数据是你的也是互联网大佬的,但最后还是互联网大佬的,而且还是你自己确认了使用条款的。
网上的各种数据,大致可以分为两类:
个人数据
例如:个人的身份&账号信息;各种私人财产;个人发布的各种内容;在各种应用、网站的历史数据。
现状:隐私泄露,被数据挖掘,被侵犯数字版权。
愿望:每个人都应该拥有个人数据的读取、修改的控制权,以及盈利、授权的权利。
公共数据
例如:Wikipedia等各种共同创作的作品;人类文明沉淀下来的知识;各种被作者分享给所有人的数据。
现状:各种wiki被恶意篡改失去公信力,各种论文、文献被挟持用来盈利,有价值数据的生产者得不到任何好处,有时连署名权都不能保证。
愿望:知识的生产、积累是一个共同创作的过程,每个人的贡献应当被记录。
《硅谷》里Richard描述了一个“去中心化的互联网”
,其中必不可少的就是一个去中心化的数据库。传统数据库遇到了区块链,数据的Insert、Update、Delete变成了Append,“追加而不是覆盖”让数据的历史可以被完整记录。
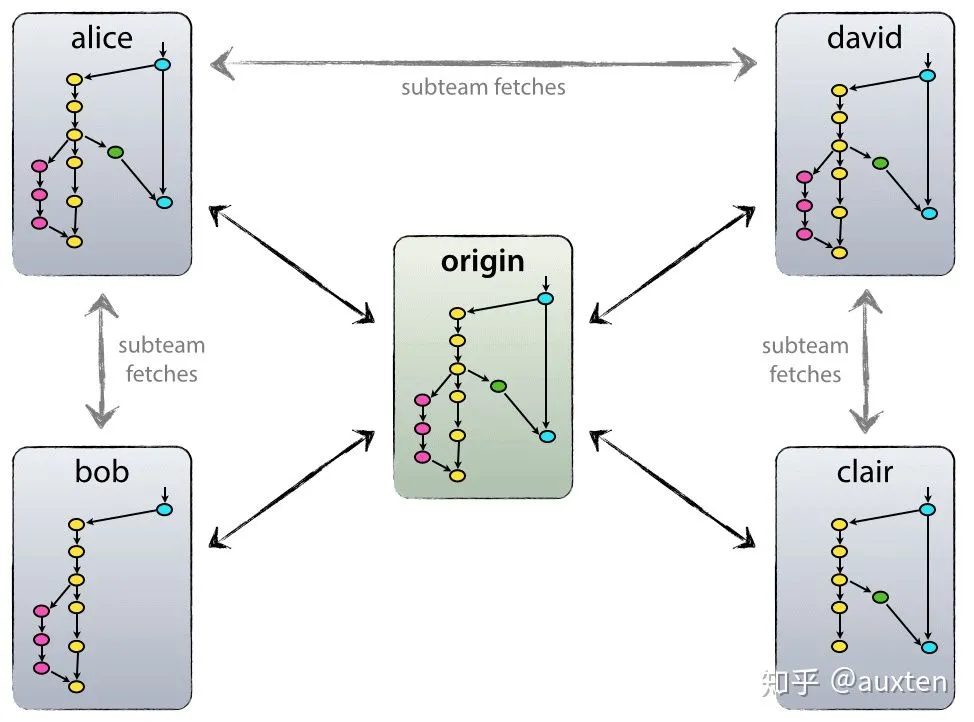
Blockchain的很多设计和Git有相似之处,比如:Merkle Tree
Read-Only
为了改变现状,有很长的路要走,一个去中心化的数据库,为用户控制自己的数据至少提供了可能性。
举一个简单的例子:未来我们的个人数据,都可以存储在去中心化的云端数据库,像比特币一样,我们可以通过一个密钥完全的控制自己的数据。我们可以制定一个类似信用卡行业PCI DSS的标准,我们暂且叫做GDSS(General Data Security Standard),核心是要求厂商对于用户的数据严格执行 限定用途、用后删除 的原则。例如假设Facebook是我们可信的厂商,遵循GDSS,我们可以给Facebook一个我们授权仅可以读取我们姓名、年龄、朋友列表的密钥。同时,Facebook对于我们数据的每次读取都会被记录,如果我们发现Facebook用我们的数据做了一些我们不希望的事情,可以随时吊销这个密钥并进行追责。
再比如:大数据行业的创业公司或者研究机构最为头疼的事情莫过于没有数据,普通的用户可以通过收费的形式对这些研究机构进行数据授权。这样就可以形成一个双赢的局面,避免存储了大量我们数据的巨头的 数据霸权。
目前欧盟的GDPR是一个在这方面非常领先的标准,非常值得借鉴。
Team Up
做过了无数的大大小小项目,都明白程序开发是个非常复杂的工作,有很多相似经验教训让我们有了共识:
项目开发一定要有清晰、可以量化的细粒度的目标。
不要进行全盘推翻式的重构,重构一定要分模块进行,并且保证接口一致。
项目早期,尽量少写代码来完成功能,而不是写更多代码去面向未来编程。
想到的太多,很乐意在讨论区一起聊聊经历过的项目给你带来的各种感悟……
2018年4月,CovenantSQL开始了第一行代码。创建github项目的时候没啥灵感,就临时取了ThunderDB这个名字。后来才通过引经据典想到了Covenant这个生僻的词,翻译成中文应该叫“契约”。最近这个词被提到还是因为这部电影:Alien: Covenant (2017)
Architecture
熟悉分布式系统原理的同学知道,从CAP theorem的角度出发,Blockchain是一种最终一致性算法。
Bitcoin为典型的Blockchain 1.0使用的PoW主要是为了应对非可信网络、节点的问题。从通俗的角度出发,几乎我们都有这样一个经验:“参与的人越多,决策效率越底下”。
似乎也是意识到同样的问题,以EOS为首的新一代Blockchain系统都采用了类似“内阁制”的DPoS。CovenantSQL在设计之初就考虑到这个问题,采用了下图所示的分层架构:
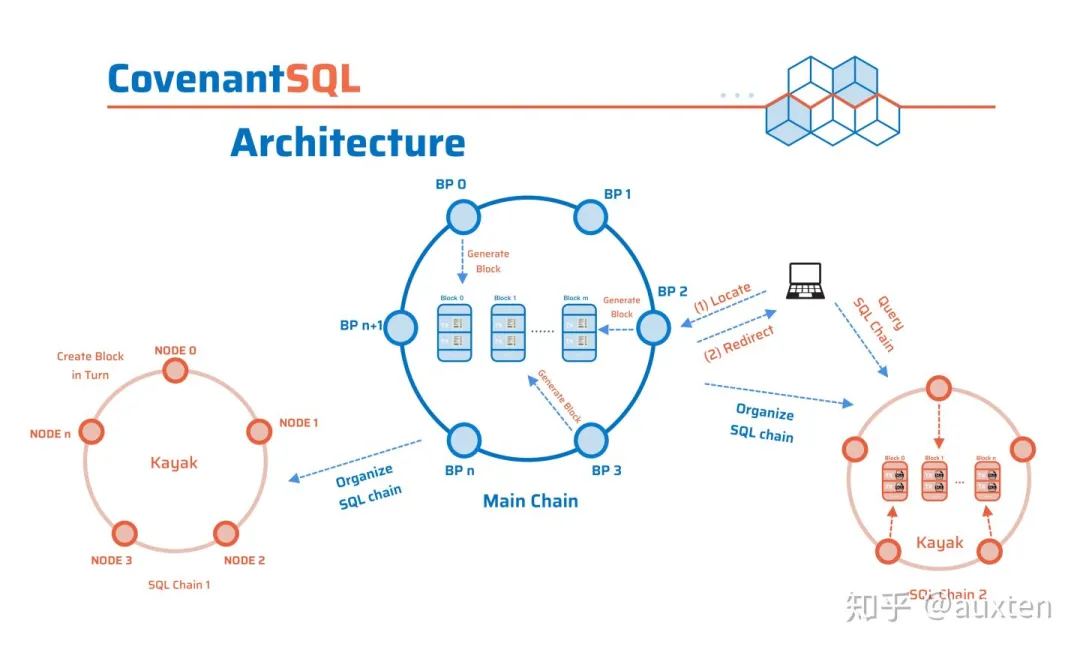
CovenantSQL Architecture
CovenantSQL的架构主要分为三层:
结算共识层(主链,架构图中中间的环):
整个网络只会存在一个主链。
主要负责:数据库Miner和使用方的合约撮合、交易结算,反作弊,侧链的锁定哈希等全局共识事务。
SQL共识层(侧链,两侧的环):
每个数据库都会有自己独立的侧链。
主要负责:数据库各种Transaction的签名、传递和一致性的达成,永久可追溯的数据历史主要在这里实现,并在主链进行哈希锁定。
数据库层:
每个Database有自己的独立分布式引擎。
主要负责:数据库的存储&加密,查询处理&签名,高效索引。
三层的设计互相进行哈希锁定保证数据的不可篡改,由顶向下依次根据需求的不同,采用不同的共识算法和更小的共识范围,达成更高的共识效率和性能。
How We Work
观察CovenantSQL的commit history可以发现,CovenantSQL的构建是一个Bottom Up的过程,首先是各个独立的模块,测试工具,经历了4个多月的密集开发,我们才正式构建出一个主程序。这么做的好处是显而易见的:CovenantSQL的模块单测覆盖率基本都在75%以上,很多CovenantSQL的模块可以单独被使用。
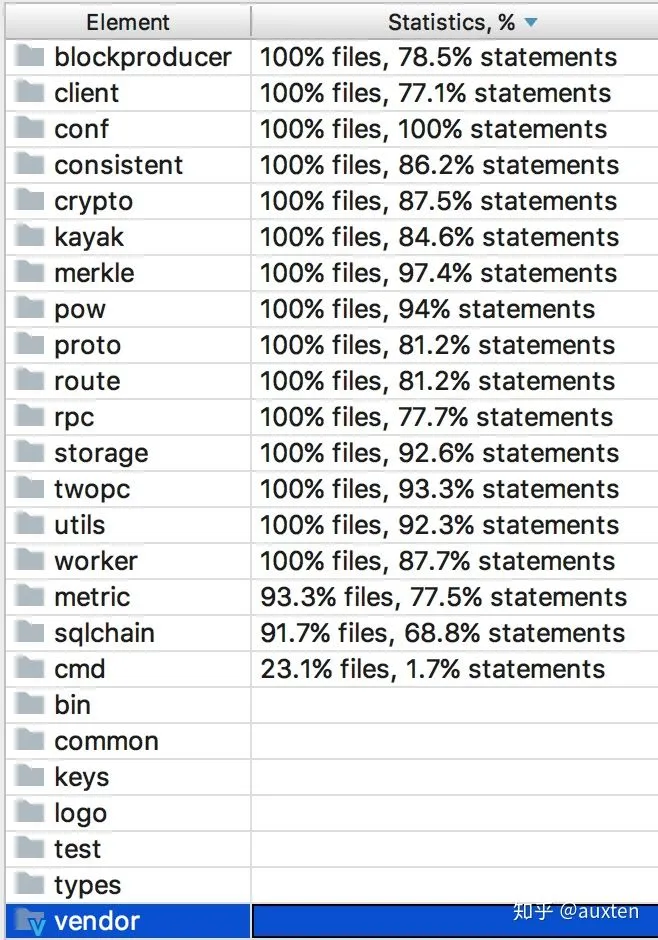
CovenantSQL Coverage Statistics
CovenantSQL/GNTE
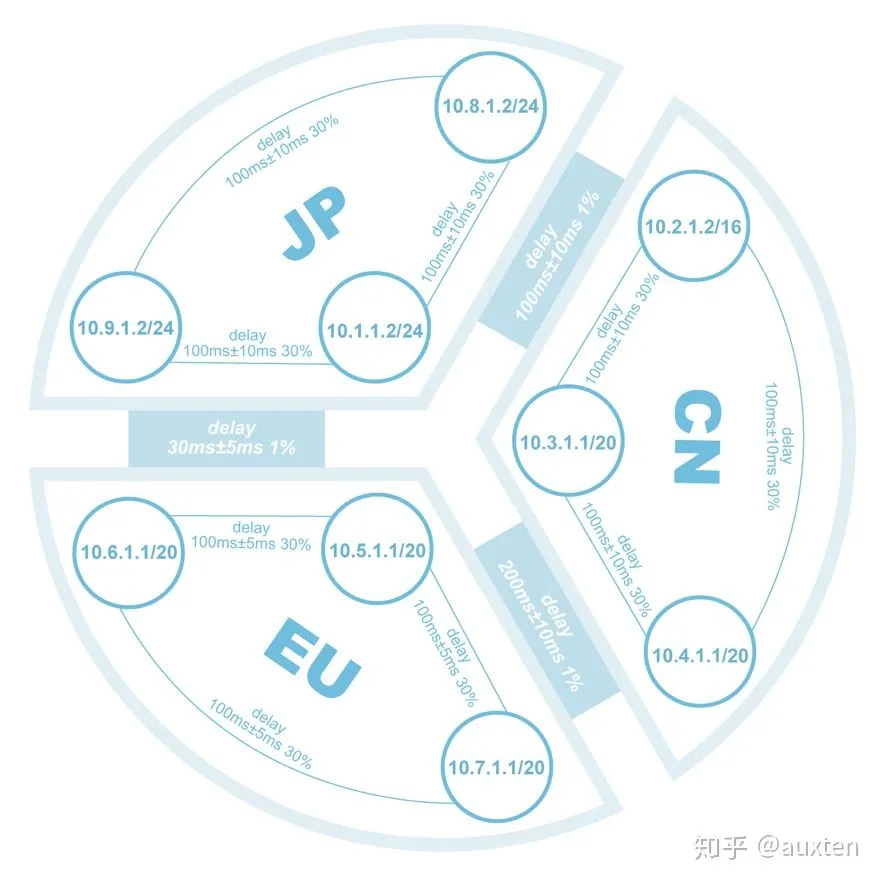
GNTE
为了模拟CovenantSQL节点遍布全球的情况下的网络环境,做了一个叫GNTE(Global Network Topology Emulator)的小工具,只要写一个YAML配置,运行一条命令,就可以模拟一个中国到美国的网络容器,比如:1Mbps带宽、延迟1200ms、1%概率 ±10ms。
这个项目发布两个月,已经171 Star了,Github传送门:CovenantSQL/GNTE
CovenantSQL每个版本的发布都会进行:
接近80%行覆盖率的自动化单元测试
包含线性一致性测试在内的各种集成测试
GNTE模拟全球网络环境进行集成测试
CovenantSQL/HashStablePack
HSP是我们构建的另外一个小工具,可以根据我们定义的golang的各种类型、Struct,自动生成序列化的接口
func(v *Type) MarshalHash() ([]byte, error)
,并且无论多复杂的Struct,只要存的内容是一样的,生成的
[]byte
都是内容一致的。
主要原理就是分析golang代码,生成AST(抽象语法树),根据AST上不同类型生成不同的
MarshalHash
函数。这样就避免了运行时用
Reflect
反射造成的大约两个数量级的程序变慢。CovenantSQL主要用这个工具在生成计算区块哈希的代码。
当然,甚至单元测试代码都是自动生成好的。更详细的使用方式可以看这里:CovenantSQL/HashStablePack
DH-RPC
这部分的文档和示例还没有完全准备好,先简单介绍一下,后面单独写篇文章介绍它。DH-RPC是一套利用DHT替代传统的CA证书,进行去中心化P2P加密通信的RPC框架。
详细介绍可以看这篇文章:https://zhuanlan.zhihu.com/p/43888213
文档和Demo,请移步Github:https://github.com/CovenantSQL/CovenantSQL/tree/develop/rpc
目前CovenantSQL的主要功能大致已经开发了90%,测试网也正在搭建中,可以在Github上关注我们的进展:
https://github.com/CovenantSQL/CovenantSQL
转文至此。
欢迎关注个人微信公众号“一森咖记”
