因为网站比较敏感, 所以具体网站就不说了, 直接说逻辑部分
为了降低数据提取的错误率, 所以使用了python的slimit库对js代码进行提取处理
对网站源码的JavaScript进行分析后, 发现在其中一个script标签内的js代码是利用抽取混淆的, 并用flashvars开头的变量存储
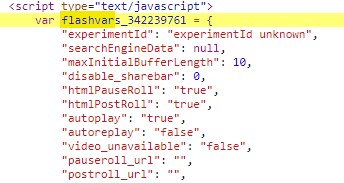
首先用python将该js代码进行提取
response = requests.get(url=url, proxies=proxies)
script = filter(lambda x: 'flashvars' in x, response.html.xpath('//script//text()')).__next__()
将该部分代码格式化后可以看到键名为mediaDefinitions的值是数组, 数组内存储着videoUrl,
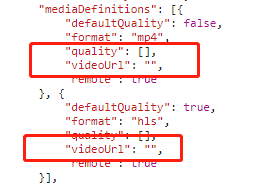
在这里可以看到, 链接是被抽取的进行拼接后即可还原真实地址

下面会使用到python的slimit库的ast进行还原
# 将js代码转成结构树
tree = Parser().parse(script)
通过smlit的Parser类的parse方法, 对js代码转换为ast结构树
获取到结构树后, 需要自定义类, 并继承ASTVisitor, 自定义访问者遍历节点对节点进行抽取
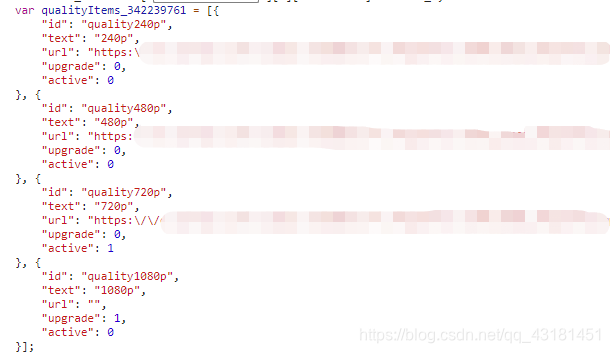
下面代码我先对mediaDefinitions和qualityItems对象进行抽取还原
class VarStatement_Visitor(ASTVisitor):
# 自定义访问者,重写VarStatement节点访问逻辑
def visit_VarStatement(self, node):
Identifier, Object = node.children()[0].children()
# 获取flashvars的节点
if 'flashvars' in Identifier.value:
for i in Object.properties:
left, right = i.children()
# mediaDefinitions数组
if left.value == '"mediaDefinitions"':
# 还原字典
for item in right.items:
media_data = dict()
for medias in item.properties:
media_left, media_right = medias.children()
if isinstance(media_right, ast.Array):
data_list = [i.value for i in media_right.items]
media_data[media_left.value[1:-1]] = data_list
else:
if media_left.value == '"defaultQuality"' or media_left.value == '"remote"':
media_data[media_left.value[1:-1]] = media_right.value
else:
media_data[media_left.value[1:-1]] = media_right.value[1:-1]
flashvars.append(media_data)<
版权声明:本文为qq_43181451原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。