一、导入re库
python使用正则表达式要导入re库。
import re在re库中。正则表达式通常被用来检索查找、替换那些符合某个模式(规则)的文本。
二、使用正则表达式步骤
1、寻找规律;
2、使用正则符号表示规律;
3、提取信息,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
三、正则表达式中常见的基本符号
1.点号“.”
一个点号可以代替除了换行符(\n)以外的任何一个字符,包括但不限于英文字母、数字、汉字、英文标点符号和中文标点符号。
2.星号“*”
一个星号可以表示它前面的一个子表达式(普通字符、另一个或几个正则表达式符号)0次到无限次。
3.问号“?”
问号表示它前面的子表达式0次或者1次。注意,这里的问号是英文问号。
4.反斜杠“\”
反斜杠在正则表达式里面不能单独使用,甚至在整个Python里都不能单独使用。反斜杠需要和其他的字符配合使用来把特殊符号变成普通符号,把普通符号变成特殊符号。如:“\n”。
5.数字“\d”
正则表达式里面使用“\d”来表示一位数字。再次强调一下,“\d”虽然是由反斜杠和字母d构成的,但是要把“\d”看成一个正则表达式符号整体。
6.小括号“()”
小括号可以把括号里面的内容提取出来。
四、常见的正则表达式举例
1. .*?(匹配所有内容)
例如:'<title>(.*?)</title>’ 将网页的标题爬取下来。
2、\w 单词字符[A-Za-z0-9_], “+” 匹配前一个字符1次或无限次 例如:一个人的邮箱是这样的lixiaomei@qq.com,那么我们如何从一大堆的字符串把它提取出来呢?
pattern: \w+@\w+\.com
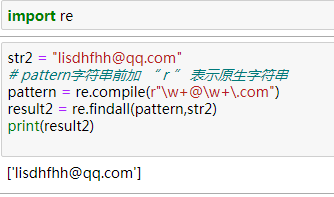
思考:若邮箱为hello123
@heuet.edu.com
,如何匹配?
pattern:\w+@(\w+\.)?\w+\.com?代表了匹配0次或者1次括号分组内的匹配内容,”()”则表示被括内容是一个分组,分组序号从pattern字符串起始往后依次排列。因为是匹配0次或1次,那么就意味着括号内的部分是可有可无的,所以这个pattern就可能匹配以上两种邮箱格式。
扩展: \w+@(\w+\.)*\w+\.com 模式就更厉害了,” * ” 可以匹配0次或无限次。
五、re库的核心函数

1
、compile()函数 (可有可无)
• 函数定义: compile(pattern, flag=0)
• 函数描述:编译正则表达式pattern,然后返回一个正则表达式对象。
为什么要对pattern进行编译呢?
《
Python
核心编程》
里面是这样解释的:
使用预编译的代码对象比直接使用字符串要快,因为解释器在执行字符串形式的代码前都必须把字符串编译成代码对象。
2
、match()函数
• 函数定义: match(pattern, string, flag=0)
• 函数描述:只从字符串的最开始与pattern进行匹配,匹配成功返回匹配对象(只有一个结果),否则返回None。

问题来了,为什么result1结果有这么多的东西啊?貌似最后一个才是要匹配的对象。这个要怎么提取出来呀? 别着急,我们现在得到的是匹配对象,需要用一定的方法提取,后面会在《匹配对象的方法》章节来解决这个问题,继续往下看。
3
、search()函数
-
函数定义:
search
(pattern, string, flag=0)
-
函
数描述:与match()工作的方式一样,但是search()不是从最开始匹配的,而是从任意位置查找第一次匹配的内容。如果所有的字串都没有匹配成功,返回None,否则返回匹配对象。

4
、findall()函数
-
函数定义: findall(pattern, string [,flags])
-
函数描述:查找字符串中所有出现的正则表达式模式,并返回一个匹配列表

上面同时列出了match、search、findall三个函数用法。findall与match和search不同的地方是它会返回一个所有无重复匹配的列表。如果没找到匹配部分,就返回一个空列表。
六、
匹配对象的方法(提取)
以上re模块函数的返回内容可以分为两种:
-
返回匹配对象
:就是上面如
<_sre.SRE_Match object; span=(0, 5), match=’12345′>
这样的对象,可返回匹配对象的函数有
match
、search、finditer
。
-
返回一个匹配的列表
:返回列表的就是
findall
。
因此匹配对象的方法只适用
match
、search、finditer
,而不适用与
findall
。
常用的匹配对象方法有这两个:
group
、groups
、还有几个关于位置的如
start
、end、span
就在代码里描述了。
1
、group方法
-
方法定义:g
roup(num=0)
-
方法描述:返回整个的匹配对象,或者特殊编号的字组

再看下面的实例:

这里就需要用到我们之前提到的
分组
概念。
分组的意义在于:我们不仅仅想得到匹配的整个字符串,我们还想得到整个字符串里面的特定子字符串。
如上例中,整个字符串是
“
我
12345+abcde”
,但是想得到
“abcde”
,我们就可以用
()
括起来。因此,你可以对
pattern
进行任何的分组,提取你想得到的内容。
2
、groups方法
-
方法定义
:
groups(default =None)
-
方法描述
:返回一个含有所有匹配子组的元组,匹配失败则返回空元组

七、re模块的属性(flag)
re
模块的常用属性有以下几个:
-
re.I:
匹配不分大小写;(常用)
-
re.L:
根据使用的本地语言环境通过
\w, \W, \b, \B, \s, \S
实现匹配;
-
re.M:
^
和$分别匹配目标字符串中行的起始和结尾,而不是严格匹配整个字符串本身的起始和结尾;
-
re.S:
“.”(点号)通常匹配除了\n(换行符)之外的所有单个字符,该标记表示“.”(点号)能够匹配全部字符;(常用)
-
re.X:
通过反斜线转义,否则所有空格加上#(以及在该行中所有后续文字)都被忽略,除非在一个字符类中或者允许注释并且提高可读性;


注意:
-
如果我们定义了compile编译,需要先将flag填到compile函数中,否则填到匹配函数中会报错; 如果没有定义compile,则可以直接在匹配函数findall中填写flag。
附录:
正则表达式中语法一览表
